全球最大|出门问问联合发布全球最大多领域中文语音识别数据集WenetSpeech( 二 )
3.字幕切换检测 , 已得到字幕位置和区域 , 在连续的视频帧上对该区域进行检测 , 直至该区域的字幕变化为止 , 得到字幕的起始和结束时间 。
4.文本识别 , 将字幕区域进行 OCR 识别 , 得到文本 。
5.将3中对应时间的音频提取出来 , 结合4中的文本 , 即得到字幕文本和该文本对应的音频 , 也就是语音识别训练中所需的文本和语音的候选平行数据 。

文章图片
下图中给出该 OCR 系统在不同场景下的几个典型示例 。 图中绿色的框为检测到的所有文字区域 , 红色的框为判定为字幕的文字区域 , 红色框上方的文本为 OCR 的识别结果 。可以看到 , 该系统正确的判定了字幕区域 , 并准确的识别了字幕文本 , 同时经过我们测试 , 发现该系统也可以准确判定字幕的起始和结束时间 。

文章图片
对于 Podcast 数据 , WeNet使用国内最好的商业语音识别系统之一 , 对 Podcast 数据进行切分 , 并生成切分后音频和其所对应的文本作为候选平行数据 。
数据校验
OCR 字幕识别和 ASR 语音转写生成的候选平行数据中不可避免的存在一些错误 , 如人工字幕本身有错误 , 字幕时间不准 , OCR 识别错误 , 转写错误等 。 为了检测该错误 , WenetSpeech 中提出一种基于端到端的自动标注错误检测算法 , 如下图所示 。 该算法首先根据候选平行数据的文本(ref)构建一个一个强制对齐图 , 该图中允许在任意位置进行删除、插入和替换操作 。 然后将候选平行数据的语音输入到该图进行解码得到识别结果(hyp) , 最终计算 ref 和 hyp 的编辑距离并做归一化从而得到该候选平行数据的置信度 。 当候选语音和文本一致性高时 , ref 和 hyp 一致性高 , 置信度高 , 反之 , 当候选语音和文本一致性低时 , 置信度低 。
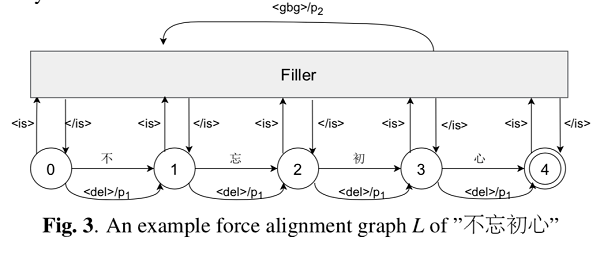
文章图片
WenetSpeech 中选取置信度>=95%的数据作为高质量标注数据 , 选取置信度在0.6和0.95之间的数据作为弱监督数据 。 关于该算法的详细内容 , 请参考我们的论文 。
排行榜
除了训练中校验用途的 Dev 集外 , 还设计了两个人工精标测试集 , 互联网测试集 Test_Net 和会议测试集 Test_Meeting , 作为“匹配”和“不匹配”测试 , 同时提供三个语音识别主流工具包(Kaldi , ESPNet , WeNet)上搭建的基线系统 , 方便使用者复现 。 在 10000+ 小时的高质量标注数据上 , 目前三个系统的语音识别率如下表所示(结果为 MER% , 中文算字错误 , 英文算词错误) 。
推荐阅读







- 最新消息|世界单体容量最大漂浮式光伏电站在德州并网发电
- 测试|图森未来完成全球首次无人驾驶重卡在公开道路的全无人化测试
- ASUS|华硕预热ROG Flow Z13:称其是“全球最强悍的游戏平板”
- AirPods|苹果谈论AirPods 3:最大榨取蓝牙技术,希望获得“更多带宽”
- IT|全球汽车行业价值两年突增至3万亿美元 中国电动车企立大功
- IT|全球供应25亿剂疫苗 科兴上半年营收110亿美元
- IT|全球每日新增确诊病例首超100万例 世卫:两大毒株正掀起“疫情海啸”
- 能力|有了长续航的独立通信手表,就不必为出门没带手机而焦虑了
- Tesla|特斯拉在美国召回约47.5万辆汽车 接近其去年全球交付总量
- 堆芯|全球首座,世界领跑!