机器之心发布
机器之心编辑部
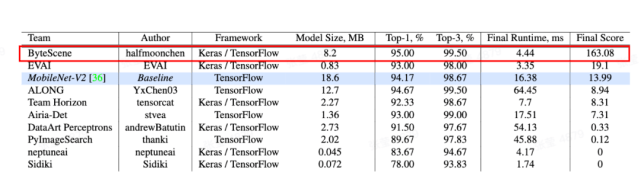
MAI(Mobile AI Workshop)是由 CVPR 主办的 Workshop 竞赛 。 近期 , 来自字节跳动智能创作团队的 ByteScene 团队在 MAI 2021 实时移动端场景检测项目上 , 以 163.08 分的绝对优势夺得冠军 。
文章图片
竞赛结果及相关报告见:https://arxiv.org/pdf/2105.08819.pdf
竞赛项目介绍
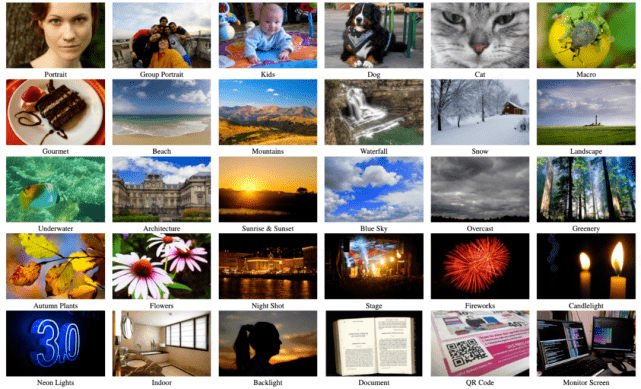
MAI 2021 实时移动端场景检测竞赛:基于 RGB 图像的实时高性能移动端场景类别预测 , 任务要求在移动端硬件上对摄像头输入的图像实时预测出其场景类别 , 总共有 30 个场景类别 。
文章图片
数据集:CamSDD (Camera Scene Detection Dataset) 数据集有超过 1.1 万张摄像头场景图像 , 每张图像都是分辨率为 576x384 的 RGB 图像 , 且属于 30 个场景类别中的某一个类别;其中 9897 张是有标注的训练集图像 , 600 张是无标注的验证集图像 , 还有 600 张是举办方保留的测试集图像 , 参赛者不会拿到测试集图像 。
评测方法:参赛者需要将训练好的图像场景类别预测模型转换为 8 位量化的 TFLite 模型 , 并将 TFLite 模型上传到举办方的服务器 。 在举办方的服务器上 , TFLite 模型会被发送到 Apple Bionic A11 SoC 移动端设备上测试模型运行耗时 , 并在举办方保留的测试集上测试 Top-1 和 Top-3 识别准确率 。
评价指标:
识别场景类别的 Top-1 准确率;
识别场景类别的 Top-3 准确率;
在 Apple Bionic A11 目标平台上的运行耗时;
最终评分是依据公式(C 是一个常数的标准化系数)
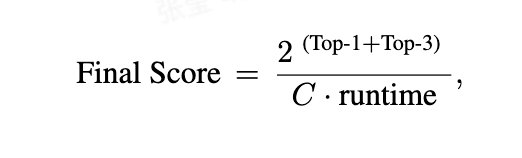
文章图片
团队成绩:来自字节跳动智能创作团队的 ByteScene 团队以 163.08 分的绝对优势夺得冠军 。
竞赛难点:
本次场景检测算法比赛要求兼顾在移动端上的速度和识别准确率 , 需要优化足够轻量级的高精度小模型;
训练集数据量有限 , 存在较大的过拟合(Overfit )风险;
算法背景介绍
自动预测摄像头图像的场景类别是智能手机上的一项基础算法能力 , 手机相机可以根据当前的摄像头图像场景类别对成像参数进行自动调节 , 以拍出最佳效果的图片和视频 。 为了能达到实时自动调节手机相机的能力 , 需要场景类别预测算法能在手机上实时运行 , 同时保证识别准确率 。 这对算法设计者来说 , 是一项很大的挑战 。
字节跳动的 ByteScene 团队使用迁移学习的方法训练大模型和移动端小模型 , 并使用迁移后的大模型对过滤后的额外数据打上伪标签 , 利用这些额外数据和原有训练集训练出了移动端高效且高准确率的场景检测算法 。
算法技术方案
ByteScene 团队使用了一种受 Google 的 Big transfer 工作启发的迁移学习方法来训练大模型和移动端小模型(如图 3) 。 移动端小模型是使用如表 3 所示的 MobileNetV3-Like 架构 , 该架构在 ImageNet 2012 验证集上获得了 67.82% 的 Top-1 准确率 , 它是使用字节跳动智能创作团队自研的 NAS 算法搜索出来的 , 该模型只有 86M FLOPs 的计算量 。 ByteScene 通过将输入图像的分辨率从 576×384px 缩小为 128×128px , 大大减少了计算量 。

文章图片
【检测|CVPR实时移动端检测场景竞赛:字节跳动绝对优势夺冠】图 3.ByteScene 团队使用的算法模型训练方案
大模型的训练
ByteScene 团队基于 ResNet101x3 主干网络建立了分类大模型 , 首先保留 1003 张有标签图像作为自用验证集 , 在 CamSDD 训练集上对带有预训练的大模型进行了微调 。 在微调过程中 , 它的主干被固定住 , 并且使用 AdamW 优化了 10 个 epoch 。 然后 , ByteScene 利用训练好的第一版大模型对官方的验证集打上伪标签 , 得到新的验证集后 , 利用所有可用的训练图像对大模型进行再次训练 。 最终训练得到的大模型在官方验证集上达到了 97.83% 的 Top-1 准确率 。
移动端模型训练
ByteScene 利用训练好的大模型过滤出了 2577 张额外图像 , 并打上了伪标签 , 将额外图像加入了原有的训练集 。 首先 , 使用 AdamW 优化器对带有预训练的移动端模型 (表 3) 在新训练集上进行微调 。 接下来 , 对模型主干进行解冻 , 继续对模型进行微调 。 最后 , 再次冻结模型主干 , 并使用 SGDW 优化器对模型进行了额外的微调 。

文章图片
表 3. ByteScene 使用的移动端模型结构 。
在第三次微调中 , 训练图像被直接缩小为 128×128 分辨率 。 最终的 INT8 量化 TFLite 模型是使用标准 TensorFlow 训练后量化工具转换得到的 。 为了保持量化后的模型精度 , 团队在移动端模型中仅使用了 ReLU6 和 HardSigmoid 这两种非线性激活函数 。
算法的应用
目前 , 视频内容是大众消费内容的很核心的一部分(抖音、TikTok 等) , 但剪辑视频对于大众用户来讲 , 依然属于比较复杂的信息处理手段 。 对于大众用户来讲 , “想剪一个高质量的视频”和 “剪辑技能的高门槛” 之间往往存在落差 。 智能模板匹配为大众用户提供了一个低门槛的快捷视频创作方式 , 真正实现了“一键成片”(如下图) 。 图像场景检测 / 分类算法通过预测每张图片素材的场景类别 , 为智能模板匹配提供了重要的匹配依据 。 这项算法 , 让普通用户也能通过简单的操作 , 剪辑出高质量的视频 , 有助于提升平台的用户体验和黏性 。

文章图片
字节跳动智能创作团队
智能创作是字节跳动的多媒体创新科技研究所和综合型服务商 。 覆盖音视频、计算机视觉、语音、图形图像、工程软件开发等多技术方向 , 在部门内部实现了内容创作和消费的闭环 。 旨在以多种形式向公司内部各类业务线和外部 toB 合作伙伴提供业界最前沿的多媒体和智能创作能力与行业解决方案 。
目前 , 智能创作团队已通过字节跳动旗下的智能科技品牌火山引擎向企业开放技术能力和服务 。
推荐阅读







- 赛道|声网发布实时互动场景创新生态报告,预测RTE行业市场规模将达千亿
- the|美CDC:抗原检测的“黑洞”可能隐藏着COVID-19“冰山”
- 带动力|自带动力“机器人管道工”现高交会,从事水下检测,全球首款
- 运动|老男孩的EDC,dido智能手表E10升级版,可实时了解健康状况
- 检测|机器人产业基础薄弱何解?工信部:补齐核心元器件等短板
- 检测|多款人工智能领域创新成果现身第二十三届高交会
- IT|电脑插个“U盘”就能给基因测序实时查看结果 售价1000美元
- 疫情|西安经开区企业助力西安新一轮全员核酸检测
- Type-C|华为鸿蒙手机可检测到数据线降低充电速度
- 检测|基于双目视觉的目标检测与追踪方案详解