检测|基于双目视觉的目标检测与追踪方案详解( 七 )
③数据关联
考虑到测量与跟踪的关联性 , 由于要跟踪的特征数量庞大 , 实施复杂的数据关联方法(例如多假设跟踪)肯定是不可行的 , 需要采用不同于传统跟踪方法的跟踪策略 。 新检测不是将特征检测器的输出视为与现有跟踪实体相关联的测量值 , 而是简单地将特征标记为跟踪候选 。 通过使用光流原理主动搜索其对应关系 , 可以找到任何现有特征轨迹的适当测量 。
④聚类
为了从视觉子系统中提取最终测量值 , 在特征轨迹数据上实施了一个聚类程序 。 聚类的目的是识别源自同一环境监测对象的特征轨迹 。 理想情况下 , 要成功地对特征轨迹进行分组 , 应该需要有关数据的最少先验知识 。 例如 , 任何给定扫描中存在的目标数量是一个未知参数 , 应由 DATMO 算法使用各车载传感器数据确定 。 许多流行的聚类算法(例如 k-means 和期望最大化)不适合这种特定应用 , 因为它们对聚类的确切数量的依赖性和敏感性 。 在这个项目中 , 可以选择具有最少先验知识的特征轨迹聚类解决方案是基于密度的噪声应用空间聚类(DBSCAN)算法 。 DBSCAN 识别和分组空间数据集中的密集区域 , 同时还提供异常值标记 。 DBSCAN 只需要两个参数 , 即一个集群可能适用的最小样本数和一个特殊的距离阈值 。
⑤匹配库数据扫描
在 DBSCAN 算法中构成集群的形式化依赖于一些定义 。 首先 , 点 p 的邻域 N(p) 是距离 p 小于或等于 p 的所有点的集合 。 如果点的邻域包含至少最少数量的点 , 则点被标记为核心点 。 核心点 q 的邻域中的任何点 p 都被称为从核心点直接密度可达 。 如果存在一系列点 p1 , 则任何点 p 都是从核心点 q 密度可达的. . , pn, p1 = q, pn = p 使得 pi+1 可直接从 pi 密度可达 。 密度可达条件的对称变体是密度连通的 , 两个点 p 和 q 是密度连通的 , 如果它们存在一个点 o , 那么这两个点都是密度可达的 。 一个簇被定义为所有密度连接的点 , 从集群内的任何点密度可达的点也包括在内 , 而无法到达的点被标记为异常值 。
下图以图形方式显示了不同的可达性定义:
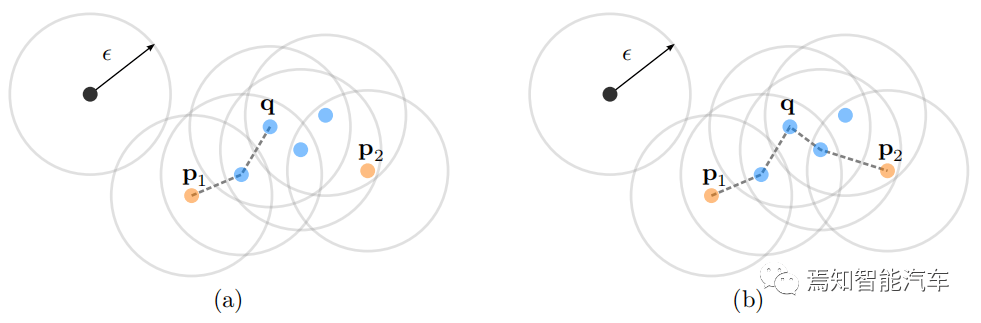
文章图片
最小样本参数等于 4 点的 DBSCAN 可达性说明:上图中蓝色圆圈是核心点 , 因为它们的邻域至少包含最少数量的点 。 图(a)中点 p1 是从 q 密度可达的 , 图(b) 中 p1 和 p2 通过核心点 q 彼此密度连接 , 黑点被标记为异常值 。
DBSCAN 聚类呈现出有利的特征 , 因为它几乎不需要对数据集进行假设 。 不必指定簇的数量 , 可以找到任意形状的簇 。 此外 , 异常值是固有地检测到的 。 该算法的一个缺点是它无法对密度不同的数据集进行聚类 。
推荐阅读







- 天津|“猎鹰号”气膜实验室投用 “人机配合”每日最多检测80万人份(图)
- Google|谷歌为正式员工提供快速居家病毒检测:合同工需线下排队
- 新浪科技|谷歌为正式员工提供快速居家病毒检测:合同工需线下排队
- Linux|Red Hat/Fedora Anaconda正迁移到基于网络的全新UI
- 检测|一张核酸检测报告是这样出炉的!
- 公司|气膜方舱实验室今日投用!日最大核酸检测量120万人份
- 视点·观察|从核酸检测到健康码,为什么系统总是“崩了”?
- 一财网|从核酸检测到健康码,为什么系统总是“崩了”?
- 工业化|RIB出席中欧建筑工业化论坛,基于BIM的智能建造成亮点
- 平台|重庆建立“核酸体外诊断研发”平台 核酸检测10-15分钟可出结果