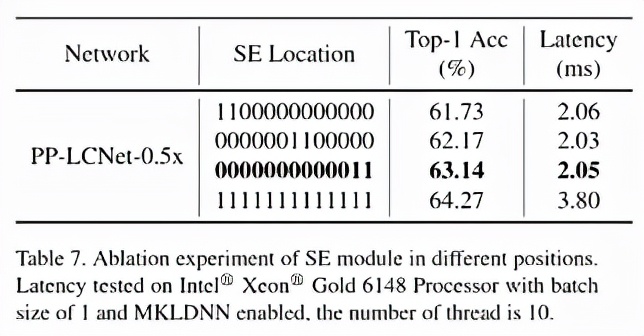
合适的位置添加 SE 模块
SE 模块是 SENet 提出的一种通道注意力机制 , 可以有效提升模型的精度 。 但是在 Intel CPU 端 , 该模块同样会带来较大的延时 , 如何平衡精度和速度是我们要解决的一个问题 。 虽然在 MobileNetV3 等基于 NAS 搜索的网络中对 SE 模块的位置进行了搜索 , 但是并没有得出一般的结论 。 我们通过实验发现 , SE 模块越靠近网络的尾部对模型精度的提升越大 。 下表也展示了我们的一些实验结果:
文章图片
最终 , PP-LCNet 中的 SE 模块的位置选用了表格中第三行的方案 。
更大的卷积核
在 MixNet 的论文中 , 作者分析了卷积核大小对模型性能的影响 , 结论是在一定范围内大的卷积核可以提升模型的性能 , 但是超过这个范围会有损模型的性能 , 所以作者组合了一种 split-concat 范式的 MixConv , 这种组合虽然可以提升模型的性能 , 但是不利于推理 。 我们通过实验总结了一些更大的卷积核在不同位置的作用 , 类似 SE 模块的位置 , 更大的卷积核在网络的中后部作用更明显 , 下表展示了 5x5 卷积核的位置对精度的影响:

文章图片
实验表明 , 更大的卷积核放在网络的中后部即可达到放在所有位置的精度 , 与此同时 , 获得更快的推理速度 。 PP-LCNet 最终选用了表格中第三行的方案 。
GAP 后使用更大的 1x1 卷积层
【速度|速度提升2倍,超强悍CPU级骨干网络PP-LCNet出世】在 GoogLeNet 之后 , GAP(Global-Average-Pooling)后往往直接接分类层 , 但是在轻量级网络中 , 这样会导致 GAP 后提取的特征没有得到进一步的融合和加工 。 如果在此后使用一个更大的 1x1 卷积层(等同于 FC 层) , GAP 后的特征便不会直接经过分类层 , 而是先进行了融合 , 并将融合的特征进行分类 。 这样可以在不影响模型推理速度的同时大大提升准确率 。
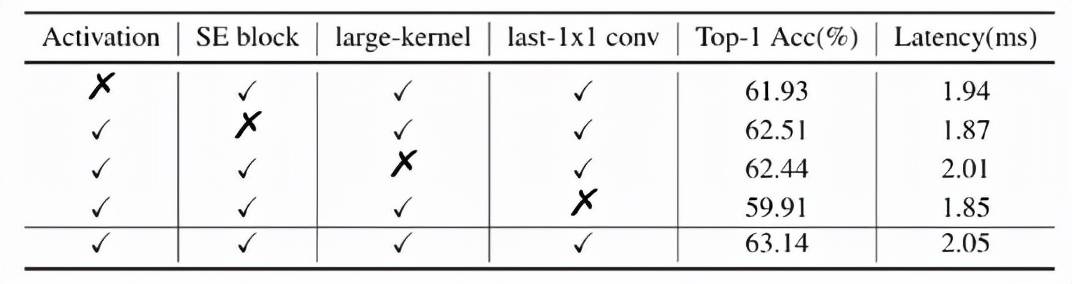
BaseNet 经过以上四个方面的改进 , 得到了 PP-LCNet 。 下表进一步说明了每个方案对结果的影响:
文章图片
下游任务性能惊艳提升
图像分类
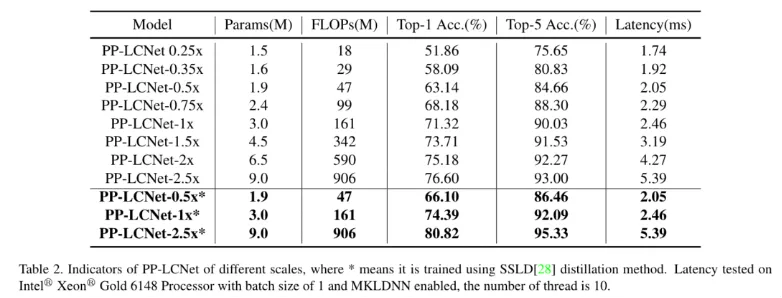
图像分类我们选用了 ImageNet 数据集 , 相比目前主流的轻量级网络 , PP-LCNet 在相同精度下可以获得更快的推理速度 。 当使用百度自研的 SSLD 蒸馏策略后 , 精度进一步提升 , 在 Intel CPU 端约 5ms 的推理速度下 ImageNet 的 Top-1 Acc 竟然超过了 80% , Amazing!!!
推荐阅读







- 精度|将建模速率提升10倍,消费级3D扫描仪Magic Swift在2021高交会大显“身手”
- 识别|天津滨海机场RFID行李全流程跟踪系统完成建设 行李标签识别成功率可提升至99%
- 制造业|稳健前行开新局 制造业未来五年转型升级迎来“加速度”
- 设计|宇瞻发布 NOX 系列 DDR5 电竞内存,速度最高 7200MHz
- 周鸿祎|网络安全行业应提升数字安全认知
- 曾学忠|小米手机部总裁曾学忠:希望明年与光弘科技完成智能手机4000万台目标 将引入高端和旗舰项目提升合作规模
- 安全风险|网络安全行业应提升数字安全认知
- 数据|全球5G下载速度普遍下降,韩国、中国等除外
- 东西|手机越用越卡?是这5个东西在拖慢你的手机速度!
- 速度|长江存储发布PCle4.0 固态硬盘致态TiPro7000,顺序读取速度高达7400MB/s