
文章图片
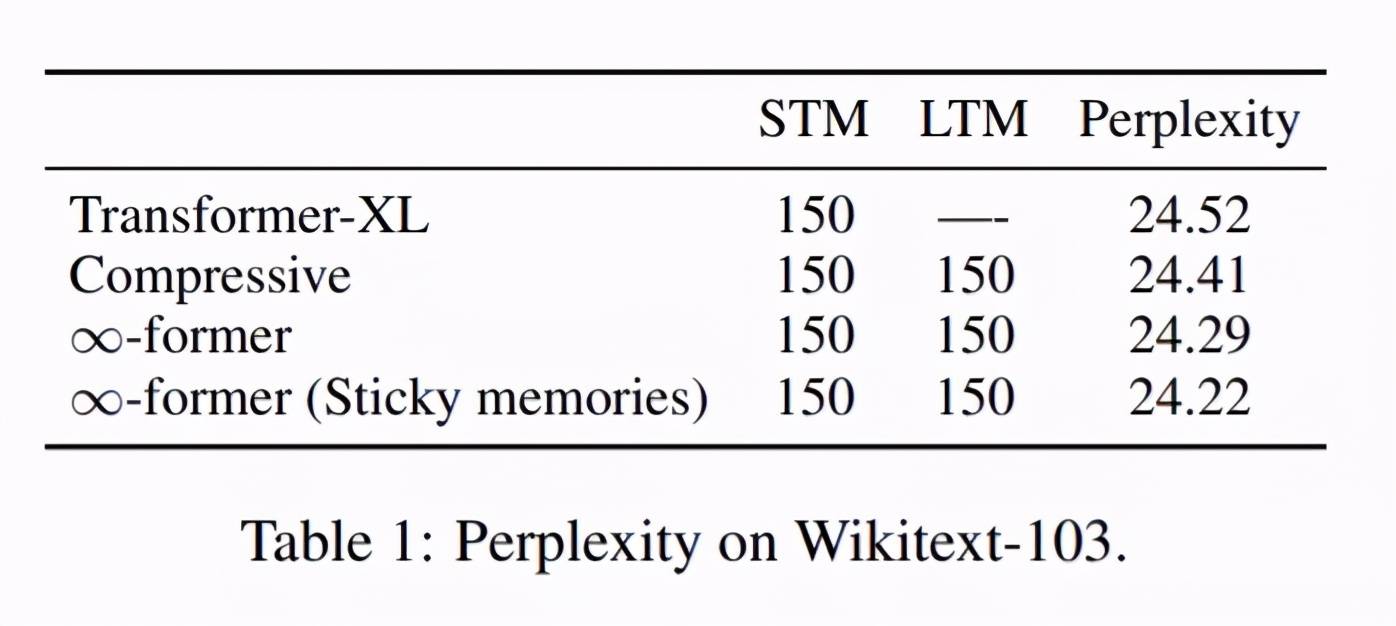
为了缓解损失较早记忆 resolution 的问题 。 研究者引入了「粘性记忆」的概念 , 将 LTM 新信号中的较大空间归于之前记忆信号的相关区域 。 这是一种强制重要信息在 LTM 中持续存在的过程 , 使得模型可以在不损失相关信息的情况下更好地捕捉长上下文 , 类似于大脑中的长时程增强和突触可塑性 。
实验结果
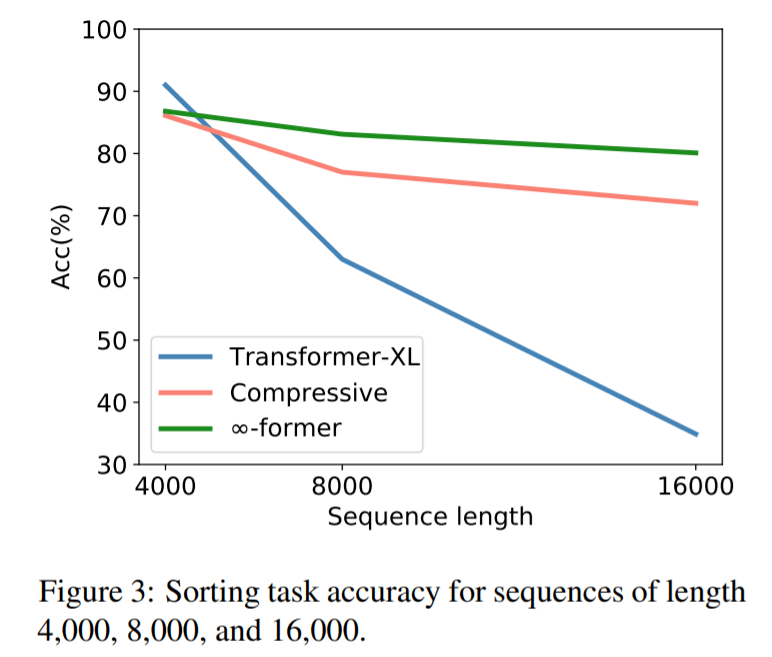
为了检验∞-former 能否建模长上下文 , 研究者首先针对一个综合任务进行了实验 , 包括把 token 按其在一个长序列中的频率进行排序 , 结果如下:
文章图片
从图中可以看出 , 在序列长度为 4000 的时候 , transformerXL 的准确率要略高于 compressive transformer 和 ∞-former 。 这是因为 transformerXL 几乎可以在记忆中保存整个完整序列 。 但随着序列长度的增加 , transformerXL 的准确率迅速下降 , compressive transformer 和 ∞-former 变化较小 。 这表明∞-former 更擅长建模长序列 。
接下来 , 他们又进行了语言建模实验 , 包括:1)从头训练一个模型;2)微调一个预训练语言模型 。
第一个语言建模实验的结果如下表 1 所示 。 从中可以看出 , 利用长期记忆扩展模型确实会带来更好的困惑度结果 , 而且使用粘性记忆也可以在一定程度上降低困惑度 。
文章图片
第二个语言建模实验的结果如下表 2 所示 。 该结果表明 , 通过简单地将长期记忆添加至 GPT-2 并进行微调 , 模型在 Wikitext-103 和 PG19 上的困惑度都会降低 。 这表明∞-former 具有多种用途:既可以从头开始训练模型 , 也可以用于改进预训练模型 。
【信息|Transformer又出新变体∞-former:无限长期记忆,任意长度上下文】
文章图片
推荐阅读







- 建设|这一次,我们用SASE为教育信息化建设保驾护航
- 硬件|又一28nm晶圆厂计划浮出水面 但困难重重
- 领域|上海市电子信息产业“十四五”规划:以集成电路为核心先导
- Tencent|微信小程序新规则:调用个人敏感信息将需授权
- 接口|微信小程序用户信息相关接口调整
- 梦芯|梦芯科技:精准时空信息赋能汽车技术创新发展
- 海康威视|智能家居战场又添一员,海康威视分拆萤石网络上市,半年营收20亿 | IPO见闻
- 人物|继“年度恶人”之后 扎克伯格又被批“殖民”夏威夷
- 解决方案|德国又一州“去微软化”失败,将继续使用 Microsoft Teams
- 手机|又一台Realme XT手机在印度起火 公司正在调查此事