错误率|他在京东每天做1000万图灵测试( 三 )
在此理念之下,何晓冬等人投身其中,探索从自然语言中提取出抽象的语义并将它投影到一个语义空间,以此来帮助搜索、推荐、分类、问答等实际应用。
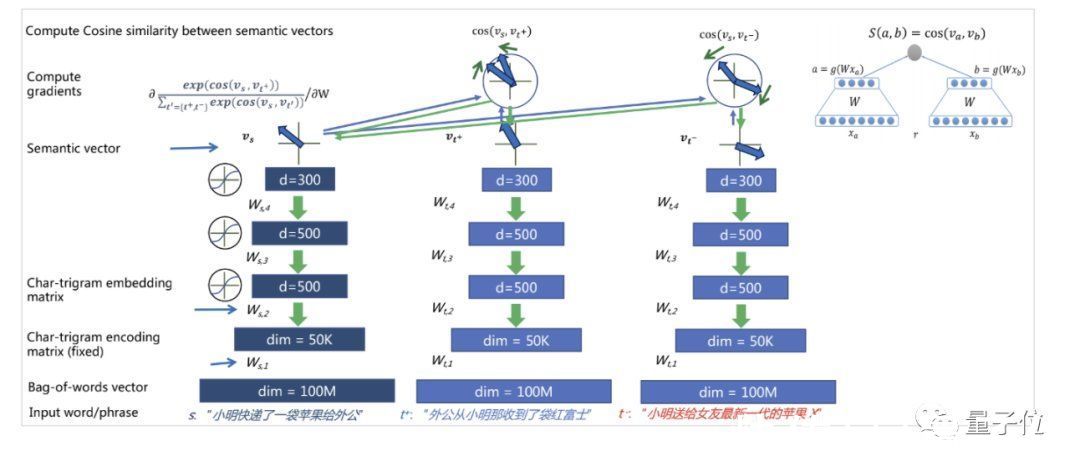
具体而言,他们在2013年提出了深度结构化语义模型DSSM(Deep Structured Semantic Models),将多样化的自然语言所表达的含义,表示成为一个多维度连续语义空间中的向量。
文章插图
值得一提的是,该模型产生的影响可谓深远,不仅仅在学术界被引用过千次,在工业界也极具适应性。
时至今日,几乎所有做搜索推荐场景的大厂仍在使用DSSM及其衍生模型,其影响力度可见一斑。
除了语言之外,在2015年的一个工作中,他们将知识也用向量、矩阵等方式来表征并投影到高维连续语义空间中。
更进一步,语音、语义或图像上的突破还只是单一领域的智能,而人类的智能更为复杂丰富。
比如就像我们人类看下面这张图一样,很自然就能够get到图片中人物的活动,并用语言去描述出来,而不只是简单的检测出图中的人和物。

文章插图
同样在2015年,在CVPR(计算机视觉顶会)上深度学习巨头Yan LeCun 等人召集了一场深度视觉研讨会(DeepVision Workshop),邀请Yoshua Bengio等就“视觉的未来”各抒己见。

文章插图
会上,何晓冬在报告中提出了一个观点,便是语言-视觉深度多模态语义模型(DMSM),也就是AI在描述一张图的时候,是否能够在语义层面上达到一个等价的匹配。
换句话说,就是我们常说的“看图说话”,文字描述出来的话和图片的内容在语义上要是一致的。
而何晓冬他们提出的DMSM模型就是一个具体实现的算法,能够把图像和文字都表示成为同一个跨模态语义空间内的向量。
而后在这个空间中进行跨模态语义匹配计算,从而帮助生成最匹配图像内容的文字表述。
例如在这个模型下,AI在看到下面的这张图片时,便可在识别和理解图像蕴含的丰富语义,并生成准确的语言描述。

文章插图
△何晓冬等在CVPR2015发表的关于视觉和语言多模态图像描述的论文
而且不仅只是语言、图像,何晓冬和他的同事后来又将知识融入到了多模态模型中。
这样做的效果,便是AI在“看”到有具体人物、地标的图片时,就不仅仅会将其描述为“一个运动员”这样的笼统的信息。
而是会把描述的语言变得更加细致,例如AI就会把图片中的具体人物“纳德拉”都说出来。
2016年,微软CEO纳德拉在微软Build大会中便展示了这项技术。
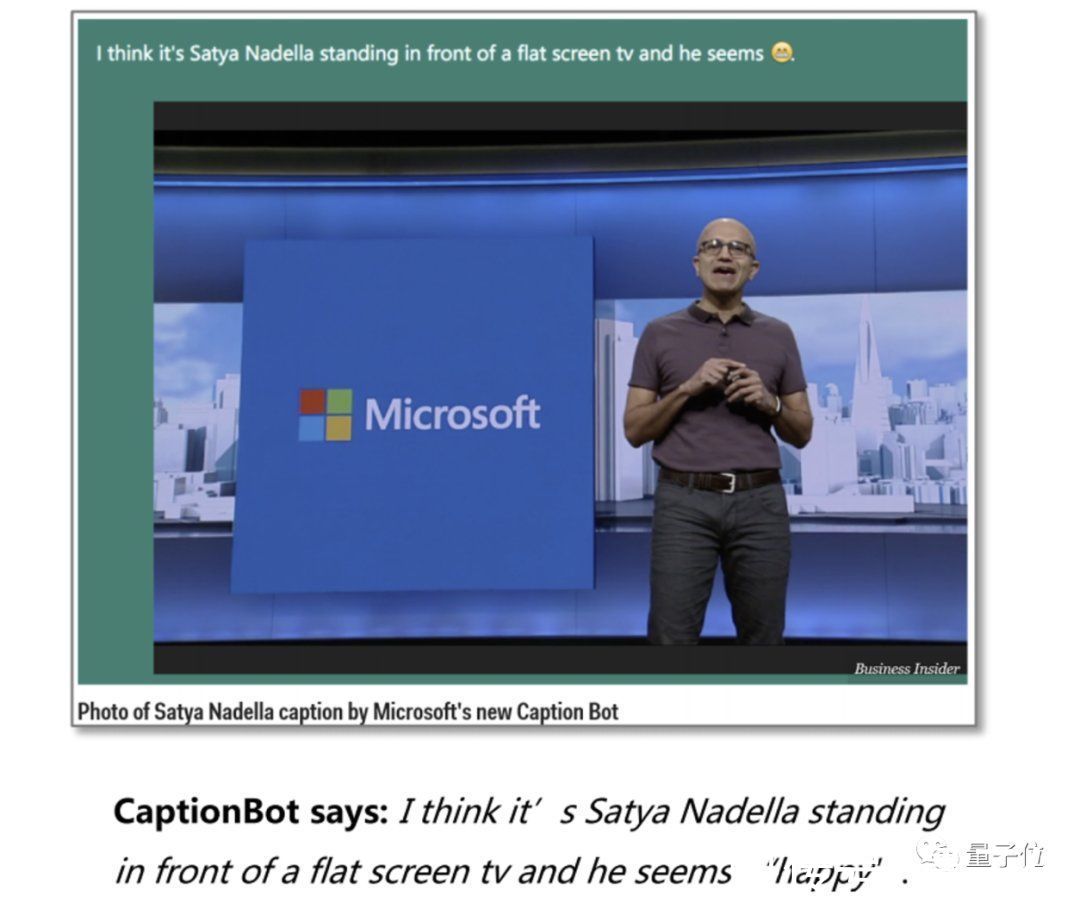
文章插图
△Business Insider媒体报道CaptionBot
何晓冬带领团队开发的这款名为CaptionBot的AI 应用,精准描述了图片中纳德拉的言行举止,还能够描述人物情绪。
一时间,跨语言、视觉以及知识的多模态技术迅速实用化,该应用也迅速走进了大众的视野当中。
深度学习崛起和发展过程中有种种“巧合”,但其实更有赖于很多技术人对技术执著的 “信念”。何晓冬自嘲说,感觉他就像电影《阿甘正传》里的阿甘一样,很幸运的见证了这一轮AI复兴浪潮的关键节点,还有幸能在其中做了一点贡献,也像是经历了一个技术人的“奇幻之旅。”
回国,加盟京东时间拨转到2018年,彼时在微软雷蒙德研究院已经工作十余载的何晓冬,选择回到国内,并加盟京东。
推荐阅读







- 美股|热门中概股美股盘前多数下跌,拼多多、京东等跌超2%
- 以旧换新|从创新产品到升级服务 京东电器年货节以“后背”担当谱写守护篇章
- 渠道|发力折叠屏 进军全渠道 京东与三星强化2022年战略合作
- 京东|京东:与三星签署2022年战略合作协议
- 指数|恒生科技指数跌超1%,京东、B站跌超3%
- 银行信用卡|京东白条升级为“白条卡”只是“业务落地”?背后的业务逻辑究竟是什么?
- 年货节|京东拼多多忙撒钱、阿里拼售后,电商巨头“春节大战”硝烟渐浓
- 京东|年终奖怎么用?来京东升级生产力工具呗~
- 恒生科技|恒生科技指数涨幅扩大至5%,京东集团涨超10%
- 快递员|刘强东凌晨发内部信京东物流去年亏28亿,有些快递员月薪8万