下图为 data-30 空间中最终奖励排名前 2 的超参数和随机 8 个超参数的奖励 - 轮次关系:
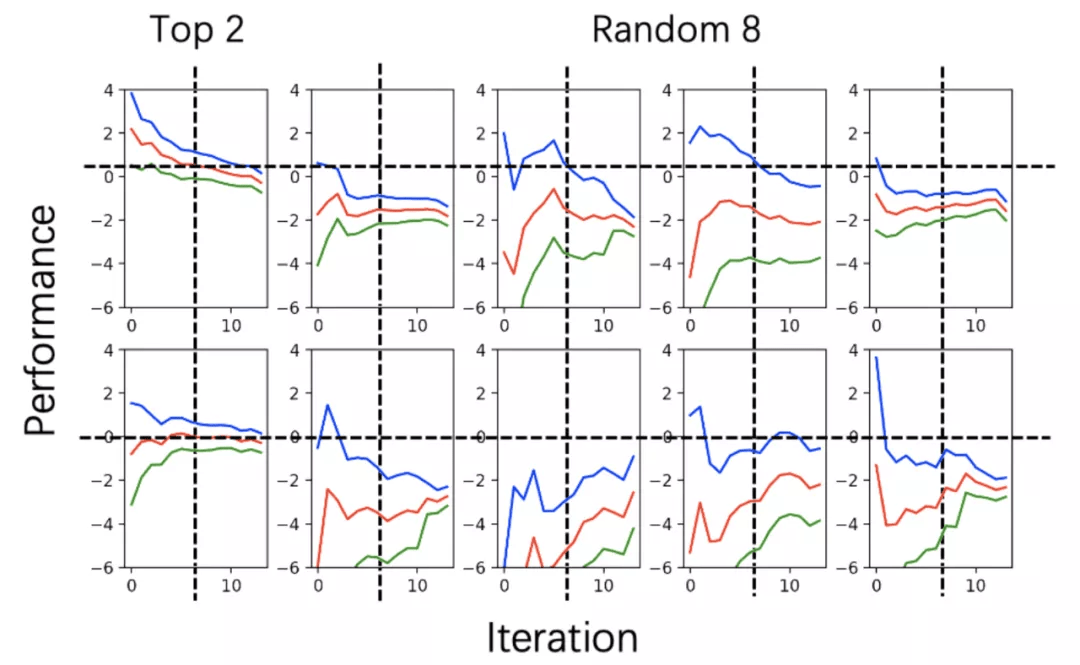
文章图片
图:data-30 搜索空间中 2 个最好配置和 8 个随机配置的奖励 - 轮数曲线 , 包含置信上界(蓝色)、均值(红色)、置信下界(绿色)曲线 。
我们在比赛开源代码仓库中提供了上述 “数据探索” 代码 。
上述数据探索结果表明 , 根据前 13 轮的置信区间 , 我们可以推测第 14 轮奖励均值的位置 。 利用前 13 轮的均值大小关系 , 我们可以估计第 14 轮最终均值的大小关系 , 但是由于数据噪音的存在 , 排名靠前的超参数配置大小关系无法通过部分验证结果预估 。 由此我们设计了两种早停算法 , 分别是基于置信区间的早停和基于排名的早停 , 将在下一部分详细描述 。
过于激进的早停策略在比赛中仍然存在问题 。 如果使用贝叶斯优化只对全量验证数据建模 , 由于总体优化预算时间很少 , 早停会减少可用于建模的数据量 , 使得模型不能得到充分训练 。 为解决这一问题 , 我们引入插值方法 , 增加模型可训练数据 。
基于以上考量 , 最终我们的决赛算法在初赛贝叶斯优化算法的基础上 , 前期执行完整贝叶斯优化使模型得到较为充分的拟合 , 后期使用早停技术与插值法 , 加速超参数验证与搜索过程 。 下面将对早停模块做详细介绍 。
算法核心技术——早停模块介绍
早停方法
由于超参数配置之间的部分验证轮次均值大小关系与最终均值大小关系存在一定的相关性 , 我们受异步多阶段早停算法 ASHA[5]的启发 , 设计了基于排名的早停算法:一个超参数如果到达需要判断早停的轮次 , 就计算其性能均值处于历史中同一轮次的超参数性能均值的排名 , 如果位于前 1/eta , 则继续验证 , 否则执行早停 。
依据 95% 置信区间的含义 , 我们还设计了另一种早停方法 , 即使用置信区间判断当前超参数配置是否仍有验证价值 。 如果某一时刻 , 当前验证超参数的置信区间上界差于已完全验证的性能前 10 名配置的均值 , 则代表至少有 95% 的可能其最终均值差于前 10 名的配置 , 故进行早停 。 使用本地数据验证 , 以空间中前 50 名的配置对前 1000 名的配置使用该方法进行早停 , 早停准确率在 99% 以上 。
经过测试 , 结合贝叶斯优化时两种方法效果近似 , 我们最终选择使用基于排名的早停方法 。 无论是哪种方法 , 都需要设计执行早停的轮次 。 早停越早越激进 , 节省的验证时间越多 , 但是得到的数据置信度越低 , 后续执行插值时训练的模型就越不准确 。 为了权衡早停带来的时间收益和高精度验证带来的数据收益 , 我们选择只在第 7 轮(总共 14 轮)时判断每个配置是否应当早停 。 早停判断准则依据 eta=2 的 ASHA 算法 , 即如果当前配置均值性能处于已验证配置第 7 轮的后 50% , 就进行早停 。
推荐阅读







- 安全|Redline Stealer恶意软件:窃取浏览器中存储的用户凭证
- 吴祖榕|上线 2 周年,用户数破 2 亿,腾讯会议和我们聊了聊背后的产品法则
- 硬件|上线两年用户破两亿,腾讯会议还能做什么?
- 设计|腾讯宣布企业级设计体系 TDesign 对外开源
- 警告!|冒充老干妈员工诈骗腾讯被判12年 两被告提出上诉
- Tencent|继百度网盘后腾讯微云也已解除限速 不用单独下载App
- 文化|“视频会员”的意义,藏在腾讯视频VIP九周年里
- 彩云|解除限速!腾讯微云 App 更新,提供无差别速率服务
- 公司|《Control》开发商正在与腾讯合作开发一款PVE射击网游
- 国计民生|25万亿级新蓝海!百度、华为、腾讯重磅出击,抢食智慧城市"大蛋糕",AI巨头如何赋能?来看真实案例