文章图片
文章图片
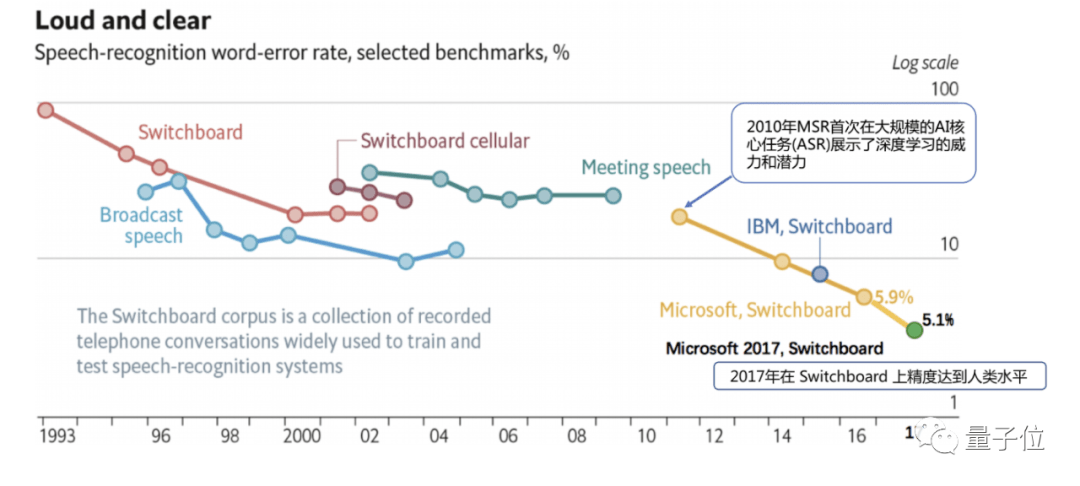
到了2017年 , 在Switchboard上的错误率被降低至5.1% , 这也是首次在这个数据集上AI达到了人类职业速记员的水平 。
重点是它让大家对深度学习、神经网络看法发生了改观——
“原来这是条可行的路” 。
于是 , 在这扇大门敞开之际 , 深度学习领域与之相关的各项研究都开始遍地开花 。
在此理念之下 , 何晓冬等人投身其中 , 探索从自然语言中提取出抽象的语义并将它投影到一个语义空间 , 以此来帮助搜索、推荐、分类、问答等实际应用 。
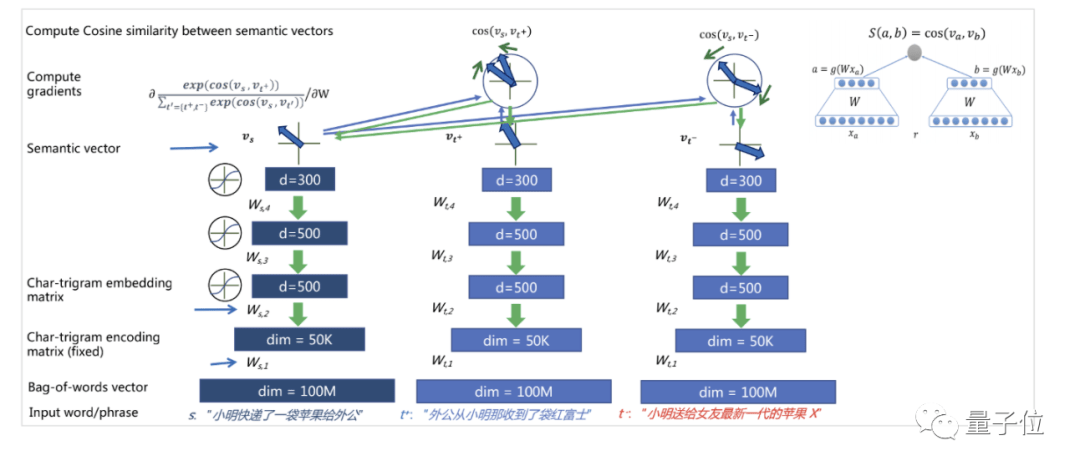
具体而言 , 他们在2013年提出了深度结构化语义模型DSSM (Deep Structured Semantic Models) , 将多样化的自然语言所表达的含义 , 表示成为一个多维度连续语义空间中的向量 。
文章图片
值得一提的是 , 该模型产生的影响可谓深远 , 不仅仅在学术界被引用过千次 , 在工业界也极具适应性 。
时至今日 , 几乎所有做搜索推荐场景的大厂仍在使用DSSM及其衍生模型 , 其影响力度可见一斑 。
除了语言之外 , 在2015年的一个工作中 , 他们将知识也用向量、矩阵等方式来表征并投影到高维连续语义空间中 。
更进一步 , 语音、语义或图像上的突破还只是单一领域的智能 , 而人类的智能更为复杂丰富 。
比如就像我们人类看下面这张图一样 , 很自然就能够get到图片中人物的活动 , 并用语言去描述出来 , 而不只是简单的检测出图中的人和物 。
同样在2015年 , 在CVPR (计算机视觉顶会)上深度学习巨头Yan LeCun 等人召集了一场深度视觉研讨会 (DeepVision Workshop),邀请Yoshua Bengio等就“视觉的未来”各抒己见 。

文章图片
会上 , 何晓冬在报告中提出了一个观点 , 便是语言-视觉深度多模态语义模型 (DMSM) , 也就是AI在描述一张图的时候 , 是否能够在语义层面上达到一个等价的匹配 。
换句话说 , 就是我们常说的“看图说话” , 文字描述出来的话和图片的内容在语义上要是一致的 。
而何晓冬他们提出的DMSM模型就是一个具体实现的算法 , 能够把图像和文字都表示成为同一个跨模态语义空间内的向量 。
而后在这个空间中进行跨模态语义匹配计算 , 从而帮助生成最匹配图像内容的文字表述 。

推荐阅读







- 京东方|消息称京东方 2022 年扩张带鱼屏产品线
- 影像|京东零售集团CEO辛利军空降小米“跑进2022”活动直播间为米粉送福利
- 出货|消息称京东方 2022 年推 40 英寸带鱼曲面屏:4K+分辨率
- 服贸|京东云助力打造“永不落幕的服贸会”案例入选中国信通院“云安全守卫者计划”
- 平台|京东云助力打造“永不落幕的服贸会”案例入选中国信通院“云安全守卫者计划”
- jbhcfw|京东慧采适合什么样的企业入驻,我们公司合适么?
- 汽车|阿联酋批准国药新疫苗用作加强针;京东方重庆第6代AMOLED(柔性)生产线正式量产 | 思维独角兽
- 硬件|投资465亿 京东方重庆第6代AMOLED柔性生产线正式量产
- 硬件|京东方晶芯首个玻璃基4K产品交付 百万级对比度、115%色域
- 技术|京东方晶芯 MLED 首个玻璃基 AM P0.9 直显 4K 产品成功交付