定义|时间走向二维,基于文本的视频时间定位新方法兼顾速度与精度( 二 )

文章图片
- 论文地址:https://arxiv.org/abs/2012.02646
- 代码地址:https://github.com/microsoft/2D-TAN/tree/ms-2d-tan
文章图片
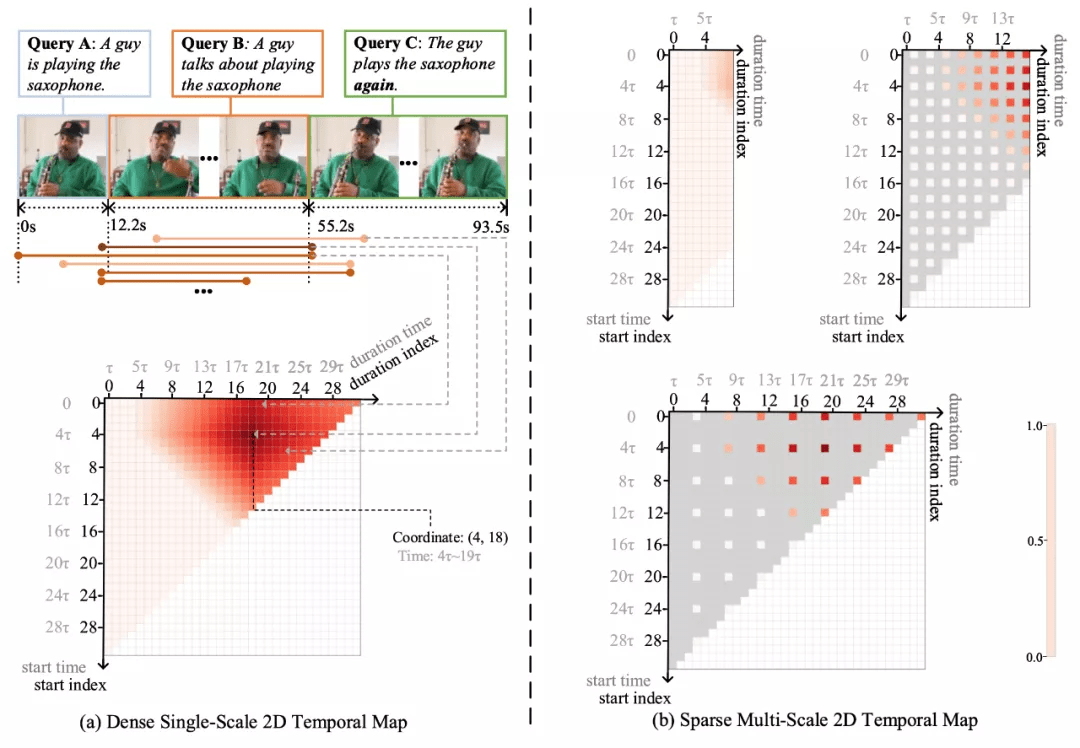
图 1 二维时间图的示意图 。 (a) 表示的是稠密单尺度二维时间图 。 黑色坐标轴分别表示的是开始和时长的标号 , 而灰色坐标轴表示的是与之对应的开始时刻和持续时间 。 二维图中红色的程度表示目标片段和候选片段的匹配程度 。 这里是一个预先定义好的单位时长 。 白色格子表示无效的视频片段 。 (b)表示的是稀疏多尺度二维时间图 。 稀疏多尺度二维时间图由多个二维时间图构成 , 各个二维时间图的单位时长不相同() 。 灰色格子表示有效但非候选的视频片段 。 其他颜色定义同上 。 通过在多个小尺寸图上建模 , 可以减少计算开销 。
下面我们将具体介绍该方法 。
多尺度二维时域邻近网络(MS-2D-TAN)
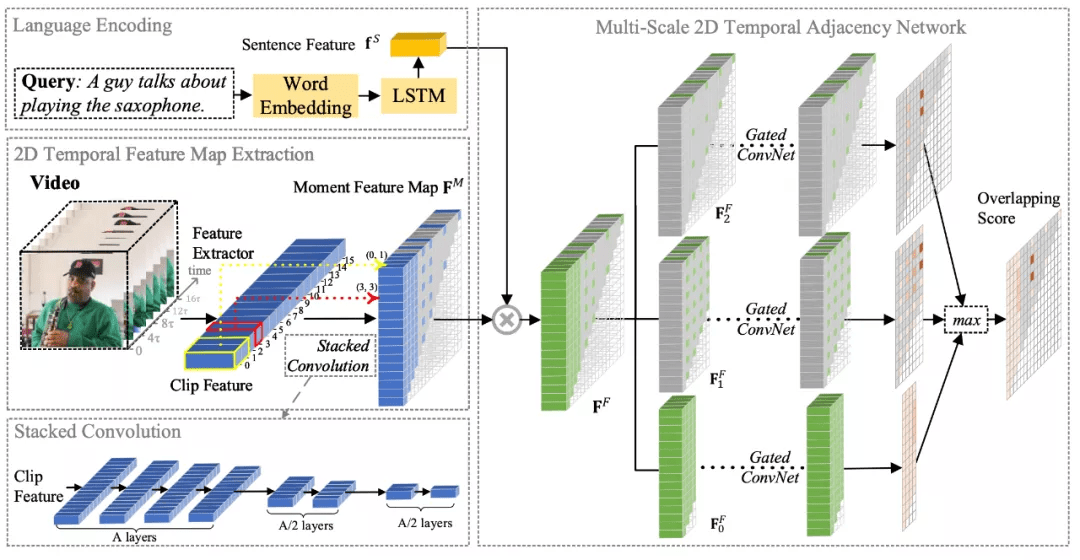
本文提出的模型如图 2 所示 。 该模型由三个模块构成:文本编码模块 , 视频的二维时间特征图模块和多尺度二维时间邻近网络 。 下文将逐一介绍各个模块 。
文章图片
图 2 MS-2D-TAN 的框架示意图 。
语句的文本特征
该研究首先将各个单词用 GloVe 进行编码 , 再输入到 LSTM 中 。 该研究将 LSTM 的输出取平均作为语句的特征向量 。
视频的二维时域特征图
该研究首先将视频分割成N个小的单元片段(clip) , 再通过预训练好的模型将这些片段抽取特征 , 大小是N×d^V 。 候选片段由多个连续的单元片段所构成 , 且长度并不相同 。 为获取统一的片段特征的表示 , 该研究将抽取好的单元片段特征通过叠加卷积的方式获得所有候选片段特征 。 再根据每个候选片段的开始时刻和持续时间 , 将所有的候选片段排列成一个二维特征图 。
当研究人员使用N - 1 个卷积层可获得所有有效片段的特征 。 但当N较大时 , 这样的计算开销也往往较大 。 因此 , 该研究采用了一个稀疏采样的方式 。 如图 2 所示 , 该研究对较短的片段进行密集的采样 , 而对较长的片段进行稀疏采样 。 先用 A 层步长为 1 , 核尺寸为 2 的卷积获得短片段的特征 , 之后每隔 A/2 个卷积层 , 步长增加一倍 , 逐步获得较长片段的特征 。 通过这种方式可以不用枚举出所有的片段 , 从而降低计算开销 。 前者获得的二维特征图我们称之为稠密二维特征图 , 而后者则称之为稀疏二维特征图 。
推荐阅读







- 时间|Alphabet量子公司横空出世!Sandbox将与谷歌、DeepMind成姊妹
- 时间|天津战“疫”:逆境中的光芒
- 新浪科技|无法知道时间的情况下,在岩洞连续生活40天是种怎样的体验?
- 硬件|全志科技:12nm CPU相关产品正处在研发阶段 目前暂无详细时间表
- 重载|「以高质量论英雄」先进轨道交通装备产业链 引领大同制造走向世界
- 时间|折叠屏“一部到位”,荣耀已完成“基因重组”
- Google|谷歌大力游说欧盟 防止《数字市场法案》严重冲击业务
- 新浪数码|海信发布8K AI画质芯片:100%自主研发未来产品自己定义
- 社交|在新冠病例激增的情况下,Meta再次推迟重返办公室的时间
- 手机|荣耀Magic V重新定义折叠屏:首先是一部好用的主力机