join|ClickHouse vs StarRocks选型对比( 二 )
不同于以点查为主的TP业务 , 在AP业务中 , 事实表和维度表的关联操作不可避免 。 ClickHouse与StarRocks最大的区别就在于对于join的处理上 。 ClickHouse虽然提供了join的语义 , 但使用上对大表关联的能力支撑较弱 , 复杂的关联查询经常会引起OOM 。 一般我们可以考虑在ETL的过程中就将事实表与维度表打平成宽表 , 避免在ClickHouse中进行复杂的查询 。
目前有很多业务使用宽表来解决多远分析的问题 , 说明了宽表确有其独到之处:
·在ETL的过程中处理好宽表的字段 , 分析师无需关心底层的逻辑就可以实现数据的分析
·宽表能够包含更多的业务数据 , 看起来更直观一些
·宽表相当于单表查询 , 避免了多表之间的数据关联 , 性能更好
但同时 , 宽表在灵活性上也带来了一些困扰:
·宽表中的数据可能会因为join的过程中存在一对多的情况造成错误数据冗余
·宽表的结构维护麻烦 , 遇到维度数据变更的情况需要重跑宽表
·宽表需要根据业务预先定义 , 宽表可能无法满足临时新增的查询业务
StarRocks:通过星型模型适应维度变更
可以说 , 拼宽表的形式是以牺牲灵活性为代价 , 将join的操作前置 , 来加速业务的查询 。 但在一些灵活度要求较高的场景 , 比如订单的状态需要频繁改变 , 或者说业务人员的自助BI分析 , 宽表往往无法满足我们的需求 。 此时我们还需要使用更为灵活的星型或者雪花模型进行建模 。 对于星型/雪花模型的兼容度上 , StarRocks的支撑要比ClickHouse好很多 。
在StarRocks中提供了三种不同类型的join:
·当小表与大表关联时 , 可以使用boardcast join , 小表会以广播的形式加载到不同节点的内存中
·当大表与大表关联式 , 可以使用shuffle join , 两张表值相同的数据会shuffle到相同的机器上
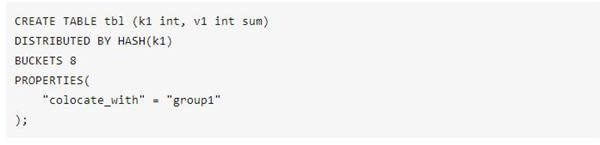
·为了避免shuffle带来的网络与I/O的开销 , 也可以在创建表示就将需要关联的数据存储在同一个colocation group中 , 使用colocation join
文章图片
【join|ClickHouse vs StarRocks选型对比】目前大部分的MPP架构计算引擎 , 都采用基于规则的优化器(RBO) 。 为了更好的选择join的类型 , StarRocks提供了基于代价的优化器(CBO) 。 用户在开发业务SQL的时候 , 不需要考虑驱动表与被驱动表的顺序 , 也不需要考虑应该使用哪一种join的类型 , CBO会基于采集到的表的metric , 自动的进行查询重写 , 优化join的顺序与类型 。
高并发支撑
ClickHouse对高并发的支撑
为了更深维度的挖掘数据的价值 , 就需要引入更多的分析师从不同的维度进行数据勘察 。 更多的使用者同时也带来了更高的QPS要求 。 对于互联网 , 金融等行业 , 几万员工 , 几十万员工很常见 , 高峰时期并发量在几千也并不少见 。 随着互联网化和场景化的趋势 , 业务逐渐向以用户为中心转型 , 分析的重点也从原有的宏观分析变成了用户维度的细粒度分析 。 传统的MPP数据库由于所有的节点都要参与运算 , 所以一个集群的并发能力与一个节点的并发能力相差无几 。 如果一定要提高并发量 , 可以考虑增加副本数的方式 , 但同时也增加了RPC的交互 , 对性能和物理成本的影响巨大 。
推荐阅读







- 产品|采用njoinic英集芯IP5303的移动电源IC,威麦科技麦克风开箱拆解报告
- Meetup|“初雪”与“向量化”| StarRocks Hacker Meetup小记
- 平台|StarRocks VS ClickHouse,携程大住宿智能数据平台的应用
- user_id|滴滴 x StarRocks:极速多维分析创造更大的业务价值
- joins|PostgreSQL 12.2 公开课及视频及PGCP认证(第9期)(CUUG)(2020年)
- 分析|唯品会翻牌ClickHouse后,实现百亿级数据自助分析