- 提出层次跨模态对比匹配 HCM 。 Transformer 的底层和高层侧重编码不同层次的信息 , 以文本输入和 BERT[10] 模型为例 , 底层 Transformer 侧重于编码相对简单的基本语法信息 , 而高层 Transformer 则侧重于编码相对复杂的高级语义信息 。 因此使用 HCM 进行多次对比匹配 , 可以利用 Transformer 这一层次特性 , 从而得到更好的视频文本检索性能;
- 引入 MoCo 的动量更新机制到跨模态对比匹配中 , 提出动量跨模态对比 MCC 。 MCC 为文本信息和视觉信息分别维护了一个容量很大并且表征一致的负样本队列 , 从而克服端到端训练方法受到显存容量的限制 , 只能在一个相对较小的 batch 内寻找负样本这一缺点 , 利用更多的负例 , 从而得到更好的视频和文本表征 。
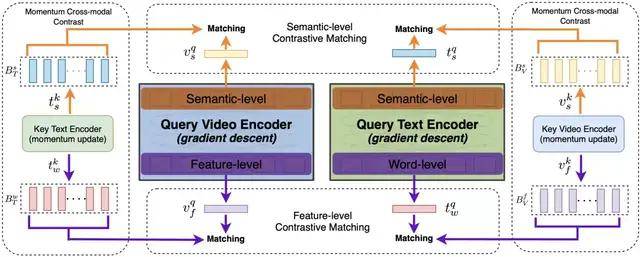
HiT 模型整体流程如图所示 。 输入视频经过视频编码器 , 输入文本经过文本编码器 , 然后在 2 种网络层级(特征底层、语义高层)上分别使用 2 种检索方式(文本检索视频、视频检索文本)共完成 4 次跨模态对比匹配 。 其中编码器都是基于 Transformer 结构 , 4 次跨模态对比匹配均使用上文提到的 MCC , 构建了 4 个负样本队列和对应基于动量更新的 Key 编码器 。
文章图片
编码器
本文提出的 HiT 模型中 , 编码器有视频编码器和文本编码器两种 , 视频编码器采用 4 层 Transformer 结构 , 文本编码器采用 12 层 Transformer 结构 。 模型的视觉输入包括视觉特征Embedding、视觉Segment Mask、Position Embedding和Expert Embedding 。 抽取视频编码器的第一层输出作为视频低层特征 , 最后一层的输出作为视频高层特征 。 后文有实验对比选取不同的网络层输出对最终结果的影响 。
动量跨模态对比(MCC)
现有的端到端多模态学习方法受到显存容量的限制 , 在参数更新的过程中 , 只能在当前 batch 内选取很少的负样本进行交互 , 如果能在这一过程中加入更多的负样本参与计算 , 对模型得到更好的视频和文本表征是有帮助的 。 因此 , 本文引入 MoCo 的动量更新机制到 HiT 模型中 。
以特征层的对比匹配为例 , 如下图所示 , 对视频和文本分别构建负样本队列 , 对应图中的 Memory Bank , Memory Bank 中存储的表征来自于 Key 编码器 。 在特征层共进行了两次对比匹配:(1)文本 Query 编码器与视觉 Memory Bank 对比匹配(2)视觉 Query 编码器与文本 Memory Bank 对比匹配 。 在参数更新的过程中 , Query 编码器的参数通过梯度下降更新 , 文本 Key 编码器的参数基于文本 Query 编码器的参数进行动量更新 , 视觉 Key 编码器的参数基于视觉 Query 编码器的参数进行动量更新 。
推荐阅读







- 最新消息|快手调整员工福利:减少房补、取消免费三餐 新增生育奖金
- 编码|飞利浦发布 Fidelio T1 真无线降噪耳机:圈铁三单元,1699 元起
- 平台|快手:开展“清朗?打击流量造假、黑公关、网络水军”专项行动
- 浏览器|抖音快手去水印在线解析
- 宿华|7年前,快手就注意到视频媒体流在记录和表达上的优势
- 索尼|2021 全球MIPI网络编码控制板首发完美对接索尼fcb-ev9500M摄像头机芯
- 电子商务|辛选回应辛巴起诉快手:只是侵权纠纷 不是真的要“告平台”
- 人物|辛巴起诉快手平台:此前曾吐槽被平台限流、一度账号被封
- 编码|Java on Visual Studio Code的更新 – 2021年11月
- 运营|互联网医疗远未成熟 慢赛道跑不出“快手”