此外 , 九州通也使用 Amazon Aurora 替换了传统 MySQL 数据库 , 整体数据库性能提升了 5 倍 , TCO 降低了 50% 。
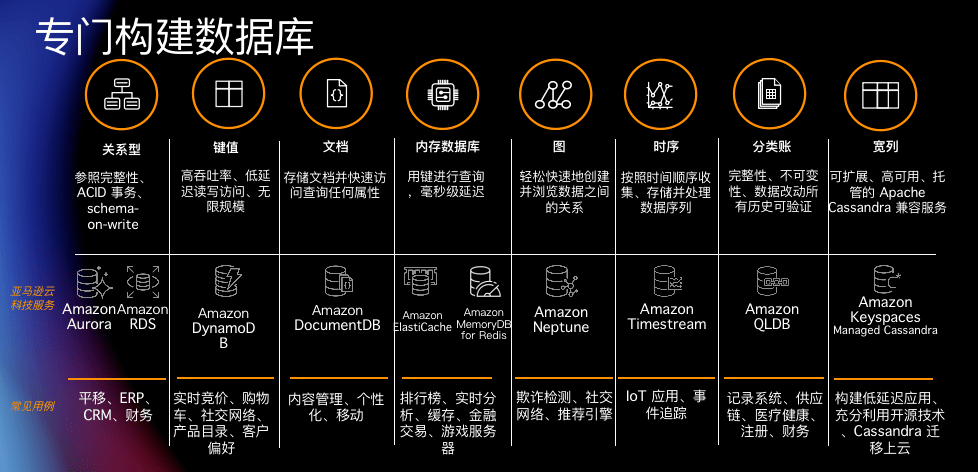
其次 , 为实现专库专用 , 亚马逊云科技现在已有十多种专门构建的数据库服务 , 囊括了关系、键值、文档、内存、图、时间序列、宽列和分类账八大数据类型 。 这些数据库产品各有优势 , 分别适用于不同的应用场景 。
文章图片
其中 , Amazon MemoryDB for Redis 是一个与 Redis 兼容的、持久的内存数据库服务 。 它是为具有微服务体系结构的现代应用程序专门构建的, 可以用作微服务应用程序的高性能主数据库 , 企业不需要再分别管理缓存和持久数据库 。
Amazon DocumentDB 则是一项快速、可扩展、高度可用且完全托管式文档数据库服务 , 支持 MongoDB 工作负载 。 作为一个文档数据库 , Amazon DocumentDB 可以简化存储、查询和索引 JSON 数据 。 开发人员可以使用与今天相同的 MongoDB 应用程序代码、驱动程序和工具 , 来运行、管理和扩展 Amazon DocumentDB 上的工作负载 , 享受改进后的性能、可扩展性和可用性 , 而无需担心底层基础设施的管理 。
Amazon DynamoDB 是为海量数据、大型混合工作负载而生的键值数据库服务 , 根据官方介绍 , Amazon DynamoDB 可以构建吞吐量和存储空间几乎无限的应用程序 , 在任意规模环境中提供一致的个位数毫秒响应时间 , 极其适合游戏、广告技术、移动互联以及其它需要任何规模的低延迟数据访问的应用程序 。 虎牙已经通过 Amazon DynamoDB 自动扩容来应对 10 倍以上的流量突增 。
众所周知 , NoSQL 很多时候是在做“大力出奇迹”的事情 , 即通过大量的冗余存储 + 索引实现快速访问 , 但是这也有可能造成存储空间的浪费 。 而在亚马逊云科技 re:Invent 大会上正式发布的 Amazon DynamoDB Standard-Infrequent Access (DynamoDB Standard-IA) , 在保持同样性能、耐用性和伸缩性的同时 , 最高还可以为使用者节省 60% 的存储空间 。
再者 , 亚马逊云科技的数据库服务与人工智能技术深度集成 。 亚马逊云科技的 Amazon Aurora ML、Amazon Neptune ML 等服务 , 支持数据库开发者在不具备机器学习专业知识情况下 , 只需使用熟悉的数据库查询语言(比如 SQL)即可进行机器学习操作 。
我们不得不谈的是云数据库在提供数据存储服务于应用之后的价值 ,实现统一分析和利用机器学习进行业务创新 , 助力企业数据驱动的业务转型 。 像亚马逊云科技提出的“智能湖仓架构”实现的是通过一系列的服务 , 允许数据库 , 数据仓库以及各种分析工具之间的数据无缝流动 , 同时在数据库内提供直接开始机器学习的能力 ,让 DBA、数据库工程师也能很快利用机器学习来进行业务创新而不是关注技术学习 ,这都是云数据库的优势 。 人工智能平台公司启元世界使用了“智能湖仓”进行云上创新 , 实现了数据的融合和统一治理 , 加快了其全生命周期产品矩阵理念的落地和规模发展 。 同时 , 对流数据处理系统实现了分钟级部署 , 并能够轻松承载百万 QPS(每秒查询率)流数据 , 还将批处理运行时间减少 80% , 运营总成本下降 50% 。
推荐阅读







- 建设|这一次,我们用SASE为教育信息化建设保驾护航
- 最新消息|中围石油回应被看成中国石油:手续合法 我们看不错
- 蛋白|二代新冠疫苗来了!打了一代,还需要它吗?
- 国药|二代新冠疫苗来了!打了一代,还需要它吗?
- 标题|致我们的2021,所有奋斗终将闪耀
- 吴祖榕|上线 2 周年,用户数破 2 亿,腾讯会议和我们聊了聊背后的产品法则
- 生活|2022,你为什么需要一块华为 WATCH GT3?
- 植物|开放生物资源,保护多样性:我们为了生物安全的那些努力。
- jbhcfw|京东慧采适合什么样的企业入驻,我们公司合适么?
- 市场|折叠屏手机为啥火了?成熟可能还需要两年时间