全球最大|出门问问联合发布全球最大多领域中文语音识别数据集WenetSpeech
日前 , 中国领先的人工智能公司出门问问与西北工业大学音频语音和语言处理研究组(ASLP Lab)、希尔贝壳联合发布1万小时多领域中文语音识别数据集 WenetSpeech , 在腾讯会议天籁实验室、华为昇思 MindSpore、 西安未来人工智能计算中心等机构大力支持下 , 该数据集目前已经开放下载 。

文章图片
WenetSpeech 介绍
近十年以来 , 在深度学习的推动下 , 语音识别技术和应用均取得了突飞猛进的发展 , 搭载语音识别技术的相关产品和服务 , 诸如语音搜索、语音输入法、智能音箱、智能电视、智能穿戴、智能客服、机器人等已经广泛应用到我们生活的方方面面 。 但在现有的中文语音识别研究中 , 由于开源中文语音数据集数据量少 , 场景单一 , 缺乏挑战性 , 不能反映研究模型在大数据量和复杂场景下的泛化能力 , 例如 , 当前最大的中文普通话开源数据集 AIShell-2 , 包含1000小时的朗读风格录制数据 , 主流识别系统在该数据的测试集上获得的错误率低至5.3%左右 。 工业界往往使用更大规模的内部数据进行研究 , 而学术界无法获取这些数据进行研究 , 这导致了中文语音识别研究在学术界和工业界的严重割裂 。 另一方面 , 当下研究的热点无监督学习和自学习 , 在中文语音识别领域 , 也缺乏公开标准的大数据集的支持 。
今年以来 , Facebook 发布面向监督学习的5万小时的英文 audiobook 数据集 Multilingual LibriSpeech;SpeechColab 发布1万小时的多领域英文数据集 GigaSpeech 。 受这些工作的启发 , 同时中文语音识别研究也迫切需要一个标准的大规模多领域的数据集 , 为此出门问问与西北工业大学音频语音和语言处理研究组(ASLP Lab)、希尔贝壳设计开发了 WenetSpeech 数据集 。
WenetSpeech 除了含有 10000+ 小时的高质量标注数据之外 , 还包括2400+ 小时弱标注数据和 22400+ 小时的总音频 , 覆盖各种互联网音视频、噪声背景条件、讲话方式 , 来源领域包括有声书、解说、纪录片、电视剧、访谈、新闻、朗读、演讲、综艺和其他等10大场景 , 领域详细统计数据如下图所示 。
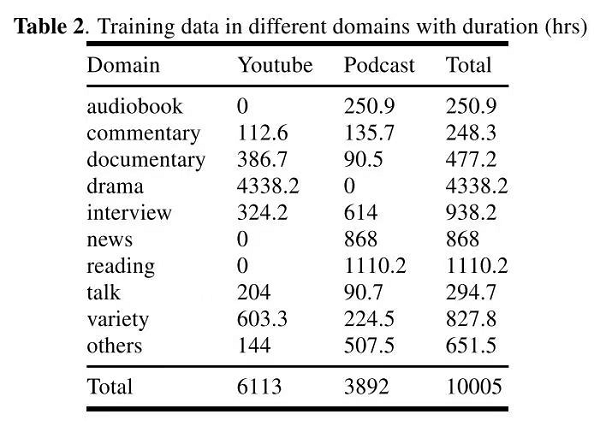
文章图片
数据收集
WenetSpeech 所有的数据均来源于网络 , 其中三分之二的数据来自 Youtube , 三分之一来自 Podcast 。
对于 Youtube 数据 , 我们人工选择含有嵌入式硬字幕(字幕嵌入在视频流中 , 非外挂字幕)的视频资源 , 并构建了如下图的基于 OCR 的系统进行数据挖掘 , 流程如下:
1.文本检测 , 在当前视频帧上进行文本检测 。
2.字幕位置校验 , 判断检测到的文本区域是否为合法的字幕区域 。
推荐阅读







- 最新消息|世界单体容量最大漂浮式光伏电站在德州并网发电
- 测试|图森未来完成全球首次无人驾驶重卡在公开道路的全无人化测试
- ASUS|华硕预热ROG Flow Z13:称其是“全球最强悍的游戏平板”
- AirPods|苹果谈论AirPods 3:最大榨取蓝牙技术,希望获得“更多带宽”
- IT|全球汽车行业价值两年突增至3万亿美元 中国电动车企立大功
- IT|全球供应25亿剂疫苗 科兴上半年营收110亿美元
- IT|全球每日新增确诊病例首超100万例 世卫:两大毒株正掀起“疫情海啸”
- 能力|有了长续航的独立通信手表,就不必为出门没带手机而焦虑了
- Tesla|特斯拉在美国召回约47.5万辆汽车 接近其去年全球交付总量
- 堆芯|全球首座,世界领跑!