机器之心报道
编辑:杜伟
机器学习彻底改变了人们使用数据以及与数据交互的方式 , 提升了商业效率 , 从根本上改变了广告业的格局 , 全面变革了医疗健康技术 。 但是 , 机器学习若要继续扩大其影响力和影响范围 , 开发 pipeline 必 须得到改进 。 通过将数据库系统、分布式计算和应用部署等领域数十年的工作引入机器学习领域 , 机器学习系统研究可以满足这一需求 。 此外 , 通过充分利用模型并行以及改进旧有解决方案 , 我们可以利用系统的重新设计来改进机器学习 。
文章图片
过去十年 , 机器学习(ML)已经成为各种领域中无数应用和服务的重要组成部分 。 得益于机器学习的快速发展 , 从医疗健康到自动驾驶等诸多领域已经出现了深刻的变革 。
机器学习在实际应用中日益增加的重要性使人们开始关注一个专注于「实践中机器学习」的新领域 , 即机器学习系统(或简称 MLOps) 。 该领域连通计算机系统和机器学习 , 并从传统系统研究的视角考虑机器学习的新挑战 。
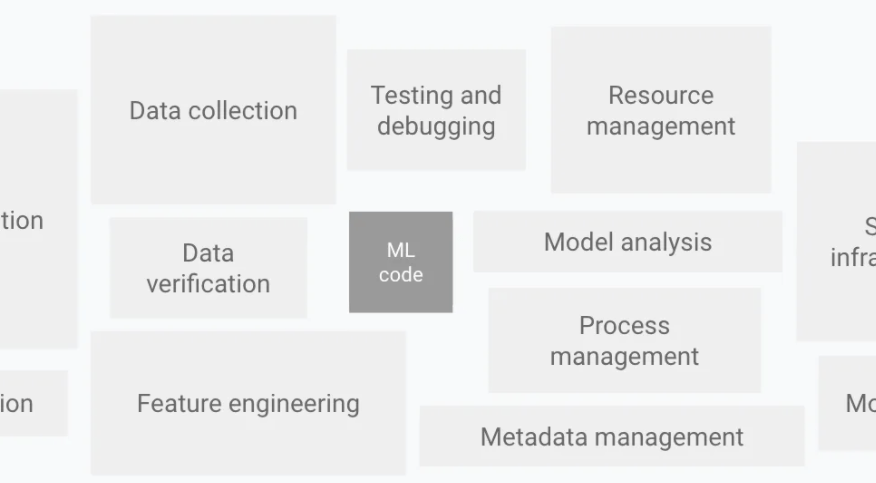
那么机器学习的挑战究竟有哪些呢?加州大学圣地亚哥分校博士生 Kabir Nagrecha 使用 D. Sculley 2015 年的论文《 Hidden Technical Debt in Machine Learning Systems 》中提出的架构 , 来描述典型 ML 系统中的问题并一一分解其组件 。
文章图片
D. Sculley 论文中的 ML 系统架构 , 图源:https://papers.nips.cc/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf
Kabir Nagrecha 重点分析了数据收集、验证和服务任务中的挑战 , 并探讨了模型训练中的一些问题 , 这是因为近年来模型训练已经成为系统开发中成本越来越高昂的部分 。
接下来我们进行一一分析 。
数据收集
虽然学界研究者对 CIFAR 或 SQuAD 等随时可用的数据集感到满意 , 但业界从业者往往需要在模型训练中手动标注并生成自定义数据集 。 但是 , 创建这类数据集 , 尤其是需要领域知识时 , 需要的成本可能非常高昂 。
因此 , 这成为了 ML 系统开发者面临的一个主要挑战 。
如何解决呢?该问题最成功的解决方案之一是借鉴系统与机器学习领域的研究 。 比如 , 通过结合数据管理技术与自监督学习工作 , 斯坦福大学研究者在 2017 年的论文《 Snorkel: Rapid Training Data Creation with Weak Supervision 》中提出了一种弱监督的数据编程方法 。
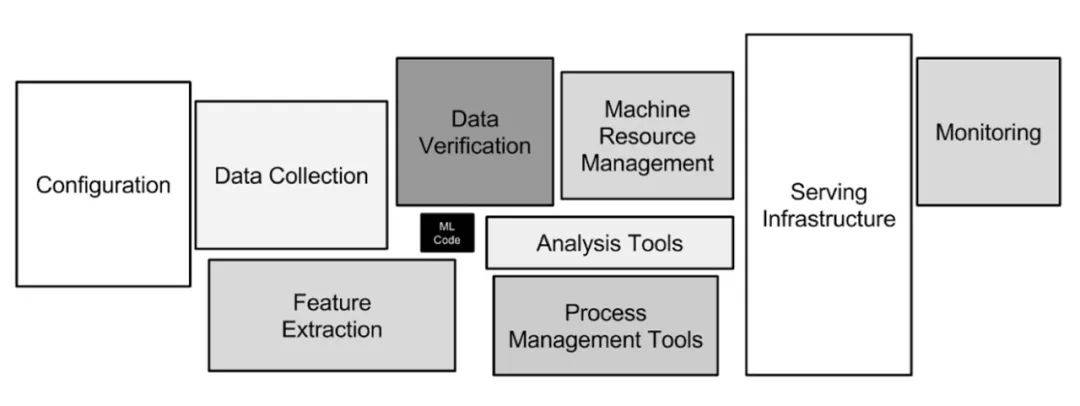
他们提出的 SnorkelAI 将数据集创建视作一个编程问题 , 其中用户可以为弱监督标注指定函数 , 然后通过组合和加权操作以生成高质量的标签 。 这样一来 , 专家标注的高质量数据和自动标注的低质量数据可以进行融合和跟踪以确保模型训练实现准确加权 , 从而充分考虑到不同级别的标签质量 。
文章图片
SnorkelAI 结合了不同来源的标签 , 以允许模型大规模地聚合和改进混合质量的标签 。 图源:https://arxiv.org/pdf/1711.10160.pdf
这种方法令人联想到数据库管理系统的数据融合 , 将其应用到机器学习是一个支点和再设计 , 而不是仅仅针对 ML 的革命性创造 。 通过确认系统和 ML 领域的共有问题 , 并结合数据来源 , 传统的系统技术可以应用于机器学习设置中 。
数据验证
数据验证是数据收集的后续操作 。 数据质量是机器学习 pipeline 中的关键问题 。 维护者如果想要为自己的系统生成高质量模型 , 则必须保证输入的数据也是高质量的 。
调整机器学习方法并不能轻易地解决这一问题 , 因而需要对 ML 系统进行调整 。 幸运的是 , 虽然机器学习的数据验证是一个新问题 , 但数据验证不是 。
引用 TensorFlow 数据验证(TFDV)相关论文《 Data Validation for Machine Learning 》中的表述:
数据验证既不是一个新问题 , 也不是机器学习独有的 , 所以我们可以借鉴数据库系统等相关领域中的解决方案 。 但是 , 我们认为数据验证在机器学习场景中面临着独特的挑战 , 因而需要重新思考现有解决方案 。再一次 , 通过确认机器学习系统和传统计算机系统之间的并行挑战 , 我们可以通过一些机器学习导向的修改来重新利用现有解决方案 。
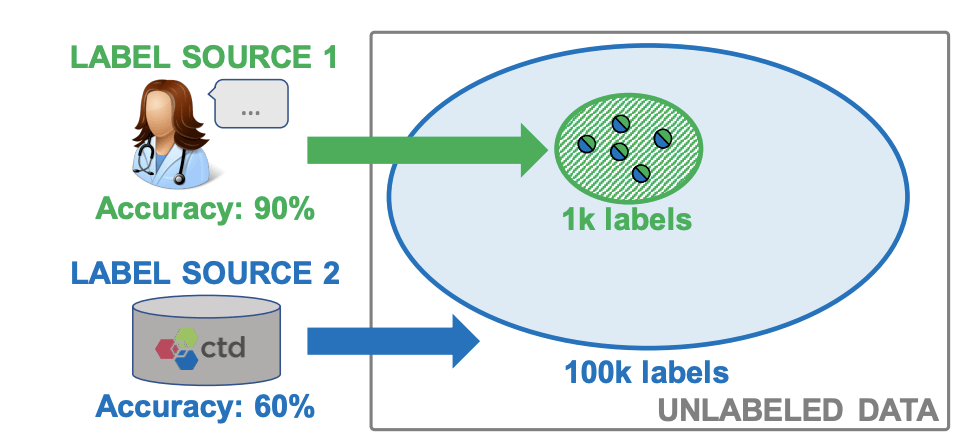
TFDV 的解决方案使用了数据管理系统中久经验证的解决方案——schemas 。 一个数据库强制执行属性以确保数据输入和更新遵循指定的格式 。 同样地 , TFDV 的数据模式系统也对输入至模型的数据强制执行一些规则 。
文章图片
TFDV 的用于 ML 数据验证的模式系统使用户可以避免生成系统中数据馈送的异常现象 。 图源:https://mlsys.org/Conferences/2019/doc/2019/167.pdf
当然会有一些不同的地方 , 反映出了机器学习系统与传统范式的区别 。 ML 模式不仅需要与时俱进和实时调整以适应分布变化 , 而且需要考虑系统生命周期中模型自身可能出现的变化 。
模型训练
ML 从业者可能感到惊讶的是将模型训练作为系统优化的一个领域 。 毕竟 , 如果机器学习应用中有一个领域真正依赖 ML 技术 , 那就是训练 。 但即使这样 , 系统研究依然可以发挥作用 。
以模型并行化为例 , 随着 Transformer 崛起 , 各种应用 ML 领域在模型尺寸方面都出现了显著增加 。 几年前 , BERT-Large 模型的参数达到了 3.45 亿 , 现在 Megatron-LM 增加到了 1 万亿以上 。
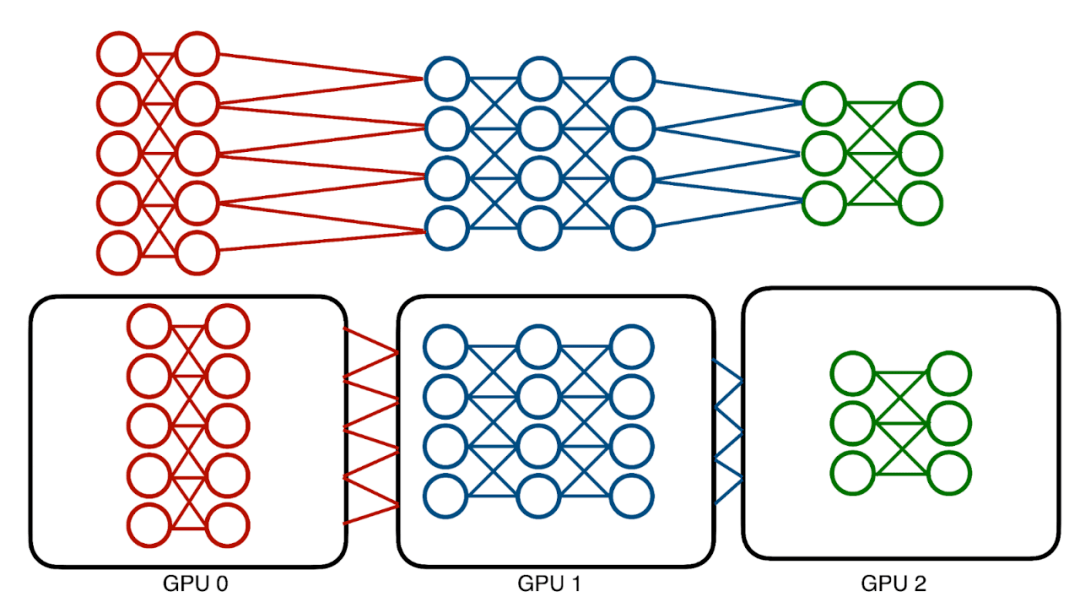
这些模型的内存成本已经达到了数百 GB , 没有一个 GPU 可以 hold 它们 。 传统解决方案——模型并行化采用了一种相对简单的方法 , 即在不同的设备上对模型进行划分以分配相应的内存成本 。
文章图片
传统模型并行化受到神经网络架构序列性的影响 。 高效的并行化计算机会是有限的 。
但是 , 这种技术也存在问题 , 即模型本质上是连续的 , 并且训练模型需要在层间前向和后向地传递数据 。 因此 , 每次只能使用一个层和一个设备 。 这种情况将导致设备利用严重不足 。
系统研究如何发挥助力作用呢?
以一个深度神经网络为例 , 如果将其分解为最小的组件 , 则它可以被视为一系列转换数据的算子 。 简单地训练意味着这样一个过程:通过算子传递数据 , 产生梯度 , 再次通过算子将梯度反馈回来 , 最后更新算子 。
在这个层次分解之后 , 模型开始类似于其他阶段式操作 , 比如 CPU 的指令 pipeline 。 谷歌于 2019 年在论文《 GPipe: Easy Scaling with Micro-Batch Pipeline Parallelism 》中提出的 GPipe 系统和分布式任务处理系统 Hydra 试图通过这种 CPU 并行指令将系统优化应用于可扩展性和并行性实现 。
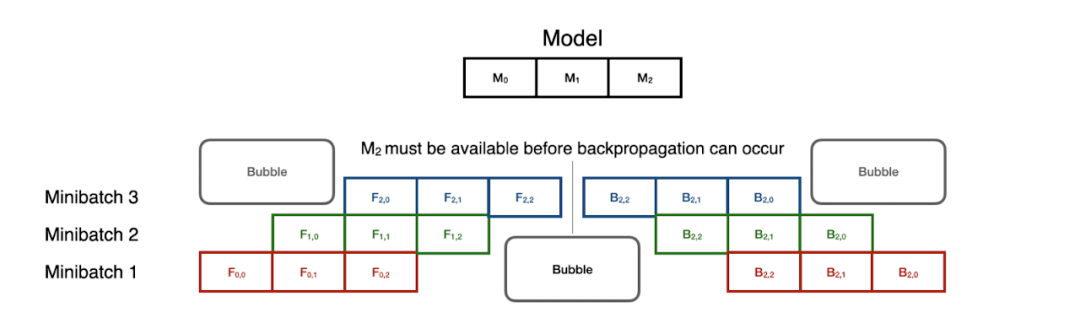
其中 , GPipe 系统通过这种 CPU 并行指令将模型训练转变成了一个 pipeline 问题 。 模型的每个分区都被视为一个 pipe 的不同阶段 , 并且 mini-batch 通过分区进行分级以实现利用效果最大化 。
文章图片
序列模型并行化中的 SOTA——pipeline 并行化可以并行处理 mini-batch 的训练 。 但是 , 同步开销非常高 , 尤其是在前向和后向传递的转换过程中 。
但是请注意 , 反向传播通过相反的顺序复用这些阶段 。 这意味着:在前向 pipeline 完全畅通之前 , 反向传播无法启动 。 即便如此 , 这种技术可以将模型并行训练加速至一个很好的水平 , 在 8 个 GPU 时速度提升 5 倍 。
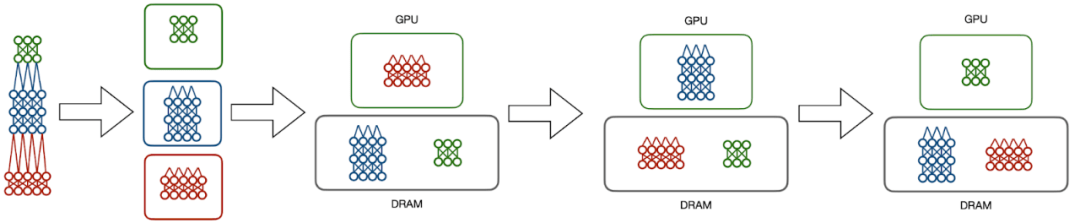
Hydra 则采用了另外一种方法 , 它将可扩展性和并行性分割为两个不同的步骤 。 数据库管理系统中的一个常见概念是溢出(spilling) , 多余数据被发送至内存层级结构的较低层次 。 Hydra 充分利用模型并行中的序列计算 , 并观察到不活跃的模型分区不需要在 CPU 上处理 。 相反 , Hydra 将不需要的数据溢出至 DRAM , 在 GPU 上间断性地切换模型分区 , 以模拟传统的模型并行执行 。
文章图片
【模型|连通系统与机器学习的 MLOps 挑战在哪?这篇文章讲清楚了】Hydra 的模型溢出技术将深度学习训练的成本转移至 DRAM 而不是 GPU 内存 , 同时保持了 GPU 执行的加速优势 。
这样一来 , 一次只使用一个 GPU 就可以训练模型 。 因此 , 在顶端引入一定程度的任务并行性很简单 。 每个模型 , 无论它的大小如何 , 一次只需要一个 GPU , 这样系统可以充分利用每个 GPU 。 在 8 个 GPU 时可以实现 7.4 倍以上的近乎最优加速 。
但是 , 模型并行只是系统研究为模型训练所能带来的开始 , 其他有潜力的贡献包括数据并行(如 PyTorch DDP)、模型选择(如 Cerebro 或模型选择管理系统)、分布式执行框架(Spark 或 Ray)等 。 模型训练是系统研究优化的成熟领域 。
模型服务
归根结底 , 构建机器学习模型最终是为了使用 。 模型服务与预测是最重要的机器学习实践领域之一 , 也是系统研究产生最大影响的领域之一 。
预测可以划分为两个主要设置:离线部署和在线部署:
- 离线部署相对更加直接 , 它涉及到单一的、不定期运行的大批量预测工作 。 常见的设置包含商业智能、保险评估和医疗健康分析;
- 在线部署属于网络应用 , 如果用户想要自己的查询得到快速响应 , 则需要快速、低延迟的预测 。
系统研究已经重新塑造了处理离线和在线部署任务的方式 。 以加州大学圣地亚哥分校的研究者在论文《 Incremental and Approximate Computations for Accelerating Deep CNN Inference 》中提出的 Krypton 工具为例 , 它将视频分析重新视作一项「多查询优化任务(multi-query optimization, MQO)」任务 。
MQO 不是一个新的领域 , 它是数十年来关系数据库设计的一部分 。 总体思路很简单:不同的查询可能共享相关组件 , 然后可以保存和复用这些组件 。 Krypton 工具观察到 , CNN 推理通常是在批量相关图像上完成 , 比如在视频分析中 。
一般来说 , 视频是以高帧率生成 , 这样一来 , 相邻帧往往相对一致 。 帧 1 中的大部分信息依然出现在帧 2 中 。 这种情况与 MQO 明显相同 , 即一系列任务之间共享信息 。
Krypton 在第一帧上运行常规推理 , 然后具象或保存 CNN 在预测过程中产生的中间数据 。 随后的图像与第一帧进行比较以确定图像中的哪些 patch 产生的变化足以值得重新计算 。 一旦确定了 patch , Krypton 通过 CNN 计算 patch 的「变化域」 , 以确定模型整个状态中哪些神经元输出发生了变化 。 这些神经元会根据变化的数据重新运行 , 其余的数据只需要从基础帧中复用即可 。
结果就是在推理负载上实现 4 倍以上的端到端加速 , 并且过期数据只有很小的准确率损失 。 这种运行时改进对于安全录像视频分析等长时间运行的流媒体应用来说至关重要 。
Krypton 并不是唯一一个专注于模型推理的工具 。 加州大学伯克利分校的研究者在论文《 Clipper: A Low-Latency Online Prediction Serving System 》中提出的 Clipper 和 TensorFlow Extended 等其他工具利用系统优化和模型管理技术提供高效和鲁棒的预测 , 从而解决了同样的高效预测服务问题 。
原文链接:
https://thegradient.pub/systems-for-machine-learning/
推荐阅读







- 智能化|龙净环保:智能型物料气力输送系统的研究及应用成果通过鉴定
- 识别|天津滨海机场RFID行李全流程跟踪系统完成建设 行李标签识别成功率可提升至99%
- 最新消息|IT系统出错 英国银行给7.5万人多发11亿工资
- IT|新航空图像拍摄系统Microballoon:可重复使用且成本更低
- 公司|赣锋锂业智能立体仓储系统正式运行
- 系统验证|以技术革新加速芯片创新效率,EDA软件集成版PNDebug正式发布
- 高通骁|一加 10 Pro 现身 Geekbench:搭载高通骁龙 8,运行安卓 12 系统
- 公测|13款vivo、iQOO手机今日推送OriginOS Ocean公测版系统
- 项目|航天长峰国家重点研发计划项目“ECMO系统研发”原理样机联调成功
- Intel|英特尔正为Linux 5.17准备PFRUT:升级系统固件无需重启