第一是支持流式数据 。 对分析而言 , 我们对实时性的要求非常高 , 所以我们通过Kafka支持了对实时数据的处理 。 这样通过ByteHouse可以实现对实时和离线的数据提供统一的分析平台 , 支持批流一体 。
第二是计算和存储的分离 。 因为我们的规模实在太大了 , 如何在数十PB新增数据基础上 , 支持数万人 , 高效快速地做千万次的即时查询 , 是一个很大的挑战 。 通过计算和存储的分离 , 我们能更好地解决性能问题 。 分离之后 , 计算层可以单独地进行弹性的扩缩容 。 在存储一块 , 可以和分布式存储系统进行对接 , 包括HDFS、S3等等 。 这样一方面能解决存储的稳定性问题 , 另一方面也能解决扩容问题 。
在计算和存储的分离之外 , 我们在运维、安全方面做了很多工作 , 以进一步去弥补社区版本功能的缺失 。
最后一个很重要的是我们做了多级的资源隔离 。 因为每天有不同的部门、角色在做各种各样的分析 , 那么权限、时效性的要求都不一样 。 那么通过租户的隔离、读写的分离以及异构的计算资源 , 就能很好地满足不同部门、不同角色在大规模集中式地使用资源分配的问题 。
通过以上这五个大的层次上优化 , 所以我们能够基于ByteHouse去支撑起整个字节跳动数据驱动里的核心步骤 。
应用优化
文章图片
刚才讲了数据中台的一些实践 , 接下来再讲讲怎么去通过数据驱动来做应用和业务的优化 。 这里以增长获客来举例 。
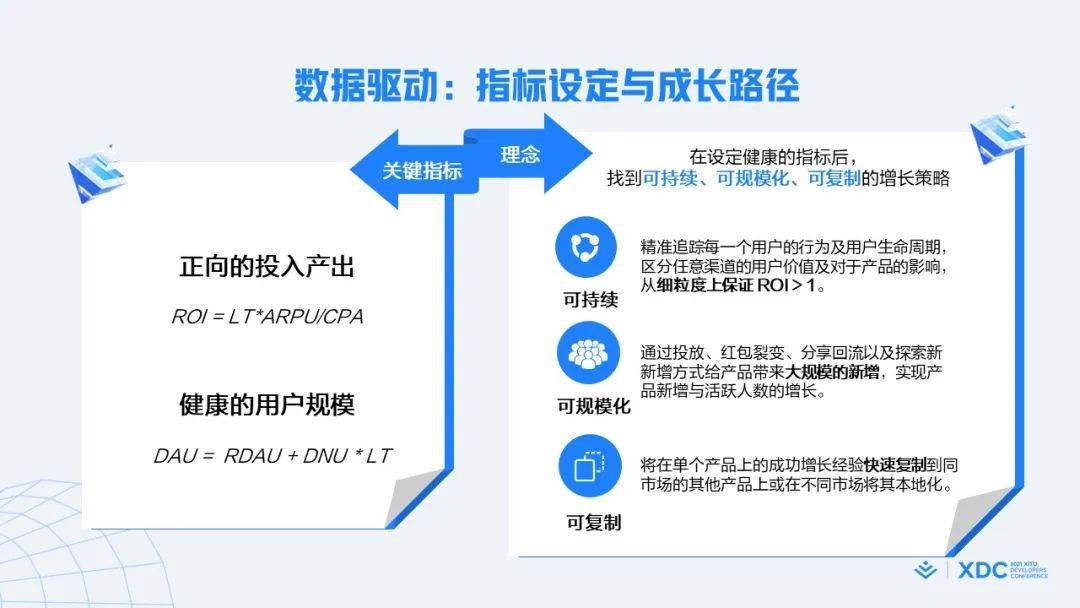
当然不管是增长场景还是其他场景 , 如果要做好数据驱动优化 , 首先最关键的就是设计好指标体系 。 因为指标不对 , 做的再多都是错的 。
那么对于增长而言 , 我们认为最重要的有两个指标——「正向的投入产出」和「健康的用户规模」 。
正向的投入产出 , 简单来说就是ROI>1 。 看起来非常简单 , 但怎么把ROI算对、算准以及精细到每个用户粒度跟进长期的 ROI , 其实是难点和关键 。
当然我们也不能只看短期的ROI , 还要看长期的用户的健康度 , 包括留存 , LT等等 。
设定了这些关键指标之后 , 其实就可以通过指标去找到对应的优化增长策略 。 这个增长策略不仅要满足指标的正向 , 同时也要具备可持续、可规模化、可复制的模式 。 这样就把业务的增长模式转化成了可衡量、可跟踪的数据驱动模式 。
最后用一张图去完整地阐述数据驱动、基于中台和应用优化 , 来构建整体飞轮的案例 。
- 首先基于数据做用户定向 , 定义好目标 , 找到对产品最关键的人群;
- 找到之后 , 去做对应的创意、内容 , 然后让这些最优质最吸引的内容在不同渠道触达到客户 , 形成转换并产生新的数据 。 而且我们有数字化记录的过程 , 能够准确地归因 , 精细化地追踪效果;
推荐阅读
- 区块|面向2030:影响数据存储产业的十大应用(下):新兴应用
- 选型|数据架构选型必读:2021上半年数据库产品技术解析
- 殊荣|蝉联殊荣!数梦工场荣获DAMA2021数据治理三项大奖
- 数据|数智安防时代 东芝硬盘助力智慧安防新赛道
- OriginOS|当硬件驱动力逐渐放缓,手机还能更快吗?
- 技术|悦鲜活高端瓶装鲜奶市占第一 科技驱动营养再升级
- 平台|数梦工场助力北京市中小企业公共服务平台用数据驱动业务创新
- 数据|中标 | 数梦工场以数字新动能助力科技优鄂
- 建设|数据赋能业务,数梦工场助力湖北省智慧应急“十四五”开局
- 市民|大数据、人工智能带来城市新变化 科技赋能深化文明成效
-






