AI|算法的进化:机器会引发战争吗?
现代算法是可以自学的 , 尤其是推荐系统算法 , 它可以根据每个人的喜好推荐有趣的东西给我们 , 比如说适合的电影、书籍、音乐等等 。算法通过与用户之间的交互过程 , 获取用户的个人偏好信息 , 并从中学习进一步完善自身 , 发现其中的关联关系 , 以便为下一位用户提供更优质的推荐信息 。
为了满足自己的好奇心 , 我研究了其中一种算法 , 想知道它到底能有多了解我 。所以 , 在剑桥微软实验室测试Xbox游戏机所用的Kinect视觉识别算法时 , 我顺便拜访了一位同事 , 想向他了解一个实时推荐系统的算法原理 。
该推荐系统的用户界面上随机排列了约200部影片 , 我要做的是如果看到自己喜欢的影片 , 就把它拖放到屏幕的右侧 。其中的确有一些是我比较喜欢的影片 , 于是 , 屏幕中的影片位置自动调整 , 将我可能喜欢的电影放到靠右侧的位置 , 而将我可能不太喜欢的电影放到靠左侧的位置 。仅仅通过一部电影是不足以训练算法的 , 所以大部分尚未被分类的影片仍然停留在屏幕中间的区域 。
《王牌大贱谍》这部影片我觉得很无聊 , 属于我特别不喜欢的类型 , 所以我就把它拖到了屏幕左侧的回收站里 。这一操作为算法提供了进一步学习所需的新信息 , 使屏幕中影片的位置又进行了一次调整 , 我似乎能感觉到算法对自己提供的建议很有信心:它将伍迪·艾伦(Woody Allen)的《曼哈顿》推荐为我喜欢的电影 。这部影片确实是我喜欢的 , 尽管算法是对的 , 但此时它还没有给我特别多的惊喜 。它可能觉得我会比较喜欢《摇滚万岁》 , 所以将这部电影向右侧移动了 。但事实恰好相反 , 我不能忍受这部影片 , 所以我把它拖到了回收站里 。
算法本来以为我会喜欢《摇滚万岁》 , 但事实上我不喜欢 , 从这个过程中它获取到了重要的新信息 。屏幕上的影片又一次进行了重新排列 , 并且此次调整的幅度非常大 。这是因为系统后台的算法程序发生了微妙的改变—它根据我此次的选择学到了更多的“新知识” , 并微调了推荐系统的模型参数 。它判断我可能喜欢《摇滚万岁》这部影片的概率过高 , 所以通过修正特定的参数来降低其值 。虽然此前它从别的既喜欢韦斯·安德森又喜欢《曼哈顿》的那部分影迷处得知 , 他们也喜欢《摇滚万岁》这部电影 , 但这一条并不适用于我 。
正是这种人机交互给算法提供了持续学习的新数据 , 使它可以不断进行自我调整以适配我们的喜好 。在当今社会 , 这些算法在我们做出各种抉择时发挥了巨大作用:选择电影、音乐、书籍 , 甚至伴侣 , 等等 。
文章图片
如果你喜欢……
电影推荐系统的算法原理比较简单 。假定你喜欢电影A、B和C , 而另一个用户也喜欢它们 , 但他还喜欢电影D , 那么 , D极有可能也是你所喜欢的 。当然 , 现实中数据之间的逻辑关系并非如此简单 。你喜欢电影A、B和C是因为这些影片里有你最喜欢的某位演员 , 但他并没有出演D这部电影 。而另一个用户之所以喜欢A、B、C、D四部电影 , 是因为它们都是惊险刺激的间谍电影 。
算法通过查看你所提供的信息 , 分析出你喜欢某类电影的原因 , 进而会把你和那些曾经做出过相同选择的人匹配、关联到一起 。算法需要在大量的初始数据样本基础上展开工作 , 这一点跟许多机器学习算法是相同的 。机器学习的一个重要特点是 , 人类必须参与到数据的分类过程中 , 以便让机器知道它所看到的到底是什么 。这种管理数据的行为为算法提取潜在信息的模式做好了提前准备 。
算法在用户浏览影片库的行为过程中拾取关键特征值 , 如浪漫爱情喜剧、科幻片 , 或者是某位演员、某位导演的作品 。但是 , 这种方法并不理想 。首先 , 非常耗时;其次 , 分类的过程存在不客观因素 , 计算机最终学会的是已知的知识 , 而不能发现新的潜在趋势 , 从而导致计算机形成拟人态的思维定式 。从最原始的数据中学习并发现模式是训练算法最好的方式 。
大家都知道 , Netflix公司是一家会员订阅制的流媒体播放平台 , 开发出自己的电影推荐系统后 , 在2006年举办了奈飞大奖赛 , 期望通过竞争来发掘最优的算法 。当时 , Netflix已经积累了大量的电影评级数据 , 评分等级分为1~5星 。于是 , 它公开了一个包含100 480 507个元素的电影评级训练集合 , 这些元素取自480 189个用户对17 770部电影的评价 。然后 , Netflix将17 770部电影的名称替换为数字序号 , 即变为匿名状态 。比如 , 2666代表的可能是《银翼杀手》 , 也可能是《安妮·霍尔》 , 或其他任何一部影片 。只有用户给这部电影的评分是已知的 。
同时 , Netflix还公布了一个包含2 817 131个元素的测试集合 。测试集合的用户对电影所做的评价是未知的 , 因此参赛队提交的算法必须预测测试集合中所有的元素所对应的评价等级 。比如 , 根据已有的数据预测出用户234654对2666这部影片的评价等级 。重赏之下必有勇夫 , 公司宣布设立100万美元奖金作为奖励 , 获奖条件是:以推荐效率提高10%的优势击败Netflix的自有算法 。附加条件是:获胜者必须公开自己的算法并授予公司非排他性的许可 , 让Netflix有权使用这个算法向用户推荐电影 。
除了100万美元的终极奖项 , 大赛还设立了几个进步奖:将上一年度成绩最好的推荐算法的效率提高至少1%的团队 , 将获得进步奖50 000美元 。该奖项每年度都会有 , 但领取奖金的前提条件依然是需要公开算法的代码 。
可能你会觉得从这样的数据里得不到有价值的信息 , 因为你甚至不知道2666所代表的影片是喜剧片还是科幻片 。事实上 , 原始数据所蕴含的信息远比我们想象的要多 。假设我们将每部电影视为一个维度 , 所有影片就构成了一个17 770维度的空间 , 那么每个用户就可以被看作这个17 770维空间中的一个点 。每一部电影对应一个维度 , 用户对影片的评价越高 , 那么在该维度上此点偏离原点的距离就越远 。当然 , 除非你是一个数学家 , 不然把用户看作17 770维空间中的点是很难想象的 。实际上 , 我们可以把高维空间看作三维空间的扩展 。假定只有3部影片被评级 , 我们可以用图形化的方式将用户与影片评级的关系表示出来 。
假设电影1是《狮子王》 , 电影2是《闪灵》 , 电影3是《曼哈顿》 。某一用户对这三部影片的评级分别为1星、4星和5星 。用x、y、z轴表示用户对电影1、电影2、电影3的喜爱等级 , 建立三维空间直角坐标系 , 如图6-1所示 。这时 , 我们可以确定该用户在坐标系中的位置是(1 , 4 , 5) 。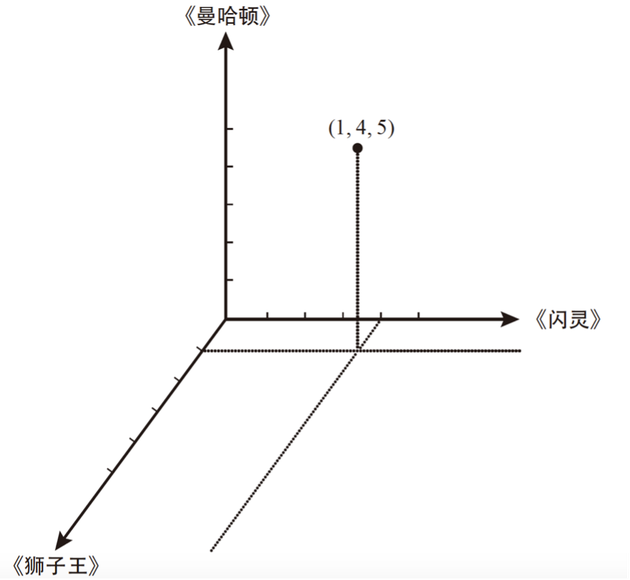
文章图片
图 6-1
虽然在几何上无法绘制出17 770维空间以呈现用户在该空间上的所在位置 , 但数学可以 。如果能把用户看成17 770维空间中的点 , 那么同样能把影片看作480 189维(用户数)空间中的点 , 此时 , 如果用户对影片评价越高 , 那么在该维度上此点偏离原点就越远 。这些点分散在如此之大的维度中 , 很难发现其间存在的模式 。因此 , 如果希望借助计算机找出数据中包含的信息 , 那么就需要降维处理 。
这就好比一系列从不同角度得到的某人的头部剪影 , 其中一些更具代表性 , 更容易辨识一样 。比如 , 希区柯克(Hitchcock)的侧影轮廓就比正面投影更易辨认 。电影和用户就像脸上一个一个的点 , 以一个角度投影 , 可能会看到这些点连成一条线 , 而以另外的一个角度投影 , 则可能并不会发现有明显的信息出现 。
按照这个思路 , 我们或许能找到一种办法 , 将高维空间中的电影和用户对应的点同时投射到一个二维平面上 , 这样用户对应的点就会非常接近他喜爱的电影所对应的点 。这种办法的巧妙之处就在于 , 能够寻找到揭示影片、用户所具有的潜在特征的合适投影 。例如 , 图6-2是100个用户和500部电影匹配过后在二维平面中的投影 , 所使用的数据均来自Netflix的数据库 。代表用户的点与代表影片的点很好地拟合 , 其余各处均未出现异常多余的点 。我们可以通过这个投影找到数据中的信息 。
通过比对点和其实际代表的电影 , 我们可以发现这个投影很好地反映出影片固有的一些特征:剧情片聚集在右上角 , 动作片聚集在左下角 。
这就是最终在2009年赢得Netflix100万美元大奖的团队所使用的算法的基本思想 。他们提取了有助于预测用户喜好的20个电影的独立特征 , 并将高维空间投射到这20个特征所构建的20维空间中 。然后 , 借助计算机强大的运算能力 , 从海量的投影方案中挑选出最好的那一个 。这正是计算机的强大之处 , 它的这种能力是人类的大脑和眼睛所无法企及的 。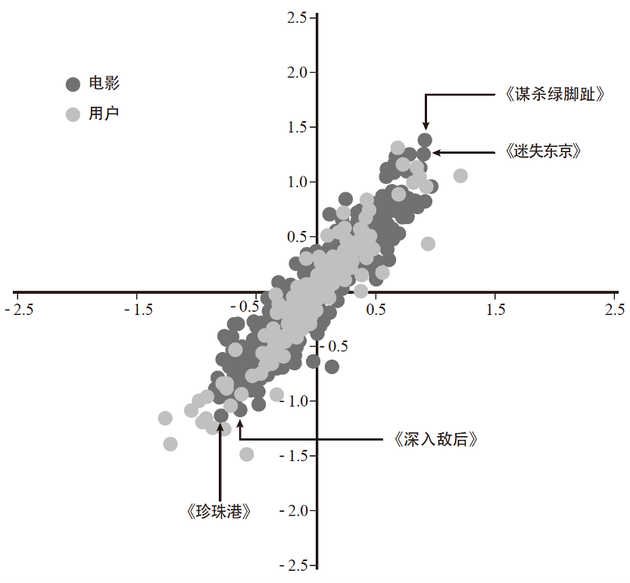
文章图片
图 6-2
更有趣的是 , 模型挑选出的一些特征可以被明显地辨识出来 , 例如“动作片”或“剧情片” , 而另一些特征虽没有明显的标识 , 但也都呈现出一种正态分布的趋向 。
这正是我觉得计算机算法能给人惊喜的地方:它们有发掘新事物的潜力 。从某种角度讲 , 深度学习算法提取出了人类无法用语言描述和表达的特征信息 。就好比在没有建立颜色的概念 , 也没有红色或蓝色这种表示颜色的词汇的情况下 , 仅仅通过我们对所见事物表现出的好恶 , 计算机就能帮我们实现蓝色和红色的分类 。因为存在太多的因素影响着我们的决定 , 我们无法准确地描述出为什么喜欢某部电影 。决定个人偏好的人类代码遵循什么样的算法原理是隐性的 , 但计算机代码已经识别出了引导我们偏好的特征 , 而这些特征我们仅可凭直觉感知 , 却无法表达出来 。计算机代码在这一点上已经遥遥领先于人类了 。
2009年6月 , BellKor抯 Pragmatic Chaos团队向Netflix提交了他们研发的推荐算法 , 其推荐效率首次突破10%的要求并且达到了10.05% 。按照比赛规则 , Netflix宣布这场历时3年之久的比赛进入最后30天的决赛阶段 。决赛阶段涉及的隐藏数据被分为两部分 , 一部分用来在公开测试中给每个团队打分 , 另一部分用来在隐藏测试中评判最后的赢家 。如果没有其他队伍提交的算法超越BellKor抯 Pragmatic Chaos团队 , 那么他们无疑就是这场比赛的赢家 。但是 , 就在决赛第29天的时候 , Ensemble团队提交了他们的算法 , 其推荐效率达到了10.09% , 超过了BellKor抯 Pragmatic Chaos团队 , 位居公开测试排行榜的第一位 。第二天 , 截至停止征集新算法的那一刻 , 两队的算法推荐效率又有了一些新的提升:BellKor抯 Pragmatic Chaos团队突破10.09% , Ensemble团队则非常接近于10.1% 。但该结果并不能说明两队孰胜孰负 , 因此Netflix决定将大奖颁发给在隐藏测试中获胜的团队 。可结果是两队的得分仍然相同 , 但由于BellKor抯 Pragmatic Chaos团队比Ensemble团队早20分钟提交了他们的参赛算法 , 最终是他们带走了那100万美元 。
文章图片
鉴于第一次比赛的成功 , Netflix希望能举办第二次比赛以激发更多的创新性想法 , 但是它遇到了一个难题:用户的个人隐私问题 。公司曾在竞赛网站的页面上发出这样的公告:
训练数据集合删除了所有的用户识别信息 , 只剩下评级等级和日期 。这符合隐私权保护政策 。即便知道自己所有的评级及日期 , 你也可能无法在数据中准确地识别它们 , 因为它们只是极小的一部分样本(总量不超过完整数据集的1/10) , 并且这些数据曾受到扰动 。
那么 , 如果参赛选手知道用户所有的评级 , 这真的不算侵犯隐私吗?
得克萨斯大学奥斯汀分校的两名研究人员收集了这些数据 , 并将其与另一个网站—互联网电影数据库(Internet Movie Database , 简称IMDb)上对电影进行评级的那些用户进行了比较 , 识别出了其中几名用户的身份 。2009年12月17日 , 四名用户对Netflix提起诉讼 , 称该公司发布数据违反了《视频隐私保护法案》 。其中一名用户表示 , 她是一个未出柜的同性恋母亲 , 有关她对电影喜好的数据可能会暴露出她的性取向 。分析用户对电影的特殊喜好就有可能推断出其政治倾向或性取向 , 这被称为“《断背山》因子” 。最终 , 此案庭外和解 , Netflix也因此取消了举办第二场比赛的计划 。
数据像是一种新型“石油” , 而我们却把它“倒”在互联网上了 。谁拥有这些数据以及如何利用好这些数据 , 将是我们走向由这种新型“石油”推动的未来时 , 社会将要面临的一个重大问题 。
文章图片
如何训练算法
如果算法告诉你你可能会喜欢什么 , 那么就意味着你将永远都看不到算法认为你不喜欢的东西 。知道了这一点 , 你是否感到一点隐隐的不安?对我来说 , 我很享受被引导找到自己喜欢的音乐的过程 。此前 , 我经常不得不循环播放相同的歌曲 , 这也是为什么我总是听收音机的原因 。现在 , 算法“连推带拉”地引导我从音乐库中挖到属于我自己的“宝石” 。对于这些算法 , 我最初也曾有过怀疑:它会不会产生“口味”趋同的效应 , 导致所有用户最终都只关注音乐库中的一部分歌曲 , 而使另外一些歌曲失去听众呢?但后来我发现 , 这些算法都采用了非线性或混沌理论的数学思想:我和你喜欢的音乐风格只要略微不同 , 那么被推荐的歌曲将会大相径庭 。
当在户外跑步时 , 我听了许多算法推荐的歌曲 , 它帮我找到了很多好听的新歌 。几周前 , 妻子想要在她的生日聚会上跳舞 , 让我帮她挑选一些20世纪80年代的歌曲 。但生日聚会结束后的第二天 , 我又去户外跑步时发现 , 算法给我推荐的全部都是20世纪80年代的舞曲 , 于是我不停地按“下一曲” , 但切换后出现的还是类似的歌曲 。之后我通过听其他音乐重新训练算法 , 花了好几周的时间才将这一切恢复如常 。
电子邮件过滤器也是基于人机交互训练算法工作的 。选用一些对你来说不是特别重要的邮件作为训练数据 , 将其中一部分标记为垃圾邮件 , 另一部分标记为正常邮件 。通过分析这些邮件中出现的单词 , 算法开始构建垃圾邮件过滤的规则:带有“伟哥”、“火辣的俄罗斯人”这一词汇的邮件100%是垃圾邮件;带有“再融资”这一词汇的邮件99%是垃圾邮件;带有“糖尿病”这个词的邮件不确定性比较大 , 因为似乎有一些人借助垃圾邮件四处传播治疗糖尿病的广告 , 但也有一些属于正常的邮件 。所以 , 算法对这部分邮件进行了简单的统计分析 , 发现每20封含有“糖尿病”这个词的邮件中 , 只有1封属于正常邮件 。因此 , 算法最终确定包含有“糖尿病”这一词汇的邮件有95%的可能是垃圾邮件 。
电子邮件过滤器可设置不同的过滤级别 。比如 , 只有在邮件有95%的概率是垃圾邮件的情况下 , 该邮件才应该进入“垃圾邮件”文件夹 。但现在更酷的是:虽然算法的训练数据是一组普通的电子邮件 , 但你的日常行为也将教会它识别你感兴趣的事情—算法会根据你所发出的邮件做出判断 。假设你患有糖尿病 , 那么 , 根据你设置的最初过滤级别 , 所有带有“糖尿病”一词的邮件都会进入“垃圾邮件”文件夹 。但渐渐地 , 随着你将越来越多的电子邮件(包括“糖尿病”一词)标记为“合法” , 算法会重新校准已构建的邮件过滤规则 , 将这类邮件所对应的概率降至远低于95%的水平 , 这类电子邮件就会正常地进入收件箱而不是“垃圾邮件”文件夹 。
不仅如此 , 算法还会自主创建新的算法 , 用于从所有包含“糖尿病”一词的邮件中区分出垃圾邮件和正常邮件 。其方法是引入其他的关键词 , 例如“治愈” 。机器学习算法将遍历你收到的每一封电子邮件 , 试图从中找出信息和关联 , 直到最后形成一个适合你个人生活方式的定制算法 。
无人驾驶汽车也是基于这样的概率更新原理而设计的 , 虽然它的控制系统远比这复杂得多 。该算法根据感知所获得的道路、车辆位置和障碍物信息等 , 来控制车辆的转向和速度 。
偏见和盲点
Netflix的推荐系统算法可以提取出影片中那些人类都难以名状的特征 , 非常令人不可思议 。这无疑挑战了洛夫莱斯的观点 , 即机器永远无法突破程序员思维的局限 。现如今 , 机器掌握了人类所不具备的一项技能:对海量数据进行分析 , 并从中发掘出有价值的信息 。
人类的大脑不擅长进行概率分析 , 这是进化的失败 。概率直觉感知力的构建必须基于大量的试验 , 然后从中发现可能的趋势性 。我们缺乏大量试验的机会 , 所以无法建立这种直觉 。从某种程度上来说 , 机器代码的发展弥补了人类大脑在数据交互方面低速率的缺陷 。因此 , 机器学习可以看作对人类思维方式的补充 , 而不仅仅是简单的复制 。
概率是机器学习的核心 。许多算法实际上都是确定性的 。这就好比一个人发现了问题的解决办法 , 然后通过编程促使计算机机械地在人所设定的规则下完成某一件事情 。这就像牛顿的世界观:宇宙是由数学方程控制的 , 科学家的任务是发现其中蕴含的规律并用它们来预测未来 。
20世纪的物理学家们向人们揭示了宇宙并不像我们此前想象的那样具有确定性 。量子物理理论认为 , 世界就像上帝在玩骰子 , 结果具有不确定性 , 取决于事件发生的概率 。概率思想主导下形成的算法具有非常强大的力量 , 这或许是为什么在新算法的世界中 , 那些受过物理思维训练的人比数学学者显得更游刃有余 。这是理性主义与经验主义之间的对抗 。但就我而言 , 经验主义占了上风 。
那台机器是如何在不知道游戏规则的情况下仅靠一个可以左右移动的滑块 , 以及屏幕中的像素及分数变化情况就学会了雅达利开发的Breakout游戏的?算法计算的是当前状态下 , 左右移动滑块对得分情况的影响 。由于移动所产生的影响是持续性的 , 可能是几秒钟时间 , 所以还需要计算延迟影响 。这就非常难了 , 因为我们并不总是能够确定这之间存在什么样的因果关系 。而这暴露了机器学习的一个缺点:它有时会把某些关联误认为是因果关系 。动物们也会被这个问题所困扰 。
美军用神经网络训练机器识别坦克图片的例子 , 是在机器学习社区里被反复提起的一个经典的反面教材 。该算法的训练数据是一些带标签的图片(标记出哪些有坦克 , 哪些没有坦克) 。通过对这些图片进行分析 , 算法获得了识别坦克的重要特征 。在分析了数百张带标签的图片之后 , 研究人员用一些算法从未见过的图片进行测试 , 结果非常振奋人心 , 识别准确率达到了100% 。
但将装有该算法的探测器部署到战场后 , 美军很快发现它毫无用处 。令研究小组感到迷惑不解的是 , 当他们用美军所使用的图片做分析时 , 探测器所给出的识别结果竟然是随机的 。直到后来通过深入研究他们才发现 , 只要图片拍摄于阴天 , 探测器就能做出正确的判断 。
一想到训练数据 , 他们就明白问题出在哪儿了:研究小组只是获得批准有权使用坦克有限的几天 , 所以他们将坦克开到不同地方 , 拍摄了大量位于不同伪装位置的照片 , 但没注意到那些天一直都阴阴沉沉的 。返回后 , 他们拍摄了一些没有坦克的乡村照片 , 但那时的天空是异常晴朗的 。用这些照片作为训练数据 , 算法就误认为晴天和阴天也是区分坦克的重要特征 。所以 , 一个坦克探测器就变成了一个对军方毫无用处的“阴天探测器”了 。从这个事件中我们总结的经验教训是:机器是能够学习的 , 但前提是你要让它学习对的东西 。
现如今 , 随着基于数据训练的算法广泛应用于社会的各行各业 , 如申请抵押贷款、治安决策、个人健康建议等 , 上面这个问题所造成的负面影响日益凸显 。很多证据表明 , 算法中暗藏着歧视和偏见 。麻省理工学院的一名研究生乔伊·布兰维尼(Joy Buolamwini)发现 , 她的脸相较于那些肤色较浅的同学 , 更加不易被所使用的机器人软件识别 。当她带上一个万圣节用的白色面具时 , 技术识别很顺利 , 可一旦取下面具 , 她就在机器眼中“消失”了 。
问题出在哪儿呢?该算法虽然针对大量的人脸图像进行了训练 , 但这些数据中黑色皮肤的面孔较少 。本应公平公正的人工智能 , 从数据中学会了人类的偏见 , 这种偏差导致算法生成了许多令人不可接受也难以接受的结果:针对男性的声音进行训练的语音识别软件识别不了女性的声音;某图像识别软件将黑人辨认为大猩猩;护照照片拍摄软件不适用于亚洲人 , 原因是它始终认为他们在拍照时闭眼了 。硅谷的科技公司雇用的员工中有4/5都是男性白人 , 这正是布兰维尼创立算法正义联盟以对抗人工智能算法偏见的原因 。
法律体系也面临着考验 , 申请抵押贷款、应聘工作、申领社会福利被算法程序拒绝后 , 人们有理由知道为什么 。但是 , 由于算法是基于数据交互构建决策树的 , 证明其决策的合理性并不容易 。
虽然有些人主张采取法律措施补救 , 但执行起来非常困难 。2018年5月生效的欧盟《一般数据保护条例》的第22条规定:数据主体有权反对“完全依靠自动化处理做出的决策” 。若个人对自动化决定不满 , 有权主张人工介入 , 以表达自己的观点并提出质疑 。对于计算机所做出的任何决策 , 数据主体有权获得“有关所涉及逻辑推断的有意义的信息” 。关于这一点 , 我只能表达我的个人观点:祝你好运!
人工智能领域一直呼吁开发一种元语言 , 机器可用它来证明自己的决策是合理的 。而在此之前 , 我们必须谨慎对待这些算法对日常生活的影响 。绝大多数算法都有其专长 , 不善于处理无规律的行为 , 当意料之外的事情出现时 , 算法只能选择将其忽略 , 而人类对这类场景却能表现出非凡的应变能力 。
没有免费午餐的定理表明 , 在任何情境下都能做出准确预测的通用性算法是不存在的 。机器学习的目标不是建立放之四海而皆准的通用模型 , 而是构建关于特定问题有针对性的解决方案 。这个定理还表明 , 即使只向算法出示一半数据 , 它还是有可能将未出示的另一半数据伪造出来 , 以保证对它自己所进行的数据训练的完整性 。但当需要分析的数据属于另一半未出示的数据时 , 它就会决策失准或失败 。
数据本身永远无法自给自足 , 它必须与知识相结合 。正是在这一点上 , 人类的思维和智慧似乎能更好地应对环境的变化并对全局进行把控—至少在目前看是这样 。
机器之间的战争
是改变和适应新挑战的能力 , 让AlphaGo得以诞生 。谷歌的DeepMind团队用一段时间的“监督学习”构建了他们的算法 , 这就好比一个成年人帮助孩子学习成年人已经掌握的技能 。作为一个物种 , 人类之所以取得进步 , 是因为我们积累了知识 , 并以比最初获得知识时更有效的方式将知识传递了下去 。作为一个数学家 , 我也是用上大学的几年时间快速学习了前辈们近几个世纪发现的数学理论 , 而不是凭借一己之力去重新发现所有的数学知识 , 以此站到学科前沿的 。
AlphaGo也经历了同样的学习阶段—我们称之为基础学习阶段 。互联网上有数以百万计的棋局 , 其中不乏高手之间的对弈 。这是一个极佳的资源宝库 , 通过检索就可以找到给对手致命一击的决胜杀招 。这样一个庞大的数据库使得计算机能够建立一个概率的概念 , 即给定一个特定的棋盘位置 , 算法可分析出每一步落子对获胜的影响概率 。仅考虑每一盘棋已有走法的优劣是不够的 , 因为未来的对手可能不会使用数据库中失败棋手所用过的棋路 。这个学习阶段为AlphaGo下围棋提供了必要的基础准备 , 但仅仅使用这个数据库还是不够的 。
第二阶段被称为强化学习阶段 。从长远来看 , 它为算法自我的发展确立了优势 , 提供了可能 。算法通过自我对战、强化学习来提高对弈水平 , 即与之前的“自己”不间断地训练以提高下棋的水平 。如果某些有望获胜的棋招失败了 , 算法就会修改这些棋招的概率 。这种强化学习会综合生成大量的新数据 , 有助于算法发现自身可能存在的弱点 。
局部最优是这种强化学习的弱点之一 。机器学习有点像攀登珠穆朗玛峰 , 如果目标是爬上这座世界上最高的山峰 , 但是此时你既不知道自己身处何处 , 又被蒙上了眼睛 , 那么可选择的策略就是以你所在位置为起始点 , 如果下一步能够爬得更高 , 那么就继续往上爬 , 如此往复 , 直至抵达顶峰 。按照该策略 , 你可以抵达所在地理区域内(当前环境下)的最高点 。一旦越过这个顶点 , 高度就会下降 , 你就有可能滚落下来 。但这并不意味着 , 在不断努力之下 , 你会抵达山谷对面另一座更高的山峰 。这个高点是相对的 , 在数学中被称为“局部极大值” 。就好比你好不容易爬上一座山的山顶 , 却发现它不过是在高耸的群山环绕下的一座小山包 。如果AlphaGo训练的算法只能在局部极大值的情况下击败对手 , 那终极结果会是怎么样的呢?
在与李世石对战的前几天 , 欧洲冠军樊麾帮AlphaGo进行赛前集训时发现了它的一个弱点 , 似乎就是这种情况 。这或许说明人类的下棋数据将算法导向了局部最优 , 而实际更优或者最优的下法与人类的下法存在一些本质的不同 , 即人类在事实上“误导”了AlphaGo 。算法很快就学会了如何重新评估自己的落子 , 以最大限度地提高再次获胜的概率 。是新对手把算法“逼下山” , 促使它找到了再攀高峰的新方法 。
文章图片
DeepMind团队目前又开发出了新一代的AlphaGo—AlphaZero , 它打败了曾书写历史的各版本AlphaGo前辈 。这个名字的由来是:由于是通用棋类人工智能 , 因此去掉了代表围棋的英文“Go”;没有使用人类的知识 , 从零开始训练 , 所以用“Zero”;两者相结合就得到了“AlphaZero” 。它已不再学习人类的棋谱、走法 , 而是完全依靠自我对弈来迅速地提高棋艺 , 从而走出人类对围棋认知的局限与定式 。就像雅达利的游戏算法一样 , 给定棋盘上361个(19×19)交叉点以及它们的得分规则 , 然后在自我对弈中试验棋步 。沿用最初在构建AlphaGo时所使用的强化学习策略 , 由“白板”状态开始“自学成才”是AlphaZero的独门秘籍 。DeepMind团队甚至也为新算法呈现出来的强大能力而感到震惊:它已不再受人类的思维和游戏方式的限制了 。
文章图片
AlphaZero自我训练的时间仅为3天 , 完成的自我对弈棋局数量就达到了490万盘 。人类花3000年才能实现的 , 它却只用了3天 。在对阵曾赢下李世石那一版的AlphaGo时 , AlphaZero取得了100 : 0的压倒性战绩 。经过40天的训练之后 , 它就所向披靡了 。它甚至能够在8小时内学会如何下国际象棋和日本将棋 , 水平甚至超过了市面上两个最好的国际象棋程序 。
AlphaGo项目的负责人大卫·西尔弗博士解释了这种“白板”学习在多个领域的影响:
如果能够实现“白板”学习 , 就相当于拥有一个可以从围棋移植到其他任何领域的桥梁 。这种算法是通用的 , 它会将你从所在领域的细节中解放出来 , 它普遍适合于任何领域 。AlphaGo并不是要打败人类 , 而是要发现做科学研究意味着什么 , 让程序能通过自学最终学习到哪些知识 。
【AI|算法的进化:机器会引发战争吗?】DeepMind的口号是:首先解决智力问题 , 然后用它来解决其他问题 。他们确信未来已在路上 。但这项技术能走多远?它在创造力方面能与最优秀的数学家相媲美吗?能绘画或是创作音乐吗?能破解人类大脑的秘密吗?
推荐阅读







- 星链|石豪:在太空,马斯克和美国当局是如何作恶的
- 快报|“他,是能成就导师的学生”
- 区块|面向2030:影响数据存储产业的十大应用(下):新兴应用
- 年轻人|人生缺少的不是运气,而是少了这些高质量订阅号
- 生活|气笑了,这APP的年度报告是在嘲讽我吧
- bug|这款小工具让你的Win10用上“Win11亚克力半透明菜单”
- 苏宁|小门店里的暖心事,三位创业者的雪域坚守
- 历史|科普:詹姆斯·韦布空间望远镜——探索宇宙历史的“深空巨镜”
- 空间|(科技)科普:詹姆斯·韦布空间望远镜——探索宇宙历史的“深空巨镜”
- 生活|数字文旅的精彩生活