机器之心报道
编辑:Liyuan、杜伟
自提出至今 , Transformer 模型已经在自然语言处理、计算机视觉以及其他更多领域「大展拳脚」 , 学界也提出了各种各样基于原始模型的变体 。 但应看到 , 学界依然缺少系统全面的 Transformer 变体文献综述 。 复旦大学邱锡鹏教授团队的这篇综述正好弥补了这一空缺 。自 2017 年 6 月谷歌发布论文《Attention is All You Need》后 , Transformer 架构为整个 NLP 领域带来了极大的惊喜 。 在诞生至今仅仅四年的时间里 , Transformer 已经成为自然语言处理领域的主流模型 , 基于 Transformer 的预训练语言模型更是成为主流 。
随着时间的推移 , Transformer 还开始了向其他领域的跨界 。 得益于深度学习的发展 , Transformer 在计算机视觉(CV)和音频处理等许多人工智能领域已然杀疯了 , 成功地引来了学界和业界研究人员的关注目光 。 到目前为止 , 研究者已经提出了大量且种类驳杂的 Transformer 变体(又名 X-former) , 但是仍然缺失系统而全面的 Transformer 变体文献综述 。
去年 , 谷歌发布的论文《Efficient Transformers: A Survey》对高效 Transformer 架构展开了综述 , 但主要关注 attention 模块的效率问题 , 对 Transformer 变体的分类比较模糊 。
近日 , 复旦大学计算机科学技术学院邱锡鹏教授团队对种类繁多的 X-former 进行了综述 。 首先简要介绍了 Vanilla Transformer , 提出 X-former 的新分类法 。 接着从架构修改、预训练和应用三个角度介绍了各种 X-former 。 最后概述了未来研究的一些潜在方向 。
论文链接:
https://arxiv.org/pdf/2106.04554.pdf
回顾 Transformer 的发展
Transformer 最初是作为机器翻译的序列到序列模型提出的 , 而后来的研究表明 , 基于 Transformer 的预训练模型(PTM) 在各项任务中都有最优的表现 。 因此 , Transformer 已成为 NLP 领域的首选架构 , 尤其是 PTM 。 除了语言相关的应用 , Transformer 还被用于 CV、音频处理 , 甚至是化学和生命科学 。 由于取得了成功 , 过去几年研究者又提出了各种 Transformer 变体(又名 X-former) 。 这些 X-former 主要从以下三个不同的角度改进了最初的 Vanilla Transformer
模型效率 。 应用 Transformer 的一个关键挑战是其处理长序列时的效率低下 , 这主要是由于自注意力(self-attention)模块的计算和内存复杂度 。 改进的方法包括轻量级 attention(例如稀疏 attention 变体)和分而治之的方法(例如循环和分层机制);
模型泛化 。 由于 Transformer 是一种灵活的架构 , 并且对输入数据的结构偏差几乎没有假设 , 因此很难在小规模数据上进行训练 。 改进方法包括引入结构偏差或正则化 , 对大规模未标记数据进行预训练等;
模型适配 。 这一系列工作旨在使 Transformer 适应特定的下游任务和应用程序 。
虽然可以根据上述角度来组织 X-former , 但许多现有的 X-former 可能会解决一个或几个问题 。 例如 , 稀疏 attention 变体不但降低了计算复杂度 , 而且在输入数据上引入了结构先验以缓解小数据集上的过度拟合问题 。 因此 , 主要根据 X-former 改进 Vanilla Transformer 的方式进行分类更加有条理:架构修改、预训练和应用 。 考虑到本次综述的受众可能来自不同的领域 , 研究者主要关注的是通用架构变体 , 仅简要讨论了预训练和应用方面的具体变体 。
Vanilla Transformer
架构
Vanilla Transformer 是一个序列到序列的模型 , 由一个编码器和一个解码器组成 , 二者都是相同的块 组成的堆栈 。 每个编码器块主要由一个多头 self-attention 模块和一个位置前馈网络(FFN)组成 。 为了构建更深的模型 , 每个模块周围都采用了残差连接 , 然后是层归一化模块 。 与编码器块相比 , 解码器块在多头 self-attention 模块和位置方面 FFN 之间额外插入了 cross-attention 模块 。 此外 , 解码器中的 self-attention 模块用于防止每个位置影响后续位置 。 Vanilla Transformer 的整体架构如下图所示:
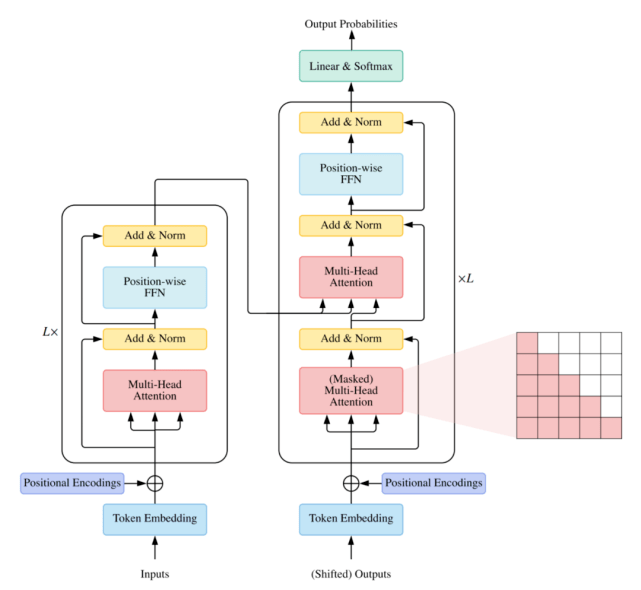
文章图片
用法
通常有三种不同的方式使用 Transformer 架构:
使用编码器 - 解码器 , 通常用于序列到序列建模 , 例如神经机器翻译;
仅使用编码器 , 编码器的输出用作输入序列的表示 , 通常用于分类或序列标记问题;
仅使用解码器 , 其中也移除了编码器 - 解码器 cross-attention 模块 , 通常用于序列生成 , 例如语言建模 。
Transformer 变体的的分类
截止目前 , 领域研究人员从架构修改类型、预训练方法和应用这三个方面提出了各种基于 vanilla Transformer 的变体模型 。 下图显示了 这些变体模型的类别:
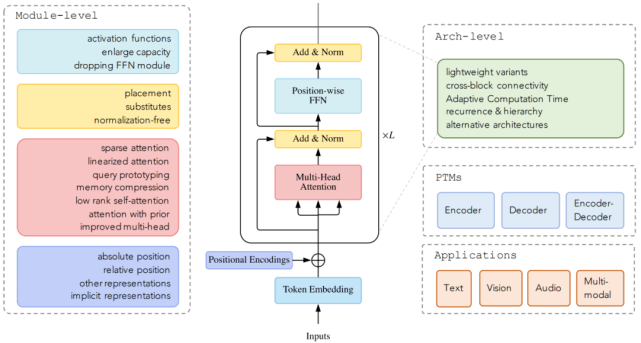
文章图片
而下图显示了本文研究者的分类和一些代表性模型:
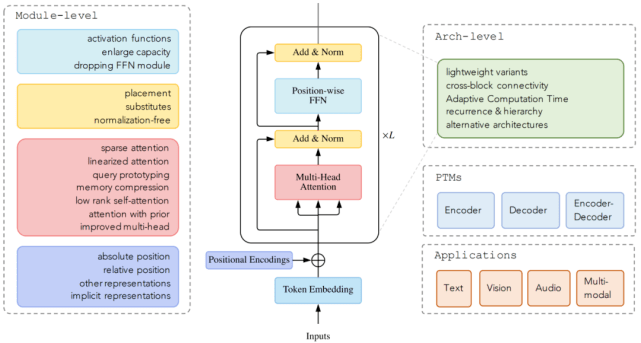
文章图片
Attention 模块
Self-attention 在 Transformer 中非常重要 , 但在实际应用中存在两个挑战:
复杂度 。 self-attention 的复杂度为 O(T^2·D) 。 因此 , attention 模块在处理长序列时会遇到瓶颈;
结构先验 。 Self-attention 对输入没有假设任何结构性偏差 , 甚至指令信息也需要从训练数据中学习 。 因此 , 无预训练的 Transformer 通常容易在中小型数据集上过拟合 。
Attention 机制的改进可以分为以下几个方向:
稀疏 attention 。 将稀疏偏差引入 attention 机制可以降低了复杂性;
线性化 attention 。 解开 attention 矩阵与内核特征图 , 然后以相反的顺序计算 attention 以实现线性复杂度;
原型和内存压缩 。 这类方法减少了查询或键值记忆对的数量 , 以减少注意力矩阵的大小;
低阶 self-Attention 。 这一系列工作捕获了 self-Attention 的低阶属性;
Attention 与先验 。 该研究探索了用先验 attention 分布来补充或替代标准 attention;
改进多头机制 。 该系列研究探索了不同的替代多头机制 。
稀疏 attention
在标准的 self-attention 机制中 , 每个 token 都需要 attend 所有其他的 token 。 然而 , 据观察 , 对于经过训练的 Transformer , 学习到的 attention 矩阵 A 在大多数数据点上通常非常稀疏 。 因此 , 可以通过结合结构偏差来限制每个查询 attend 的查询键对的数量来降低计算复杂度 。
从另一个角度来看 , 标准 attention 可以被视为一个完整的二部图 , 其中每个查询从所有内存节点接收信息并更新其表示 。 而稀疏 attention 可以看成是一个稀疏图 , 其中删除了节点之间的一些连接 。 基于确定稀疏连接的指标 , 研究者将这些方法分为两类:基于位置和基于内容的稀疏 attention 。
原子稀疏 attention
基于位置的稀疏 attention 之一是原子稀疏 attention , 如下图所示主要有五种模式 。 彩色方块表示计算的 attention 分数 , 空白方块表示放弃的 attention 分数 。
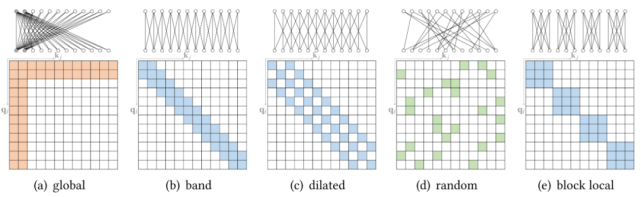
文章图片
复合稀疏 attention
而另一种基于位置的稀疏 attention 是复合稀疏 attention , 下图显示了其五种主要模式 , 其中红色框表示序列边界 。
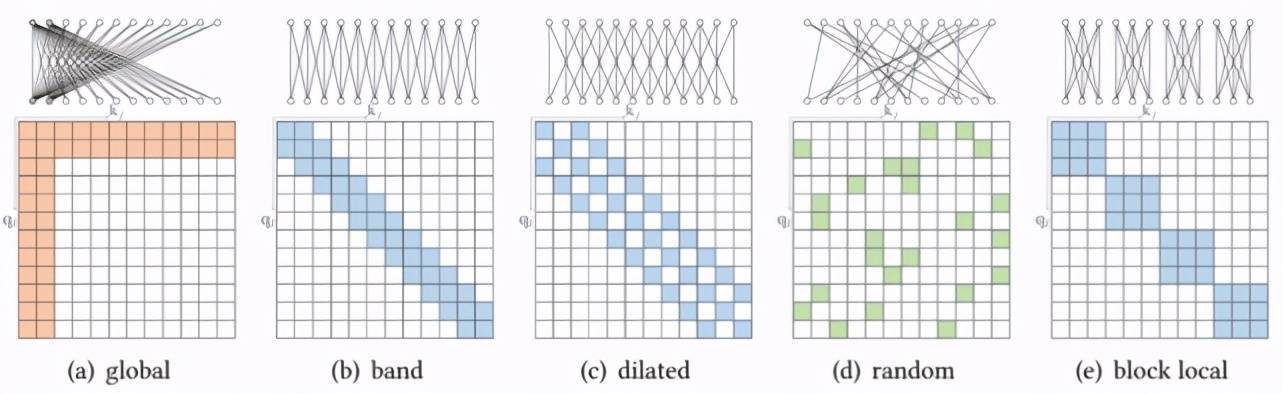
文章图片
扩展稀疏 attention
除了上述模式 , 一些现有的研究已经针对特定数据类型探索了扩展稀疏模式 。 下图(a)展示了全局 attention 扩展的抽象视图 , 其中全局节点是分层组织的 , 任何一对 token 都与二叉树中的路径相连 。 红色框表示查询位置 , 橙色节点 / 方块表示查询关注相应的 token 。
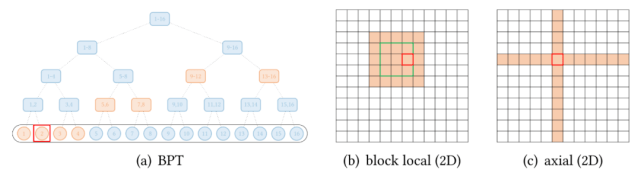
文章图片
还有一些视觉数据的扩展 。 Image Transformer 探索了两种类型的 attention:
按光栅扫描顺序展平图像像素 , 然后应用块局部稀疏 attention;
2D 块局部 attention , 其中查询块和内存块直接排列在 2D 板中 , 如上图 (b) 所示 。
视觉数据稀疏模式的另一个例子 , Axial Transformer 在图像的每个轴上应用独立的 attention 模块 。 每个 attention 模块沿一个轴混合信息 , 同时保持另一个轴的信息独立 , 如上图 (c) 所示 。 这可以理解为按光栅扫描顺序水平和垂直展平图像像素 , 然后分别应用具有图像宽度和高度间隙的跨步 attention 。
线性化 attention
下图显示了标准 self-attention 和线性化 linear-attention 的复杂度区别 。
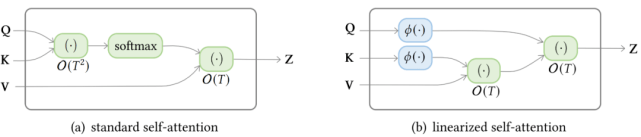
文章图片
查询原型和内存压缩
除了使用稀疏 attention 或基于内核的线性化 attention 之外 , 还可以通过减少查询或键值对的数量来降低 attention 的复杂度 , 这分别引向了查询原型和内存压缩的方法 。
在查询原型设计中 , 几个查询原型作为计算 attention 分布的主要来源 。 该模型要么将分布复制到表示的查询的位置 , 要么用离散均匀分布填充这些位置 。
下图 (a) 说明了查询原型的计算流程 。 除了通过查询原型减少查询数量外 , 还可以通过在应用 attention 机制之前减少键值对的数量(压缩键值内存)来降低复杂度 , 如下图(b)所示 。
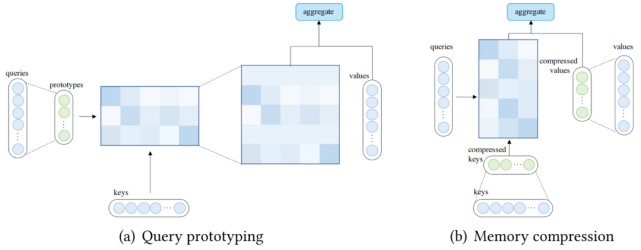
文章图片
先验 attention
Attention 机制通常将预期值输出为向量的加权和 , 其中权重是值上的 attention 分布 。 传统上 , 分布是从输入生成的 , 例如 Vanilla Transformer 中的 softmax(QK?) 。 一般情况下 , attention 分布也可以来自其他来源 , 也就是先验 。 先验注意力分布可以补充或替代输入产生的分布 。 Attention 的这种表述可以抽象为具有先验 attention , 如下图所示 。 在大多数情况下 , 两个 attention 分布的融合可以通过在应用 softmax 之前计算对应于先验 attention 和生成 attention 的分数的加权和来完成 。
【模型|Transformer模型有多少种变体?复旦邱锡鹏教授团队做了全面综述】
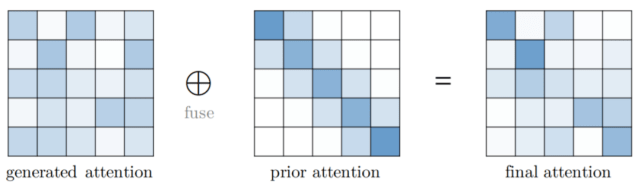
文章图片
改进的多头机制
多头 attention 的吸引力在于能够共同 attend 来自不同位置的不同表示子空间的信息 。 然而 , 没有机制可以保证不同的 attention 头确实地捕捉到不同的特征 。
如下图所示 , 多头机制下三种跨度屏蔽函数() 。 横轴代表距离 , 纵轴代表掩码值 。

文章图片
其他模块级修改
位置的重要性
验证卷积和循环网络不是置换等变是很简单的 。 然而 , Transformer 中的 self-attention 模块和位置前馈层都是置换等变的 , 这在建模问题时可能是一个问题 。 例如 , 在对文本序列建模时 , 单词的顺序很重要 , 因此在 Transformer 架构中正确编码单词的位置至关重要 。 因此 , 需要额外的机制将位置信息注入到 Transformer 中 。 一种常见的设计是首先使用向量表示位置信息 , 然后将向量作为附加输入注入模型 。
层的归一化
层归一化 ( Layer Normalization, LN) 以及残差连接被认为是一种稳定深度网络训练的机制(如减轻不适定梯度和模型退化) 。 在 Vanilla Transformer 中 , LN 层位于残差块之间 , 被称为 post-LN。 后来的 Transformer 实现将 LN 层放在 attention 或 FFN 之前的残差连接内 , 在最后一层之后有一个额外的 LN 来控制最终输出的大小 , 即 pre-LN 。 Pre-LN 已被许多后续研究和实现所采用 。 pre-LN 和 post-LN 的区别如下图所示 。
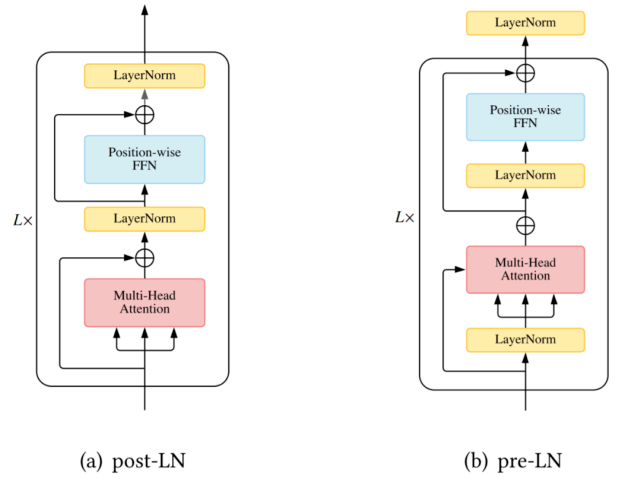
文章图片
位置方面的 FFN
尽管很简单 , 但位置前馈网络 (feed-forward network, FFN) 层对于 Transformer 实现良好性能至关重要 。 研究者观察到简单地堆叠 self-attention 模块会导致等级崩溃问题以及 token 均匀性归纳偏差 , 而前馈层是缓解此问题的重要构建块之一 。 本节探索了研究者对 FFN 模块的修改 。
架构级修改
在本章中 , 研究者介绍了架构层面的 X-former 变体模型 。
轻量级 Transformer
除了在模块层面为减轻计算开销所做的努力外 , 领域内还出现了一些在更高层面进行修改的轻量级 Transformer 模型 , 如 Lite Transformer、Funnel Transformer 和 DeLighT 。
Strengthening Cross-Block Connectivity
在 deep Transformer 编码器 - 解码器模型中 , 解码器中的 cross-attention 模块仅利用编码器的最终输出 , 因此误差信号必须沿着编码器的深度进行遍历 。 这使得 Transformer 更易于受到梯度消失等优化问题的影响 。
Transparent Attention [8] 使用每个 cross-attention 模块中所有编码器层(包括嵌入层)上的编码器表示的加权和 。 对于第 j 个编码器块 , cross-attention 应表示如下:
Feedback Transformer[34] 提出在 Transformer 解码器添加反馈机制 , 其中每个位置均关注来自所有层的历史表示的加权和:
自适应计算时间
与大多数神经模型一样 , Vanilla Transformer 使用固定(学习的)计算程序来处理每个输入 。 一个有趣且有发展潜力的修改是使计算时间以输入为条件 , 即在 Transformer 模型中引入自适应计算时间(Adaptive Computation Time, ACT) 。
如下图 12(a)所示 , Universal Transformer (UT) 结合了深度循环(recurrence-over-depth)机制 , 该机制使用一个在深度上共享的模块来迭代地改进所有符号的表示;图 12(b)中 , Conditional Computation Transformer (CCT) 在每个自注意力和前馈层添加一个门控模块来决定是否跳过当前层;图 12(c)中 , 与 UT 中使用的动态停机机制类似 , 有一条工作线专门用于调整每个输入的层数以实现良好的速度 - 准确率权衡 , 这称为「提前退出机制」(early exit mechanism) 。
利用「分而治之」策略的 Transformer
自注意力对序列长度的二次复杂度会显著限制一些下游任务的性能 。 研究者确定了两类有具有代表性的方法 , 分别是循环和层级 Transformer , 具体如下图 13 所示
在循环 Transformer 中 , 维护一个高速缓存(cache memory)用来合并历史信息 。 在处理一段文本时 , 该网络从缓存中的读取作为额外输入 。 处理完成后 , 网络通过简单地复制隐藏状态或使用更复杂的机制来写入内存 。
层级 Transformer 将输入分层分解为更细粒度的元素 。 低级特征首先被馈入到 Transformer 编码器 , 产生输出表示 , 然后使用池化或其他操作来聚合以形成高级特征 , 然后通过高级 Transformer 进行处理 。
推荐阅读







- 技术|“2”类医械有重大进展:神经介入产品井喷、基因测序弯道超车
- 智能化|适老化服务让银行更有温度
- bleu|字节跳动火山翻译上新 38 个稀有语种,翻译能力再升级
- 重大进展|“2”类医械有重大进展:神经介入产品井喷、基因测序弯道超车
- 人物|马斯克谈特斯拉人形机器人:有性格 明年底或完成原型
- 视点·观察|科技巨头纷纷发力元宇宙:这是否是所有人的未来?
- 华依|中信证券:惯性导航有望成为L3及以上自动驾驶的标配产品
- 实力比|小米12对标苹果遭嘲讽?雷军:国产手机的实力比想象中强,有和苹果比较的勇气
- 牛上|英媒文章:2021年最有趣的科学发现
- 虚拟|比尔·盖茨关于2022年的五项预言之二:元宇宙成有用的工具