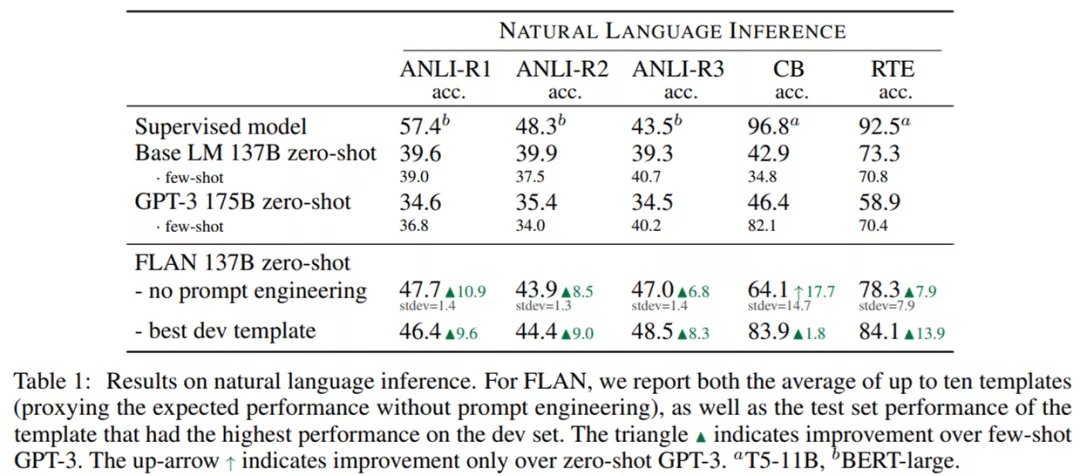
尽管在 CB 和 RTE 的不同模板的结果中存在高方差 , 但 FLAN 在没有任何 prompt 工程时依然在四个数据集上显著优于零样本和小样本 GPT-3 。 在具有最佳 dev 模板时 , FLAN 在五个数据集上优于小样本 GPT-3 。 FLAN 甚至在 ANLI-R3 数据集上超越了监督式 BERT 。
文章图片
阅读理解和开放域问答任务
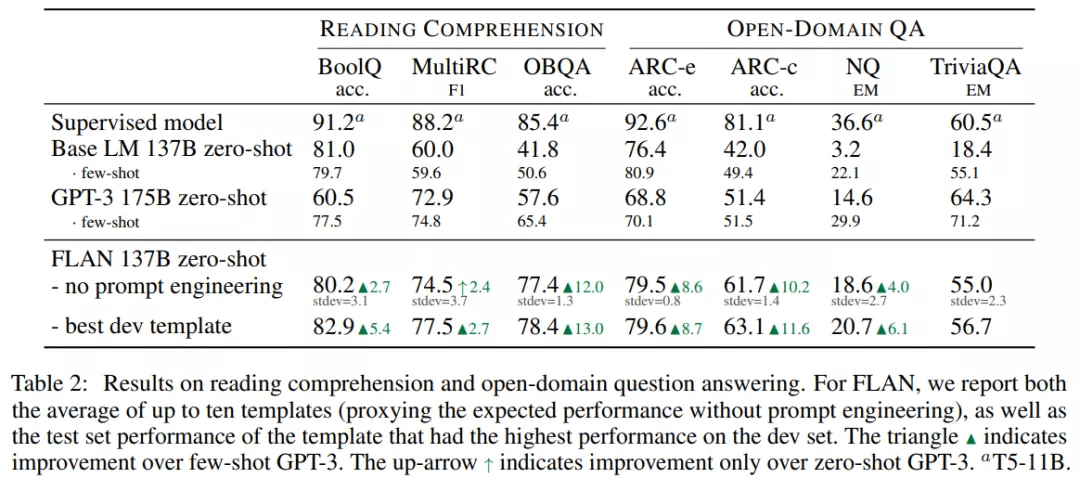
在阅读理解任务上 , 模型被要求回答关于给定文章段落的问题 , 结果如下表 2 所示 。 FLAN 在 BoolQ 和 OBQA 数据集上显著优于 GPT-3 。 在使用最佳 dev 模板时 , FLAN 在 MultiRC 数据集上略优于小样本 GPT-3 。
对于开放域问答任务 , FLAN 在 ARC-easy 和 ARC-challenge 数据集上显著优于零样本和小样本 GPT-3 。 在 Natural Questions 数据集上 , FLAN 优于零样本 GPT-3 , 弱于小样本 GPT-3 。
文章图片
常识推理和共指消解任务
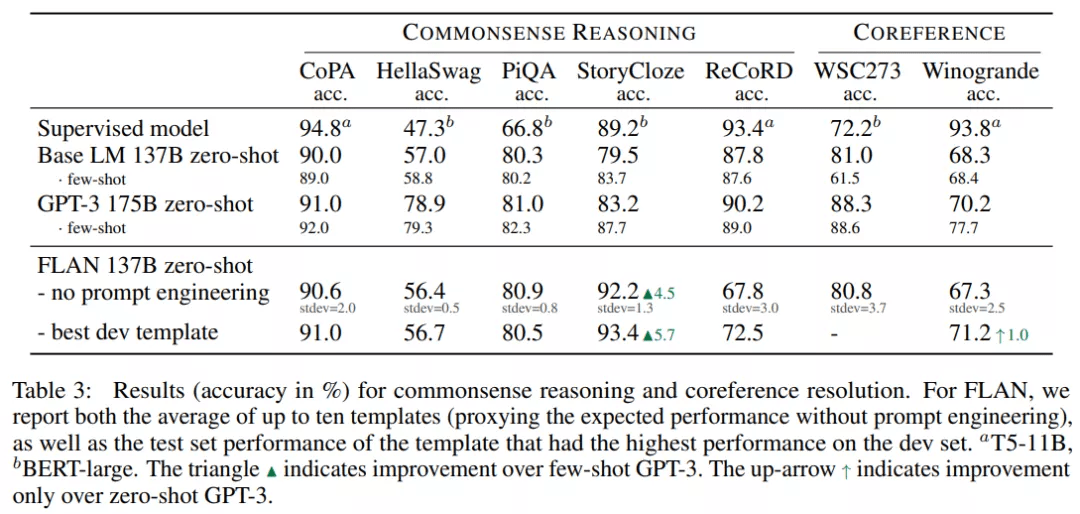
不同模型在五个常识推理数据集上的结果如下表 3 所示 , FLAN 在 StoryCloze 数据集上优于 GPT-3 , 在 CoPA 和 PiQA 数据集上媲美 GPT-3 。 但在 HellaSwag 和 ReCoRD 数据集上 , Base LM 和 FLAN 均弱于 GPT-3 。
在两个共指消解任务上 , 具有最佳 dev 模板的 FLAN 在 Winogrande 数据集上优于零样本 GPT-3 , 但在 WSC273 数据集上 , Base LM 和 FLAN 均弱于 GPT-3 。
文章图片
翻译
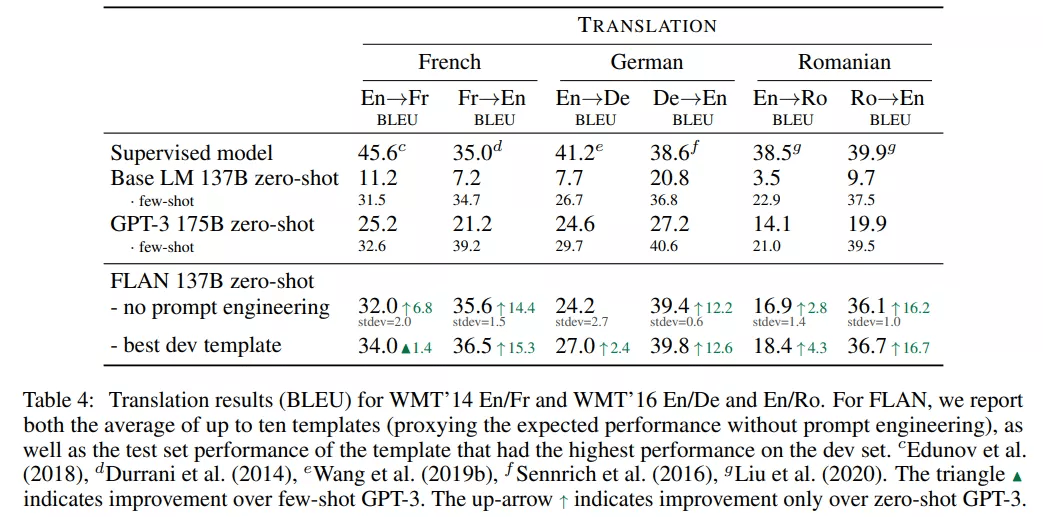
研究者还在 GPT-3 论文中评估的三个数据集上测试了 FLAN 的机器翻译性能 , 这三个数据集分别是 WMT’14 法语 - 英语以及 WMT’16 的德语 - 英语和罗马尼亚语 - 英语 。
测试结果如下表 4 所示 , Base LM 的零样本翻译性能弱 , 但小样本翻译结果媲美 GPT-3 。 FLAN 在六个评估指标中的五个上优于小样本 Base LM 。 与 GPT-3 类似 , FLAN 在翻译成英语任务上展示出了强大的性能 , 并且与监督式翻译基线相比具有优势 。
文章图片
其他实验
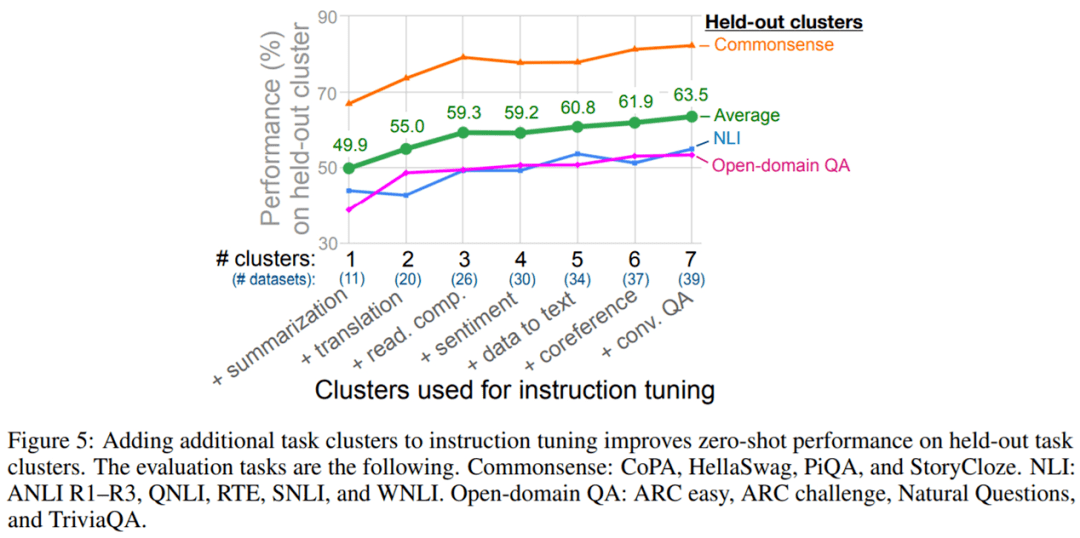
由于该论文的核心问题是指令调整如何提高模型在未见过任务上的零样本性能 , 因此该研究的第一个消融实验研究了指令调整中使用的集群和任务数量对性能的影响 。
图 5 显示了实验结果 。 与预期一致 , 研究者观察到 3 个 held-out 集群的平均性能随着向指令调整添加额外的集群和任务而提高(情感分析集群除外) , 证实了所提指令调整方法有助于在新任务上提升零样本性能 。
文章图片
推荐阅读







- 数字化|零售数字化转型显效 兴业银行手机银行接连获奖
- Apple|法官称苹果零售店搜包和解协议虽不完美,但可继续进行
- 水管|柔性泄水管概述、性能参数
- 影像|京东零售集团CEO辛利军空降小米“跑进2022”活动直播间为米粉送福利
- 样本|国内首个在库运行超百万份生物样本全自动化库落户广州
- 旗舰|小米12系列发布,自研芯片加持,18分钟从零充满电
- 数据|聚焦解决 “卡脖子”问题 三六零旗下国家工程研究中心纳入新序列
- Foxconn|吉利疑与富士康共同成立公司 涉及汽车零部件制造
- 售价|2799 元起,vivo S12 / Pro 明日零点开售
- 第一医院|三明启动“云查房” 让基层百姓“零距离”共享专家医疗服务