模型|经逆向工程,Transformer「翻译」成数学框架 | 25位学者撰文( 三 )
文章图片
最后 , 两层 attention-only transformers 模型可以使用注意力头组合实现复杂得多的算法 。 这些组合算法也可以直接通过权重检测出来 。 需要注意的是 , 两层模型适应注意力头组合创建「归纳头」(induction heads) , 这是一种非常通用的上下文内学习算法 。
具体地 , 当注意力头有以下三种组合选择:
- Q - 组合:W_Q 在一个受前面头影响的子空间中读取;
- K - 组合:W_K 在一个受前面头影响的子空间中读取;
- V - 组合:W_V 在一个受前面头影响的子空间中读取 。
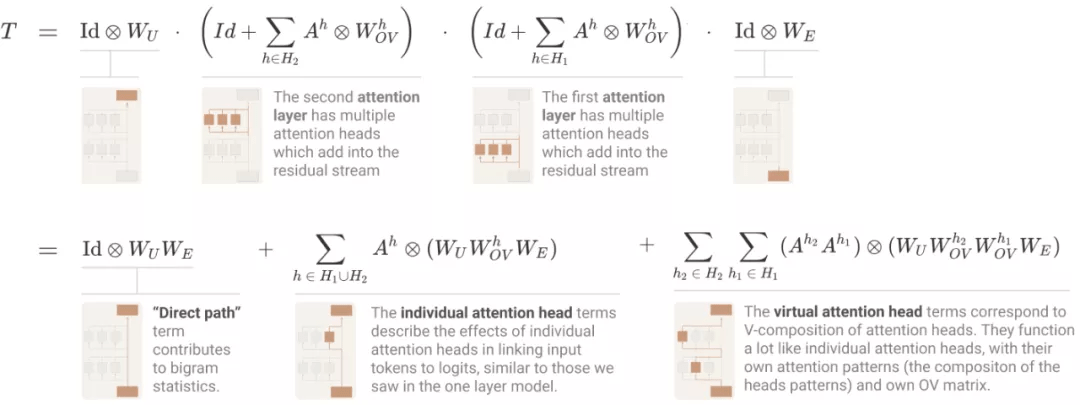
对于 transformer 有一个最基础的问题 , 即「如何计算 logits」?与单层模型使用的方法一样 , 研究者写出了一个乘积 , 其中每个项在模型中都是一个层 , 并扩展以创建一个和 , 其中每个项在模型中都是一个端到端路径 。
文章图片
其中 , 直接路径项和单个头项与单层模型中的相同 。 最后的「虚拟注意力头」项对应于 V - 组合 。 虚拟注意力头在概念上非常有趣 , 但在实践中 , 研究者发现它们往往无法在小规模的两层模型中发挥重大作用 。
此外 , 这些项中的每一个都对应于模型可以实现更复杂注意力模式的一种方式 。 在理论上 , 很难对它们进行推理 。 但当讨论到归纳头时 , 会很快在具体实例中用到它们 。
推荐阅读







- 21世纪经济报道|地方政府跑步入局元宇宙 谁能建立先发优势?
- 中新经纬|反向带货还是饥饿营销,瑞幸李国庆互怼伤害了谁?
- 物流|市占率全球第一,引领行业变革,深圳这个独角兽企业分享经验
- 代码|周鸿祎:不理解35岁被职场抛弃,中国人35岁就老了?程序员年纪越大经验越丰富
- 新浪科技|视频|李东生获十大经济年度人物,眼眶湿润 几近哽咽落泪
- 新浪科技综合|中国学者找到新生儿黄疸与空气污染的关系 建预测模型
- 澎湃新闻|“漠河舞厅”商标被经销公司抢注,当前状态为“等待实质审查”
- 科技|华数集团战略合作部·华数传媒网络余浙东总经理参观云针科技
- 21世纪经济报道|荣耀推出首个高端折叠屏手机,京东方、沃特股份亮明合作关系
- 幽门螺旋杆菌|“抗幽牙膏”坑人的“生意经”