错误率|他在京东每天做1000万图灵测试( 二 )
基于其对自然语言理解和语言与视觉多模态信息处理的贡献,2018年底何晓冬当选IEEE Fellow。
此外,他还曾担任IEEE西雅图分会主席及多个顶级学术期刊编委。
在今年清华-中国工程院知识智能联合研究中心推出的AI 2000人工智能全球最具影响力学者榜单中,何晓冬同时入选自然语言处理、语音识别、信息检索与推荐3个领域。在这个榜单里,跨3个及以上领域入选的学者全球只有61位。
二十载学术生涯中,何晓冬的研究贯穿了语音识别、语言理解、图像与语言多模态信息处理等领域。也正好在这一时期,深度学习及人工智能技术迎来新一轮爆发。
深度学习爆发的见证者、参与者正如乔布斯在斯坦福大学那场著名的演讲中所言,人生中很多事件其间存在巧妙关联,但要在多年后回望时才会发现。
这一点在何晓冬身上也有印证。
站在当下这个节点上,何晓冬回望走过的路,何晓冬对我们讲述了自己亲历的深度学习发展中的几个片刻。
关于这个故事,还要从2006年说起。
当年,深度学习三巨头之一Geoffrey Hinton在顶刊Science上发表了一篇论文,名为《Reducing the Dimensionality of Data with Neural Networks》。

文章插图
虽然当时人们认为这篇论文并不好懂,但现在回头来看,这篇论文可以称得上是这次深度学习浪潮的起点。
而彼时何晓冬考虑的,却是另外一个问题:需要什么样的算法才能在像大规模语音识别、机器翻译这类硬核的AI任务上产生真正的突破?
在他看来,很多算法、理论确实够前沿新颖,但当真的用到实际问题中时,效果却差强人意。
之后在2008年的机器学习顶会NeurIPS(当时叫做NIPS)上,他和当时微软的同事邓立便举办了一场语音语言研讨会(NIPS Workshop on Speech and Language: Learning-based Methods and Systems),同时也邀请Hinton来做报告。

文章插图
之后邓立还邀请Hinton去微软“做客”,期望将他提出的最新理论,拓展应用到公认很难的大规模词表语音识别任务中去。
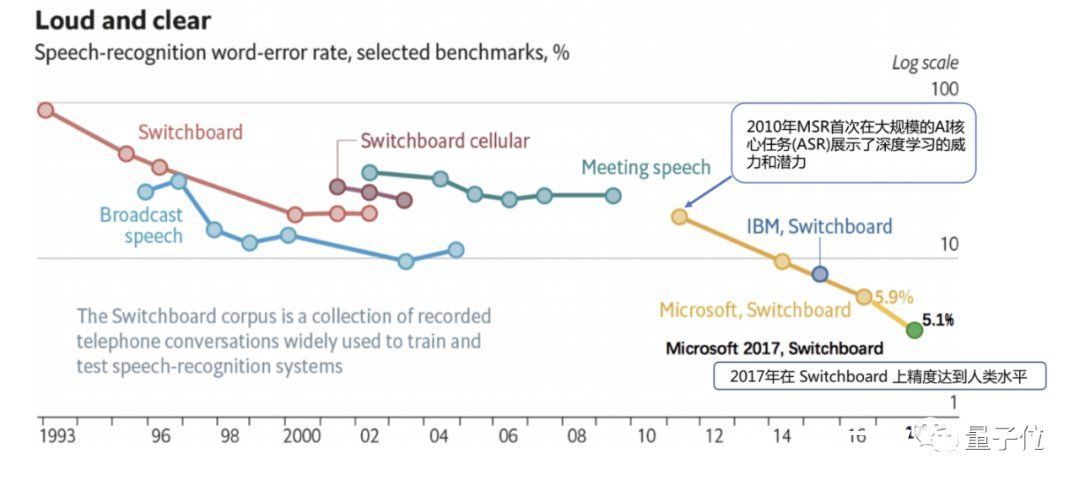
而就是这一次合作,让大规模语音识别这件事在2010年,第一次出现了非常明显的进步。
具体而言,深度学习将大词表语音识别性能突破性提升了20%,可以说是开启了后来一系列人工智能硬核任务上的突破。
以Switchboard数据集上的语音识别性能测试为例,在此之前,基本错误率都高到没法在实际场景中大规模用起来。
而从2010年开始,大词表语音识别的错误率每年都在迅速下降。
文章插图
到了2017年,在Switchboard上的错误率被降低至5.1%,这也是首次在这个数据集上AI达到了人类职业速记员的水平。
但实际上,2010年那次深度学习在语音识别上取得突破的影响,远不止于此。
重点是它让大家对深度学习、神经网络看法发生了改观——
“原来这是条可行的路”。
于是,在这扇大门敞开之际,深度学习领域与之相关的各项研究都开始遍地开花。
比如图像识别方面,以ImageNet项目为例,在2012年Hinton和他的学生研发的深度学习模型将物体识别的错误率降低了1/3。并且随后每一年识别错误率都在持续大幅下降。
在2015年,深度学习模型在ImageNet数据集上把识别错误率降到了3.57%,首次超越了人类的5%错误率的水平。
而且不单是对语音和图像的识别,理想中的AI应该是能像人一样去理解语言背后更深层的语义,就是说AI需要从感知智能进化到认知智能。
推荐阅读







- 美股|热门中概股美股盘前多数下跌,拼多多、京东等跌超2%
- 以旧换新|从创新产品到升级服务 京东电器年货节以“后背”担当谱写守护篇章
- 渠道|发力折叠屏 进军全渠道 京东与三星强化2022年战略合作
- 京东|京东:与三星签署2022年战略合作协议
- 指数|恒生科技指数跌超1%,京东、B站跌超3%
- 银行信用卡|京东白条升级为“白条卡”只是“业务落地”?背后的业务逻辑究竟是什么?
- 年货节|京东拼多多忙撒钱、阿里拼售后,电商巨头“春节大战”硝烟渐浓
- 京东|年终奖怎么用?来京东升级生产力工具呗~
- 恒生科技|恒生科技指数涨幅扩大至5%,京东集团涨超10%
- 快递员|刘强东凌晨发内部信京东物流去年亏28亿,有些快递员月薪8万