常见机器学习算法优缺点:
朴素贝叶斯:
1. 如果给出的特征向量长度可能不同 , 这是需要归一化为通长度的向量(这里以文本分类为例) , 比如说是句子单词的话 , 则长度为整个词汇量的长度 , 对应位置是该单词出现的次数 。
2. 计算公式如下:
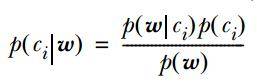
文章图片
其中一项条件概率可以通过朴素贝叶斯条件独立展开 。 要注意一点就是 的计算方法 , 而由朴素贝叶斯的前提假设可知 , = , 因此一般有两种 , 一种是在类别为ci的那些样本集中 , 找到wj出现次数的总和 , 然后除以该样本的总和;第二种方法是类别为ci的那些样本集中 , 找到wj出现次数的总和 , 然后除以该样本中所有特征出现次数的总和 。
3. 如果 中的某一项为0 , 则其联合概率的乘积也可能为0 , 即2中公式的分子为0 , 为了避免这种现象出现 , 一般情况下会将这一项初始化为1 , 当然为了保证概率相等 , 分母应对应初始化为2(这里因为是2类 , 所以加2 , 如果是k类就需要加k , 术语上叫做laplace光滑, 分母加k的原因是使之满足全概率公式) 。
朴素贝叶斯的优点:对小规模的数据表现很好 , 适合多分类任务 , 适合增量式训练 。
缺点:对输入数据的表达形式很敏感 。
决策树:决策树中很重要的一点就是选择一个属性进行分枝 , 因此要注意一下信息增益的计算公式 , 并深入理解它 。
信息熵的计算公式如下:
其中的n代表有n个分类类别(比如假设是2类问题 , 那么n=2) 。 分别计算这2类样本在总样本中出现的概率p1和p2 , 这样就可以计算出未选中属性分枝前的信息熵 。
现在选中一个属性xi用来进行分枝 , 此时分枝规则是:如果xi=vx的话 , 将样本分到树的一个分支;如果不相等则进入另一个分支 。 很显然 , 分支中的样本很有可能包括2个类别 , 分别计算这2个分支的熵H1和H2,计算出分枝后的总信息熵H’=p1*H1+p2*H2. , 则此时的信息增益ΔH=H-H’ 。 以信息增益为原则 , 把所有的属性都测试一边 , 选择一个使增益最大的属性作为本次分枝属性 。
决策树的优点:计算量简单 , 可解释性强 , 比较适合处理有缺失属性值的样本 , 能够处理不相关的特征;
缺点:容易过拟合(后续出现了随机森林 , 减小了过拟合现象) 。
Logistic回归:Logistic是用来分类的 , 是一种线性分类器 , 需要注意的地方有:
1. logistic函数表达式为:
其导数形式为:
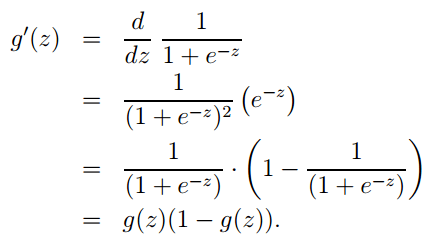
文章图片
2. logsitc回归方法主要是用最大似然估计来学习的 , 所以单个样本的后验概率为:
推荐阅读







- 人物|马斯克谈特斯拉人形机器人:有性格 明年底或完成原型
- 硬件|Yukai推Amagami Ham Ham机器人:可模拟宠物咬指尖
- Insight|太卷了!太不容易了!
- 王者|布局手术机器人赛道,谁是王者? | A股2022投资策略⑩
- 机器|戴森达人学院 | 戴森HP09空气净化暖风扇测评报告
- 孙自法|中国科技馆“智能”展厅携多款机器人亮相 喜迎新年和人机共融时代
- 国际|微创血管介入手术机器人获国际创业大赛冠军,获价值千万元奖励
- 猎豹|数字化助力实体消费 机器人让商场“热”起来
- 机器人|微创血管介入手术机器人获国际创业大赛冠军,获价值千万元奖励
- 观众|中国科技馆“智能”展厅携多款机器人亮相