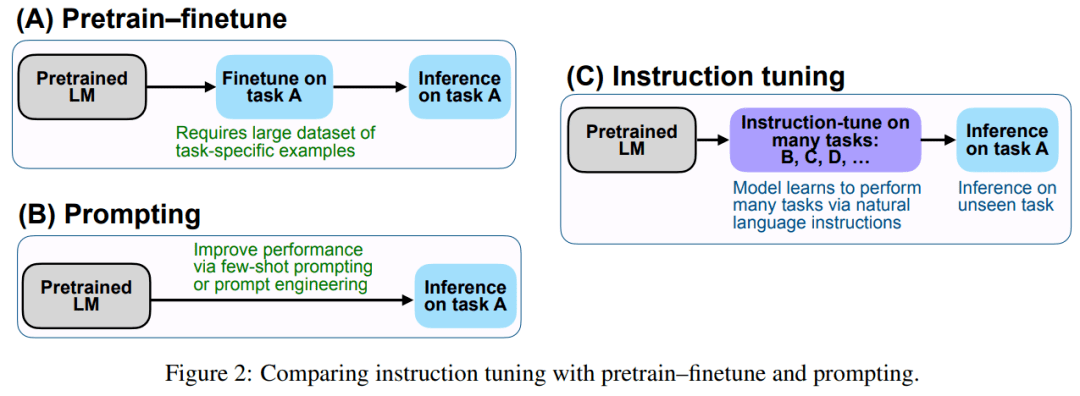
该研究实证结果强调了语言模型使用自然语言指令描述任务的能力 。 更广泛地说 , 如图 2 所示 , 指令调整结合了预训练微调(pretrain–finetune)特点 , 并通过使用 finetune 监督来提高语言模型响应推理时文本交互的能力 。
文章图片
FLAN:用指令调整改进零样本学习
指令调整的动机是提高语言模型响应 NLP 指令的能力 , 旨在通过使用监督来教 LM 执行以指令描述的任务 。 语言模型将学会遵循指令 , 即使对于未见过的任务也能执行 。 为了评估模型在未见过的任务上的性能 , 该研究按照任务类型将任务分成多个集群 , 当其他集群进行指令调整时 , 留出一个任务集群进行评估 。
任务和模板
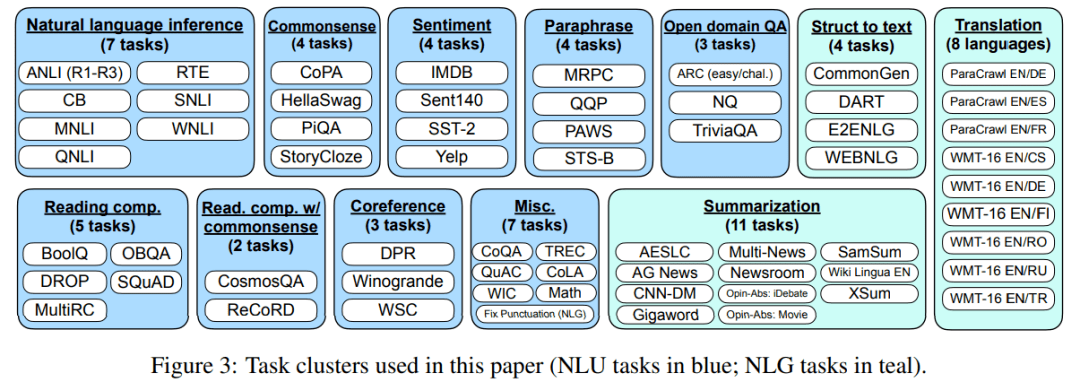
该研究将 62 个在 Tensorflow 数据集上公开可用的文本数据集(包括语言理解和语言生成任务)聚合到一起 。 下图 3 显示了该研究使用的所有数据集;每个数据集被归类为十二个任务集群之一 , 每个集群中的数据集有着相同的任务类型 。
文章图片
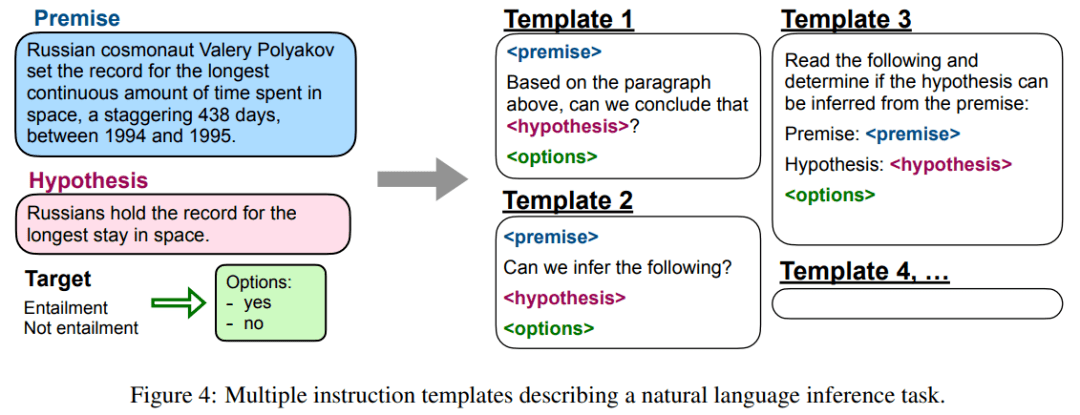
【参数|零样本性能超越小样本,谷歌1370亿参数新模型比GPT-3更强】该研究将任务定义为由数据集给出的一组特定的输入 - 输出对 。 对于每个任务 , 研究者手动编写十个独特的模板 , 使用自然语言指令描述任务 。 十个模板大多描述的是原始任务 , 但为了增加多样性 , 研究者为每个任务 , 提供了最多三个「变更任务(turned the task around)」的模板 , 下图 4 给出了自然语言推理任务的多个指令模板 。
文章图片
训练细节
模型架构和预训练 。 在实验中 , 该研究使用密集的从左到右、仅解码器、137B 参数的 transformer 语言模型 。 该模型在一组网络文档(包括含计算机代码的文档)、对话数据和 Wikipedia 上进行预训练 , 这些文档使用 SentencePiece 库 (Kudo & Richardson, 2018) , 被 tokenize 为 2.81T BPE token 和 32K token 的词表 。 大约 10% 的预训练数据是非英语的 。 这个数据集不像 GPT-3 训练集那么干净 , 而且还混合了对话和代码 。
实验结果
研究者分别在自然语言推理、阅读理解、开放域问答、常识推理、共指消解和翻译等多项任务上对 FLAN 的性能进行了评估 。 对于每一项任务 , 他们报告了在所有模板上性能的平均和标准误差 , 这代表了给定典型自然语言指令时 FLAN 的预期性能 。
自然语言推理任务
下表 1 展示了不同模型自然语言推理测试的结果 , 其中给定一个前提与假设——模型必须确认在给定前提为真的情况下假设也为真 。 可以看到 , FLAN 在所有情况下均表现出强大的性能 。
推荐阅读







- 数字化|零售数字化转型显效 兴业银行手机银行接连获奖
- Apple|法官称苹果零售店搜包和解协议虽不完美,但可继续进行
- 水管|柔性泄水管概述、性能参数
- 影像|京东零售集团CEO辛利军空降小米“跑进2022”活动直播间为米粉送福利
- 样本|国内首个在库运行超百万份生物样本全自动化库落户广州
- 旗舰|小米12系列发布,自研芯片加持,18分钟从零充满电
- 数据|聚焦解决 “卡脖子”问题 三六零旗下国家工程研究中心纳入新序列
- Foxconn|吉利疑与富士康共同成立公司 涉及汽车零部件制造
- 售价|2799 元起,vivo S12 / Pro 明日零点开售
- 第一医院|三明启动“云查房” 让基层百姓“零距离”共享专家医疗服务