Instinct MI200:首款 6nm 多芯片封装 GPU
除了配备 3DV 的第三代 EPYC 处理器外 , AMD 还推出了迄今为止最强大的 GPU 加速器「AMD Instinct MI200 系列」 。 与基于 RDNA 2 架构、面向消费者的 Radeon 系列 GPU 不同 , AMD Instinct 加速器采用 CDNA 2 架构 , 它专为高性能标量和矢量处理工作负载设计 , 并结合了新的矩阵核心引擎 。
AMD 表示 , 面向数据中心的最新 GPU 的高性能计算 (HPC) 速度将提高 9.5 倍 , AI 工作负载的速度将比竞品 GPU 快 1.2 倍(例如英伟达 GPU) 。 Instinct MI200 是专为数据中心设计的一系列 GPU 中的最新款 , 而非面向游戏和桌面图形处理 。
对于此次更新 , AMD 特别专注于提升双精度浮点运算的性能 , 这就是为什么声称 HPC 的性能改进大于 AI 处理的原因 。 AMD 数据中心 GPU 加速器企业副总裁 Brad McCreadie 表示:「我们的目标是让这款设备在需要双精度运算的最棘手的科学问题上做到非常好 , 这就是我们向前迈出的最大一步 。 」

文章图片
AMD Instinct MI200.
AMD Instinct MI200 系列 GPU 加速器采用双芯片设计 , 由大约 580 亿个晶体管(6nm 制造)组成 。 MI200 将拥有多达 14080 个流处理器 , 组装为 220 个 CU(计算单元) , 具有多达 880 个第二代矩阵内核 , 搭配高达 128GB(8 堆栈)的 1.6GHz HBM2E 显存 , 通过 8192 位的接口 , 实现 3.2 TB/s 的峰值内存带宽 。 MI200 系列还包含多达 8 个第三代 Infinity Fabric 链路 , 在 Instinct MI200 GPU 加速器和 EPYC 处理器之间提供高带宽连接 。

文章图片
AMD Instinct MI200 系列的特性和技术 。
为了构建这些双芯片 GPU 加速器 , AMD 正在使用一种新的封装技术 , 名为「2.5D Elevated Fanout Bridge(EFB)」 。 EFB 是一种超高带宽芯片互连方法 , 可用于标准基板和倒装芯片制造处理器 , 与同类的多芯片互连解决方案相比 , 其成本和复杂性较低 。
Instinct MI250X 将位于 AMD 高性能计算 GPU 堆栈的顶部 , 并具有完整的 220 CU 和 128GB 的 HBM2E 配置 , 还会有一个「标准」的 MI250 模型 , 它在某种程度上减少了 208 个 CU , 总共有 13312 个流处理器 , 但具备相同的内存配置 。
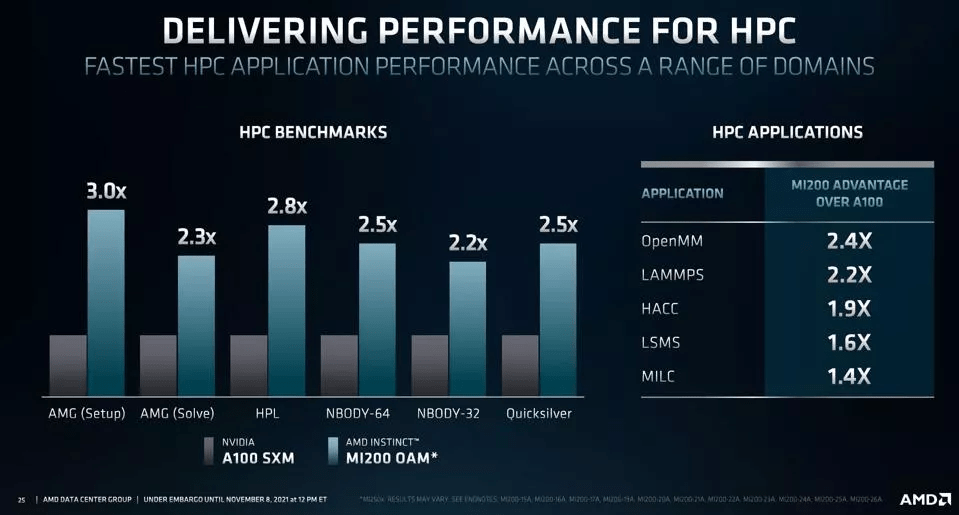
文章图片
AMD Instinct MI200 vs. NVIDIA A100.
在性能方面 , AMD 本次的发布内容依旧令人印象深刻 。 在一系列 HPC 基准测试中 , 将 AMD Instinct MI200 OAM 模块与 NVIDIA 的 A100 SXM 进行对比 , MI200 提供了 2.2 到 3 倍的计算性能 。 在一系列 HPC 应用中 , AMD 发布了类似的内容 , MI200 比 A100 具有 1.4 到 2.4 倍的算力优势 。
推荐阅读







- 星链|石豪:在太空,马斯克和美国当局是如何作恶的
- 快报|“他,是能成就导师的学生”
- 年轻人|人生缺少的不是运气,而是少了这些高质量订阅号
- 生活|气笑了,这APP的年度报告是在嘲讽我吧
- Samsung|三星预告1月11日发布Exynos 2200芯片组 RDNA 2 GPU加持
- Samsung|新渲染揭示Galaxy S22 Ultra几乎就是Galaxy Note复刻版
- 公司|科思科技:正在加速推进智能无线电基带处理芯片的研发
- ASUS|华硕预热ROG Flow Z13:称其是“全球最强悍的游戏平板”
- 视点·观察|科技巨头纷纷发力元宇宙:这是否是所有人的未来?
- 人工智能|聚焦车载人工智能计算芯片研究 推进汽车产业高质量发展