错误|有了这个工具,不执行代码就可以找PyTorch模型错误( 二 )
PyTea 由两个分析器组成 , 在线分析器:node.js (TypeScript / JavaScript);离线分析器:Z3 / Python 。
- 在线分析器:查找基于数值范围的形状不匹配和 API 参数的滥用 。 如果 PyTea 在分析代码时发现任何错误 , 它将停在该位置并将错误和违反约束通知用户;
- 离线分析器:生成的约束传递给 Z3。 Z3 将求解每个路径的约束集并打印第一个违反的约束(如果存在) 。
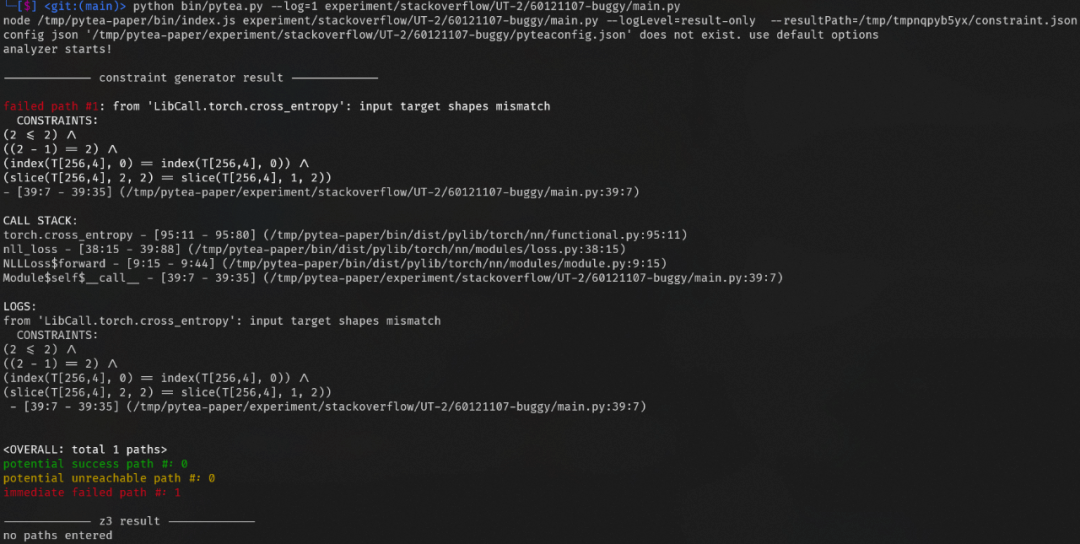
文章图片
离线分析器发现错误:
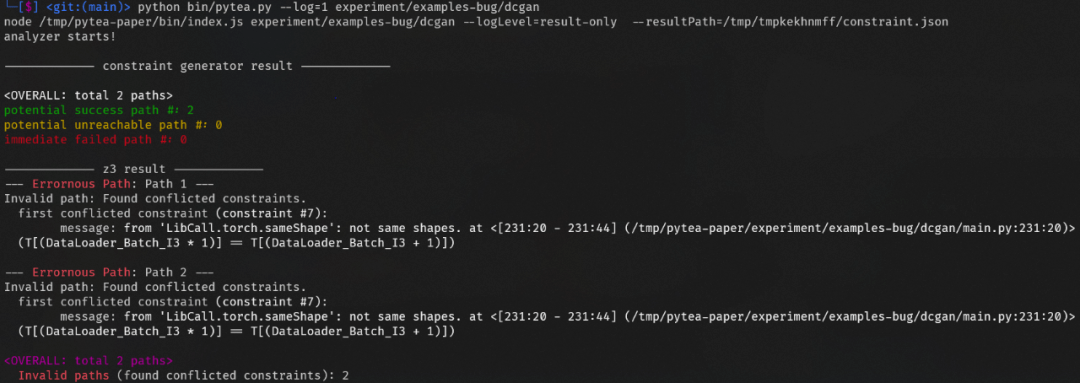
文章图片
为了更好的理解 PyTea 执行静态分析过程 , 下面我们介绍一下主要的技术细节 , 包括 PyTorch 程序结构、张量形状错误、PyTea IR 等 , 以便读者更好的理解执行过程 。
首先是 PyTorch 程序结构 , PyTorch、TensorFlow 和 Keras 等现代机器学习框架需要使用 Python API 来构建神经网络 。 使用此类框架训练神经网络大多遵循如下四个阶段的标准程序 。
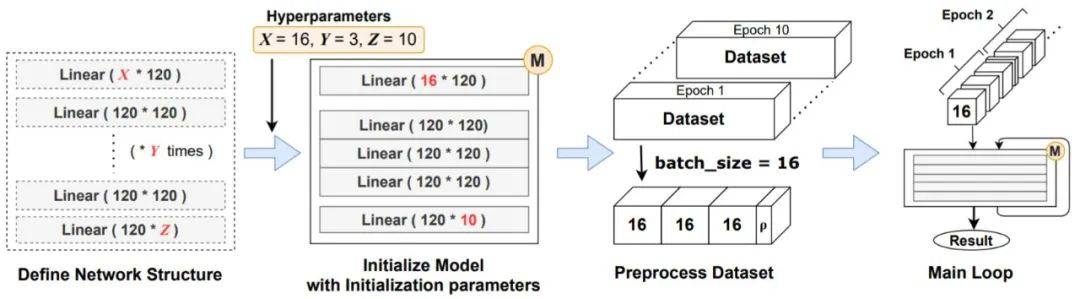
文章图片
在 PyTorch 中 , 常规神经网络训练代码的结构 。
训练模型需要先定义网络结构 , 图 2 为一个简化的图像分类代码 , 取自官方的 PyTorch MNIST 分类示例:

文章图片
在这里 , 上述代码首先定义一系列神经网络层 , 并使它们成为单一的神经网络模块 。 为了正确组装层 , 前一层的返回张量必须满足下一层的输入要求 。 网络使用超参数的初始化参数进行实例化 , 例如隐藏层的数量 。 接下来 , 对输入数据集进行预处理并根据网络的要求进行调整 。 从该阶段开始 , 每个数据集都被切成较小的相同大小的块(minibatch) 。 最后 , 主循环开始 , minibatch 按顺序输入网络 。 一个 epoch 是指将整个数据集传递到网络的单个循环 , 并且 epoch 的数量通常取决于神经网络的目的和结构 。 除了取决于数据集大小的主训练循环之外 , 包括 epoch 数在内 , 训练代码中的迭代次数在大多数情况下被确定为常数 。
在构建模型时 , 网络层之间输入、输出张量形状的不对应就是张量形状错误 。 通常形状错误很难手动查找 , 只能通过使用实际输入运行程序来检测 。 下图就是典型的张量形状错误(对图 2 的简单修改) , 如果不仔细查看 , 你根本发现不了错误:
推荐阅读







- 物流|市占率全球第一,引领行业变革,深圳这个独角兽企业分享经验
- 品牌|家用燃气灶具新国标本月实施,这个功能必须有
- 平台|暨大这个实验室有趣又有料
- 益生菌产品|益生菌产业发展有了指导方向
- 消费者|这个赛道能让人“躺平”,大厂、VC们都来了
- 人工智能|这个赛道,竟然是 AI 行业的新拐点
- 女声|喜欢听ACG音乐的话,不要碰森海塞尔这个牌子
- 图片|在这个纷扰复杂的世俗世界里……
- 网友|月球表面“神秘小屋”真相被揭开,居然是这个
- 警告!|听说这个App上线就送对象 结果上线就骗了我六块钱