1. svm中的最优分类面是对所有样本的几何裕量最大(为什么要选择最大间隔分类器 , 请从数学角度上说明?网易深度学习岗位面试过程中有被问到 。 答案就是几何间隔与样本的误分次数间存在关系:
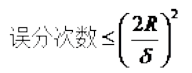
文章图片
, 其中的分母就是样本到分类间隔距离 , 分子中的R是所有样本中的最长向量值) , 即:
经过一系列推导可得为优化下面原始目标:
2. 下面来看看拉格朗日理论:
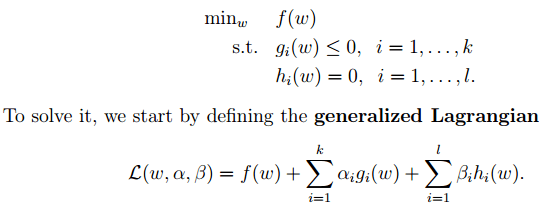
文章图片
可以将1中的优化目标转换为拉格朗日的形式(通过各种对偶优化 , KKD条件) , 最后目标函数为:
我们只需要最小化上述目标函数 , 其中的α为原始优化问题中的不等式约束拉格朗日系数 。
3. 对2中最后的式子分别w和b求导可得:
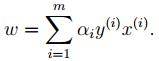
文章图片
由上面第1式子可以知道 , 如果我们优化出了α , 则直接可以求出w了 , 即模型的参数搞定 。 而上面第2个式子可以作为后续优化的一个约束条件 。
4. 对2中最后一个目标函数用对偶优化理论可以转换为优化下面的目标函数:
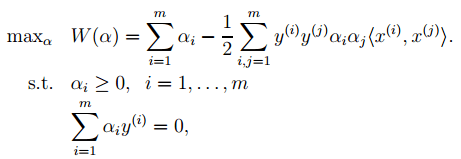
文章图片
而这个函数可以用常用的优化方法求得α , 进而求得w和b 。
5. 按照道理 , svm简单理论应该到此结束 。 不过还是要补充一点 , 即在预测时有:
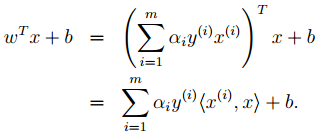
文章图片
那个尖括号我们可以用核函数代替 , 这也是svm经常和核函数扯在一起的原因 。
6. 最后是关于松弛变量的引入 , 因此原始的目标优化公式为:
此时对应的对偶优化公式为:
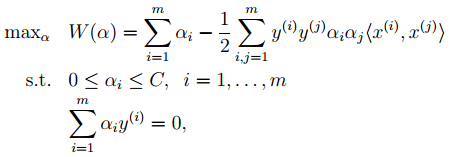
文章图片
与前面的相比只是α多了个上界 。
SVM算法优点:
1. 可用于线性/非线性分类 , 也可以用于回归;
2. 低泛化误差;
3. 容易解释;
4. 计算复杂度较低;
缺点:
1. 对参数和核函数的选择比较敏感;
2. 原始的SVM只比较擅长处理二分类问题;
Boosting:
主要以Adaboost为例 , 首先来看看Adaboost的流程图 , 如下:
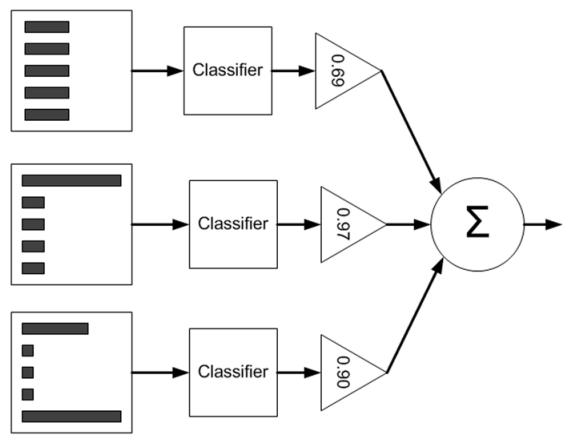
文章图片
从图中可以看到 , 在训练过程中我们需要训练出多个弱分类器(图中为3个) , 每个弱分类器是由不同权重的样本(图中为5个训练样本)训练得到(其中第一个弱分类器对应输入样本的权值是一样的) , 而每个弱分类器对最终分类结果的作用也不同 , 是通过加权平均输出的 , 权值见上图中三角形里面的数值 。 那么这些弱分类器和其对应的权值是怎样训练出来的呢?
推荐阅读







- 人物|马斯克谈特斯拉人形机器人:有性格 明年底或完成原型
- 硬件|Yukai推Amagami Ham Ham机器人:可模拟宠物咬指尖
- Insight|太卷了!太不容易了!
- 王者|布局手术机器人赛道,谁是王者? | A股2022投资策略⑩
- 机器|戴森达人学院 | 戴森HP09空气净化暖风扇测评报告
- 孙自法|中国科技馆“智能”展厅携多款机器人亮相 喜迎新年和人机共融时代
- 国际|微创血管介入手术机器人获国际创业大赛冠军,获价值千万元奖励
- 猎豹|数字化助力实体消费 机器人让商场“热”起来
- 机器人|微创血管介入手术机器人获国际创业大赛冠军,获价值千万元奖励
- 观众|中国科技馆“智能”展厅携多款机器人亮相