机器之心发布
机器之心编辑部
PP-LCNet 在同样精度的情况下 , 速度远超当前所有的骨架网络 , 最多可以有 2 倍的性能优势!算法速度优化遇到瓶颈 , 达不到要求?应用环境没有高性能硬件只有 CPU?
是不是直接戳中了各位开发者的痛点!莫慌 , 今天小编就来为万千开发者破局 。
这个破局点就是:针对 CPU 设备及加速库 MKLDNN 定制的骨干网络 PP-LCNet!
空口无凭 , 上图为证!

文章图片
从上图我们可以看出 , PP-LCNet 在同样精度的情况下 , 速度远超当前所有的骨架网络 , 最多可以有 2 倍的性能优势!它应用在比如目标检测、语义分割等任务算法上 , 也可以使原本的网络有大幅度的性能提升 。
而这个 PP-LCNet 的论文发布和代码开源后 , 也着实引来了众多业界开发者的关注 , 各界大神把 PP-LCNet 应用在 YOLO 系列算法上也真实带来了极其可观的性能收益 。
这时候是不是有小伙伴已经按耐不住也想直接上手试试了?!
小编识趣地赶紧送上开源代码的传送门 。 大家一定要 Star 收藏以免走失 , 也给开源社区一些认可和鼓励 。
地址:https://github.com/PaddlePaddle/PaddleClas
而这个 PP-LCNet 到底是如何设计 , 从而有这么好的性能的呢?下面小编就带大家来领略一下:
PP-LCNet 核心技术解读
近年来 , 很多轻量级的骨干网络问世 , 各种 NAS 搜索出的网络尤其亮眼 。 但这些算法的优化都脱离了产业最常用的 Intel CPU 设备环境 , 加速能力也往往不合预期 。 百度飞桨图像分类套件 PaddleClas 基于这样的产业现状 , 针对 Intel CPU 及其加速库 MKLDNN 定制了独特的高性能骨干网络 PP-LCNet 。 比起其他的轻量级 SOTA 模型 , 该骨干网络可以在不增加推理时间的情况下 , 进一步提升模型的性能 , 最终大幅度超越现有的 SOTA 模型 。
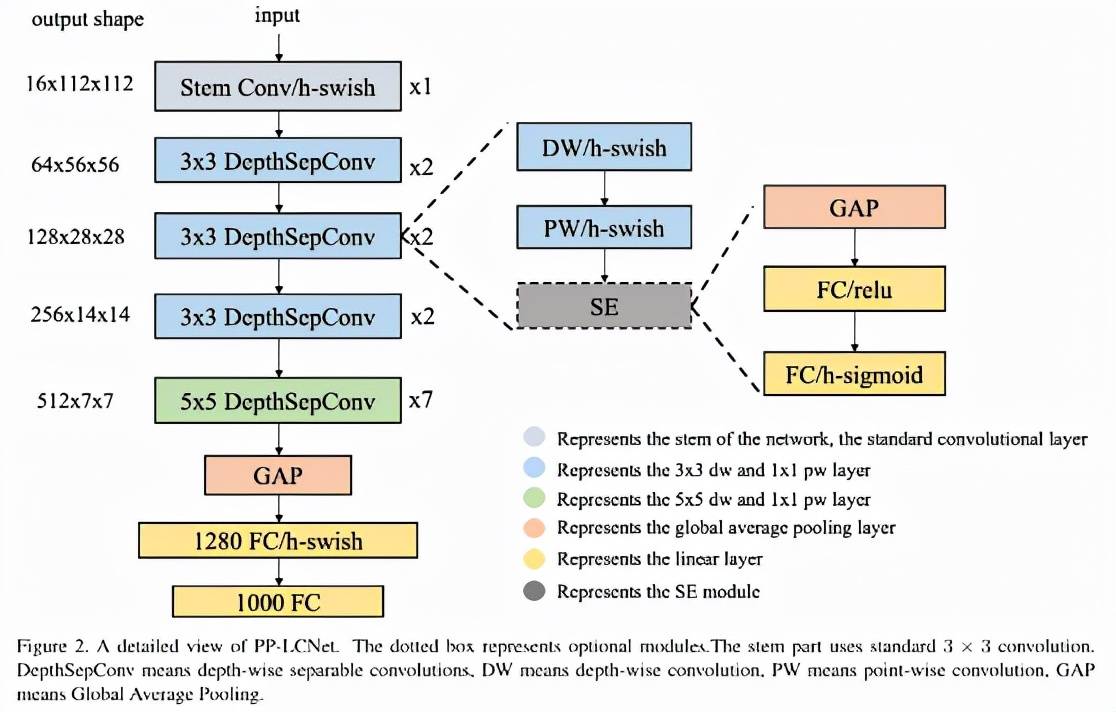
文章图片
PP-LCNet 的网络结构整体如上图所示 。 我们经过大量的实验发现 , 在基于 Intel CPU 的设备上 , 尤其当启用 MKLDNN 加速库后 , 很多看似不太耗时的操作反而会增加延时 , 比如 elementwise-add 操作、split-concat 结构等 。 所以最终我们选用了结构尽可能精简、速度尽可能快的 block 组成我们的 BaseNet(类似 MobileNetV1) 。 基于 BaseNet , 我们通过实验 , 总结出四条几乎不增加延时但又能够提升模型精度的方法 , 下面将对这四条策略进行详细介绍:
更好的激活函数
自从卷积神经网络使用了 ReLU 激活函数后 , 网络性能得到了大幅度提升 。 近些年 ReLU 激活函数的变体也相继出现 , 如 Leaky-ReLU、P-ReLU、ELU 等 。 2017 年 , 谷歌大脑团队通过搜索的方式得到了 swish 激活函数 , 该激活函数在轻量级网络上表现优异 。 在 2019 年 , MobileNetV3 的作者将该激活函数进一步优化为 H-Swish , 该激活函数去除了指数运算 , 速度更快 , 网络精度几乎不受影响 。 我们也经过很多实验发现该激活函数在轻量级网络上有优异的表现 。 所以在 PP-LCNet 中 , 我们选用了该激活函数 。
推荐阅读







- 精度|将建模速率提升10倍,消费级3D扫描仪Magic Swift在2021高交会大显“身手”
- 识别|天津滨海机场RFID行李全流程跟踪系统完成建设 行李标签识别成功率可提升至99%
- 制造业|稳健前行开新局 制造业未来五年转型升级迎来“加速度”
- 设计|宇瞻发布 NOX 系列 DDR5 电竞内存,速度最高 7200MHz
- 周鸿祎|网络安全行业应提升数字安全认知
- 曾学忠|小米手机部总裁曾学忠:希望明年与光弘科技完成智能手机4000万台目标 将引入高端和旗舰项目提升合作规模
- 安全风险|网络安全行业应提升数字安全认知
- 数据|全球5G下载速度普遍下降,韩国、中国等除外
- 东西|手机越用越卡?是这5个东西在拖慢你的手机速度!
- 速度|长江存储发布PCle4.0 固态硬盘致态TiPro7000,顺序读取速度高达7400MB/s