文章图片
样本队列的 Key 编码器使用基于动量更新的编码器 , 对比如果使用和 Query 编码器相同的梯度更新策略 , 可以看出基于动量更新的 Key 编码器更优:

文章图片
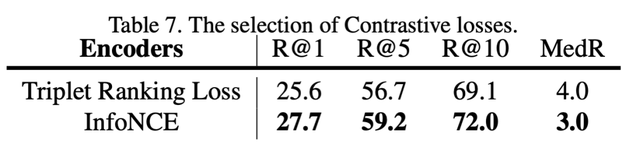
对比匹配中使用 InfoNCE 和 Triplet Loss , 可以看出 InfoNCE 更优:
文章图片
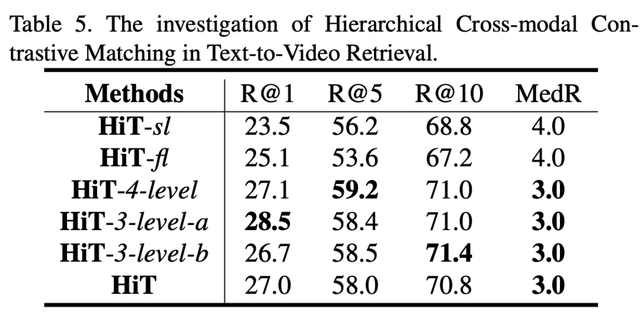
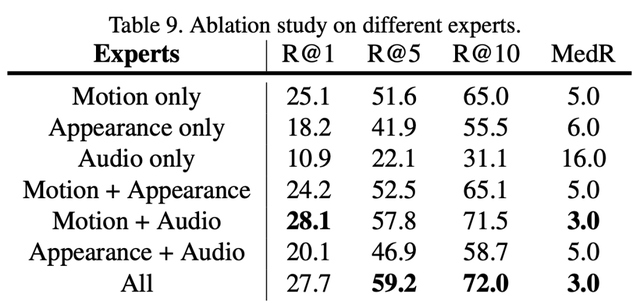
模型的视觉输入使用不同 Expert embedding:
文章图片
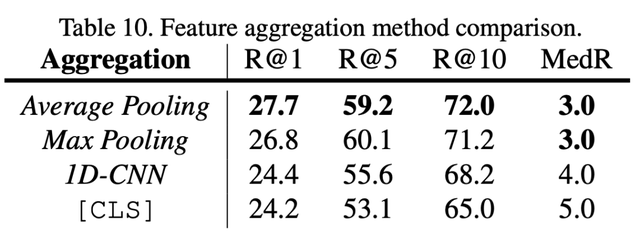
使用不同特征融合方式 , 整体平均池化更优:
文章图片
总结
本文将 MoCo 方法引入到视频文本检索的跨模态对比学习任务中 , 通过构建 MMC 模块既实现视觉和文本编码器的交互拖动更新 , 同时又实现了大规模的负样本对比学习 。 值得一提的是本文通过 HCM 模块探寻了不同层次的特征匹配的效果 , 扩宽了主流方法仅使用单一层次维度进行跨模态对比学习的思路 。
HiT 已应用在快手多个业务场景中 , 通过 HiT 产生的embedding , 提升了多模态模型表征能力 , 对视频检索、图文相关性判断、视频内容理解等模型都带来了效果的提升 , 在视频智能审核、视频冷启动、智能创作等业务场景中发挥重要作用 。
参考文献
[1] Attention Is All You Need
[2] ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
[3] LXMERT: Learning Cross-Modality Encoder Representations from Transformers
[4] VisualBERT: A Simple and Performant Baseline for Vision and Language
[5] Unicoder-VL: A Universal Encoder for Vision and Language by Cross-modal Pre-training
[6] COOT: cooperative hierarchical trans- former for video-text representation learning
[7] T2VLAD: Global-Local Sequence Alignment for Text-Video Retrieval
[8] HiT: Hierarchical Transformer with Momentum Contrast for Video-Text Retrieval
[9] Momentum contrast for unsupervised visual representation learning
推荐阅读







- 最新消息|快手调整员工福利:减少房补、取消免费三餐 新增生育奖金
- 编码|飞利浦发布 Fidelio T1 真无线降噪耳机:圈铁三单元,1699 元起
- 平台|快手:开展“清朗?打击流量造假、黑公关、网络水军”专项行动
- 浏览器|抖音快手去水印在线解析
- 宿华|7年前,快手就注意到视频媒体流在记录和表达上的优势
- 索尼|2021 全球MIPI网络编码控制板首发完美对接索尼fcb-ev9500M摄像头机芯
- 电子商务|辛选回应辛巴起诉快手:只是侵权纠纷 不是真的要“告平台”
- 人物|辛巴起诉快手平台:此前曾吐槽被平台限流、一度账号被封
- 编码|Java on Visual Studio Code的更新 – 2021年11月
- 运营|互联网医疗远未成熟 慢赛道跑不出“快手”