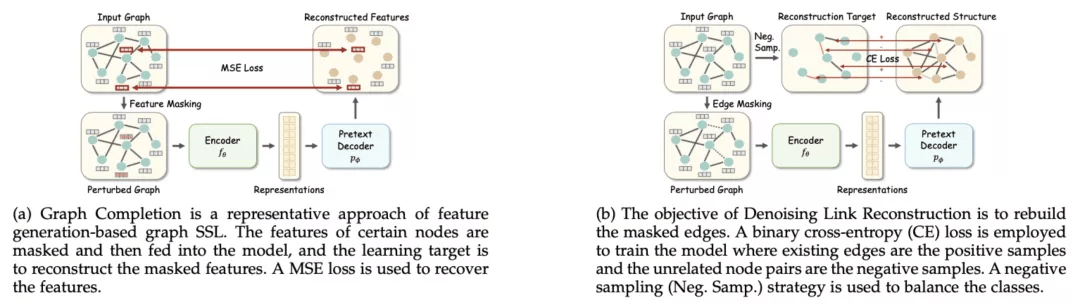
基于生成的方法主要通过重构输入数据以获取监督信号 。 根据重构的对象不同 , 本文将该类方法进一步细分为两个子类:特征生成和结构生成 。
文章图片
基于生成的图自监督学习
特征生成方法通过代理解码器对特征矩阵进行重构 。 模型的输入为原始图或者经过扰动的图数据 , 而重构对象可以是节点特征矩阵 , 边特征矩阵 , 或者经过 PCA 降维的特征矩阵等 。 对应的自监督损失函数一般为均方误差(MSE) 。 比较有代表性的方法为 Graph Completion , 该方法对一些节点的特征进行遮盖 , 其代理任务的学习目标为重构这些被遮盖的节点特征 。
结构生成方法起源于经典的图自编码器(GAE) , 一般采用基于表征相似度的解码器对图的邻接矩阵 A 进行重构 。 由于邻接矩阵的二值性 , 对应的损失函数一般为二分类交叉熵(BCE);而由于邻接矩阵的稀疏性 , 一般采用负采样等手段实现类别平衡 。
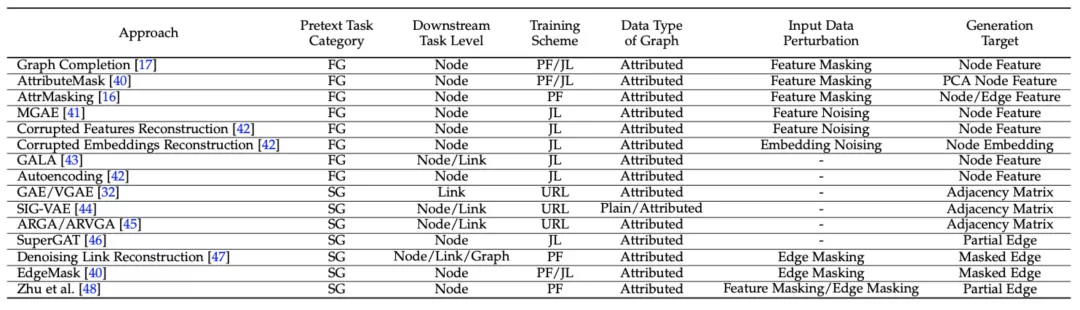
本文对现有的基于生成的图自监督学习方法进行了总结 , 如下表所示:
文章图片
B.基于属性的图自监督学习方法
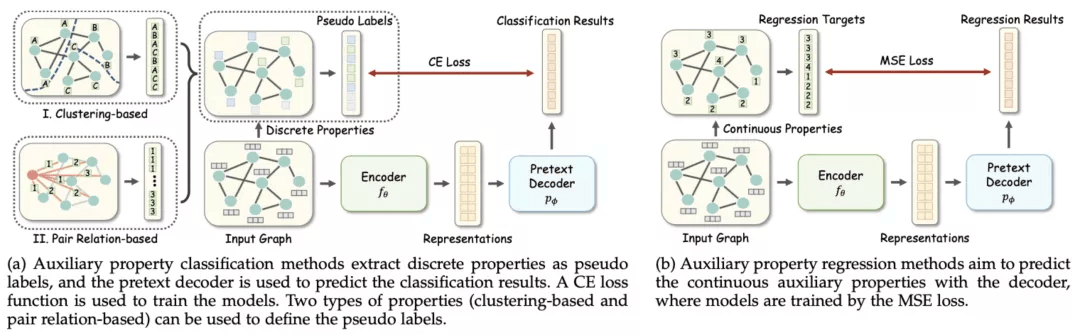
基于属性的方法从图中自动获取一些有用的属性信息 , 以此作为监督信号对模型进行训练 。 这类方法在形式上与监督学习比较类似 , 都是采用 “样本 - 标签” 的数据模式进行学习 , 其区别在于这里的 “标签” 信息为伪标签 , 而监督学习所用的为人工标签 。 根据监督学习的分类模式 , 本文将该类方法细分为两个子类:属性分类和属性回归 。
文章图片
基于属性的图自监督学习
属性分类方法自动地从数据中归纳出离散的属性作为伪标签 , 作为代理任务的学习目标供模型学习 , 对应的损失函数一般为交叉熵 。 通过获取伪标签的手段不同 , 该类方法可进一步分为:1)基于聚类的属性分类:2)基于点对关系的属性分类 。 前者采用基于特征或结构的聚类算法的对节点赋予伪标签 , 而后者则是通过两个点之间的关系得到一个点对的伪标签 。
属性回归方法从数据中获取连续的属性作为伪标签 , 对应的损失函数为均方误差(MSE) 。 一个典型的例子是提取节点的度(degree)作为其属性 , 通过代理编码器对该特性进行回归 , 实现对模型的自监督训练 。
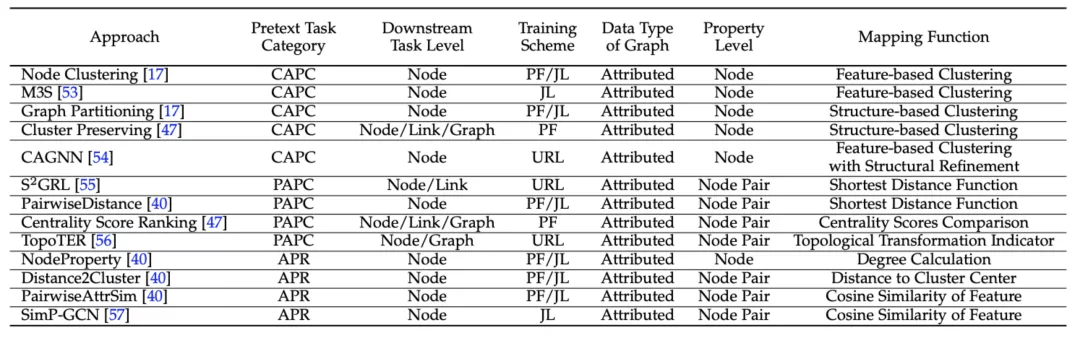
该类别方法的总结如下表所示:
文章图片
C.基于对比的图自监督学习方法
推荐阅读







- 文章|美媒文章:古人类领域2021年六大新突破
- 核心|中科大陈秀雄团队成功证明凯勒几何两大核心猜想,研究登上《美国数学会杂志》
- 器件|6G、量子计算、元宇宙…上海市“十四五”聚焦这些前沿领域
- 领域|上海市电子信息产业“十四五”规划:以集成电路为核心先导
- VIA|x86研发团队卖给Intel后 VIA出售厂房和设备:北美分部就此终结
- 前瞻|6G、量子计算、元宇宙……上海市“十四五”聚焦这些前沿新兴领域
- 团队|深信院41项科研项目亮相高交会 11个项目获优秀产品奖
- 产品|数梦工场通过CMMI V2.0 L5评估,再获全球软件领域最高级别认证加冕
- 团队|玉米和水稻基因组引导编辑效率提高3倍
- 电磁场|首届全国颠覆性技术创新大赛领域赛(青岛)举办