文章图片
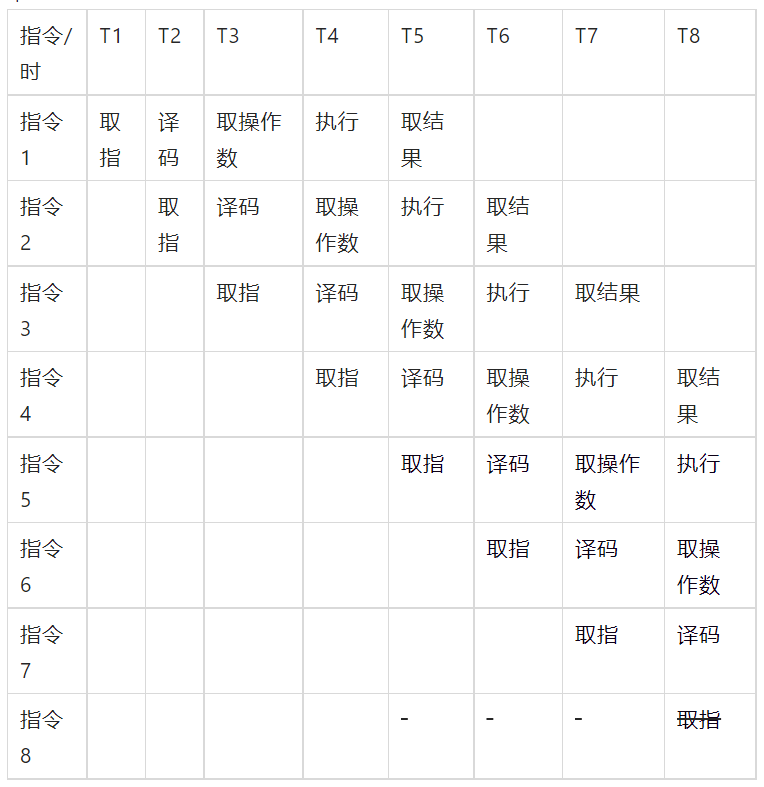
以上图流水线为例, 在T5时刻之前指令流水线以每周期一条的速度不断建立 , 在T5时代以后每个震荡周期 , 都可以有一条指令取结果 , 平均每条指令就只需要一个震荡周期就可以完成 。 这种流水线设计也就大幅提升了CPU的运算速度 。
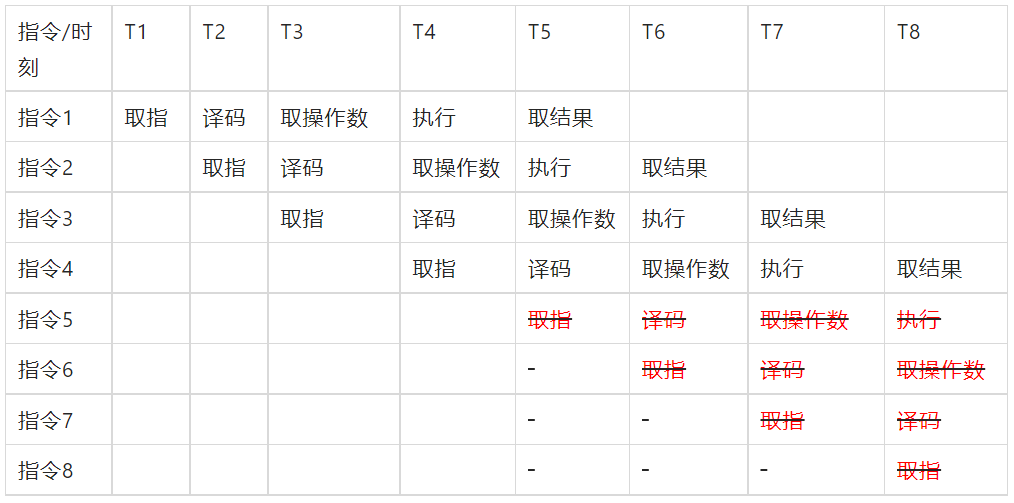
但是CPU流水线高度依赖指指令预测技术 , 假如在流水线上指令5本是不该执行的 , 但却在T6时刻已经拿到指令1的结果时才发现这个预测失败 , 那么指令5在流水线上将会化为无效的气泡 , 如果指令6到8全部和指令5有强关联而一并失效的话 , 那么整个流水线都需要重新建立 。
文章图片
所以可以看出例子当中的这个效率差完全是CPU指令预测造成的 , 也就是说CPU自带的机制就是会对于执行概比较高的分支给出更多的预测倾斜 。
处理建议-用哈希表替代switch 我们上文也介绍过哈希表也就是字典 , 可以快速将键值key转化为值value , 从某种程度上讲可以替换switch的作用 , 按照第一段代码的逻辑 , 用哈希表重写的方案如下:
import java.util.HashMap;
public class Main {
public static void main(String[] args) {
long now=System.currentTimeMillis();
int max=6,min=0;
HashMap<Integer,Integer> hMap = new HashMap<Integer,Integer>();
hMap.put(0,0);
hMap.put(1,0);
hMap.put(2,0);
hMap.put(3,0);
hMap.put(4,0);
hMap.put(5,0);
for(int j=0;j<10000000;j++){
int ran=(int)(Math.random()*(max-min)+min);
int value = https://www.sohu.com/a/hMap.get(ran)+1;
hMap.replace(ran,value);
}
long diff=System.currentTimeMillis()-now;
System.out.println(hMap);
System.out.println("time is "+ diff);
}
}
上述这段用哈希表的代码虽然不如代码一速度快 , 但是总体非常稳定 , 即使出现代码二的情况也比较平稳 。
经验总结 一、有并发的终端编程一定要注意按照缓存行(64byte)对齐 , 不按照缓存行对齐的代码就是每增加一个线程性能会损失20% 。
二、重点关注switch、if-else分支的问题 , 一旦条件分支的取值条件有所变化 , 那么应该首选用哈希表结构 , 对于条件分支进行优化 。
三、选择一款好用的性能监测工具 , 如:友盟U-APM , 不仅免费且捕获类型较为全面 , 推荐大家使用 。
本文为阿里云原创内容 , 未经允许不得转载 。
推荐阅读







- 产品|产品科研和品牌输出为基准点,雷炎科技建造品牌服务终端能力
- 峰会|TalkingData T11 2021 数据智能峰会线上举办,探寻赋能增长之道
- CBNData|超四成消费者追求家的安全感,家居向全屋智能进阶 |CBNData报告
- 华为|华为墨水屏平板曝光:支持智慧识屏一键接续,超级终端流转文章
- 控制|Azure Database for MySQL Flexible Server上线
- 手机|展锐第二代5G芯片平台实现终端量产,搭载手机明年上市
- 哈曼卡顿|联想 17 英寸 ThinkBook Plus 更多渲染图曝光,运行 Win11
- 哈曼卡顿|明晚发 小米12/Pro带你提前看 | 一加10Pro开启预约
- 智能汽车|22个月,数据驱动“新型终端”驶上新赛道
- 硬件|全国首家终端快充行业协会正式成立