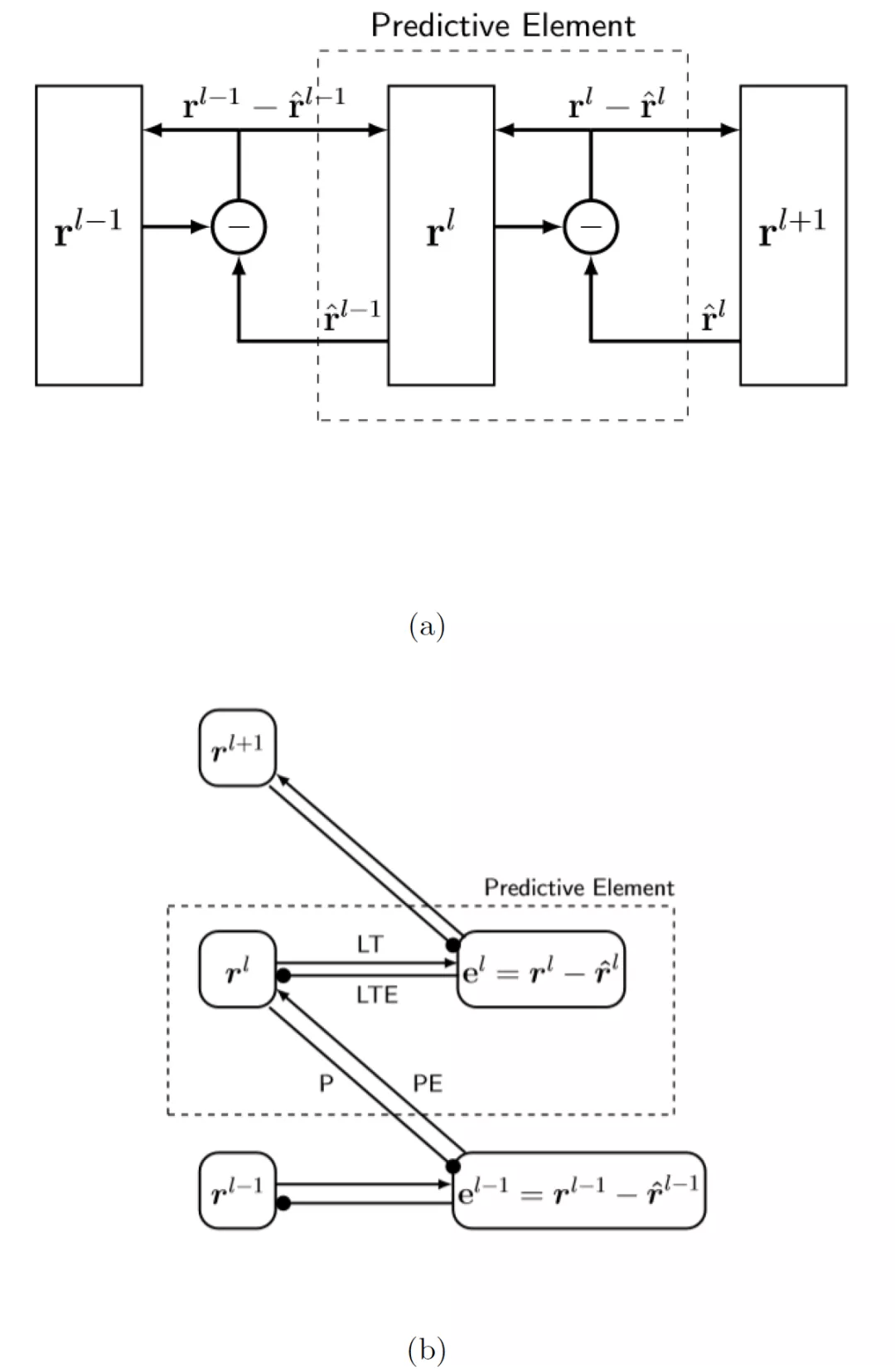
为了方便理解 , 我们给出 PE 的图形化展示 。 将 PE 堆叠成层次结构(图 1(a)) 。 PE 从层次结构中的前一层接收预测误差(通过前向连接) , 并以先验概率的形式(通过后向连接)向前一层发送预测 。 图 1(a)给出信息流的原始视图 。 第 l+1 层学习第 l 层的变换表示 , 从而提高其对第 l 层活动的预测性能 。 r(l)表示输入的假设原因 。 不同的层 l 以越来越高的描述级别提供相同原因的不同表示 。 每一层的表达都表现为形成该层的神经元向量的一组激活水平 。 图 1(b)中的视图显示相邻层之间的交互遵循一个约束协议 , 即 Rao-Ballard 协议 。 在我们的表示中 , 有四种连接类型:预测(prediction , P)、预测误差(prediction error , PE)、横向目标(lateral target , LT)和横向目标误差(lateral target error , LTE) 。 层输出是由 PE 连接提供的信息 。 P 和 PE 为完全连接 , LT 和 LTE 为点对点连接(见图 2) 。 表示模块仅与预测误差模块通信 , 预测误差模块仅与表示模块通信 。 此外 , 预测误差神经元在层次结构中从不向下投射 , 内部表征神经元在层次结构中从不向上投射 。
文章图片
图 1:(a)预测 PE 的 Rao/Ballard 图 。 虚线框中包含的预测元素是预测编码层次结构的构建块 。 围绕减号的圆表示计算预测误差的误差单位向量;(b) 使 Rao-Ballard 协议更加清晰的数据流图 。 e^l 明确预测误差和水平 。 圆箭头表示减法 。 与预测元素关联的四个连接已标记
文章图片
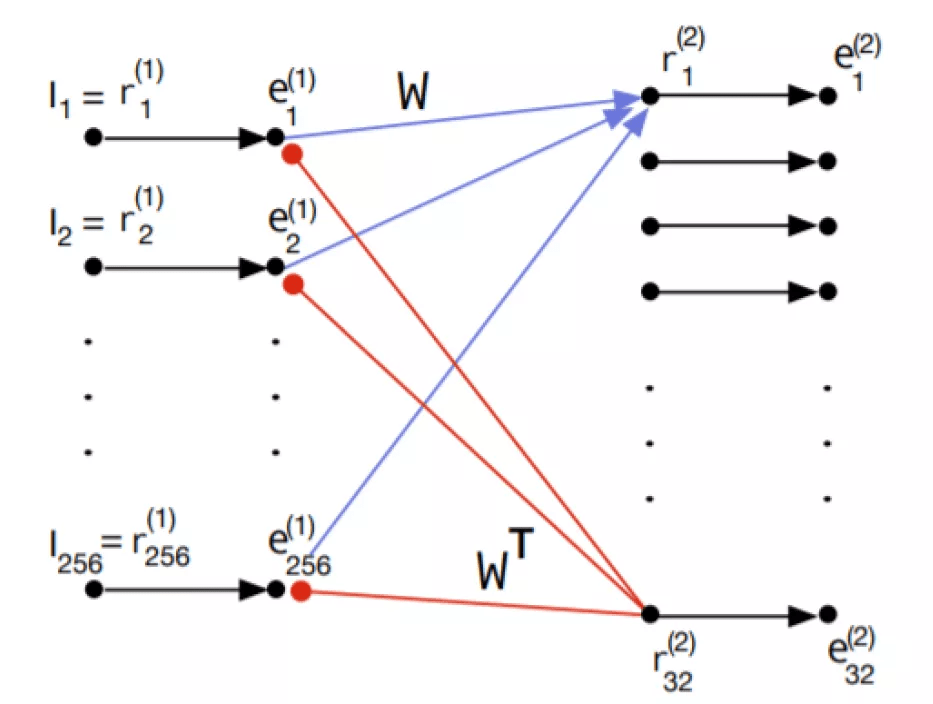
图 2. PE 预测单元 。 e 表示残差单元 , r 表示表征单元 , I 表示输入 。 黑色的小圆圈代表神经元 。 以实心圆结尾的红色箭头表示减法反馈抑制 。 红色箭头表示 P 连接 , 蓝色箭头表示 PE 连接 , 黑色箭头表示 LT 连接
【PredNet|说到深度学习架构中的预测编码模型,还得看PredNet】图 1(b)抛出了一个尚未有答案的问题:第 r^(l-1)层从第 r^(l+1)层中中获得了什么样的层次表示 , 这些层次表示与经典的深度学习模型(如卷积网络)中获得的层次表示相比如何?图 2 示出了 [5] 中模型第一层 PE 的网络级表示 。 为简单起见 , 假定第 2 层中的表示单元 r^(2)为线性 。 在接收层 r^(2)中 , 有两个表示 16x16 大小的图像块的输入像素强度的元素 , 但只有 32 个表示元素 。 前馈连接为蓝色 W , 反馈连接为红色 W^T 。 自上而下的预测 , 表示为 I^ 。 e^(1)单元计算预测误差 。 这些想法与架构处理有关:
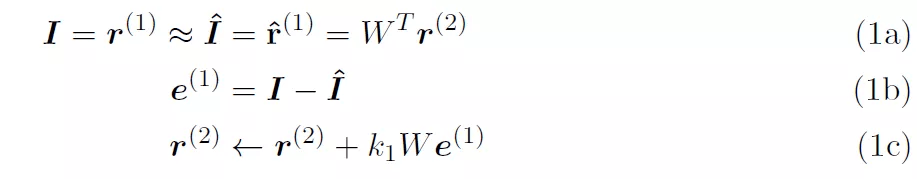
推荐阅读







- MateBook|深度解析:华为MateBook X Pro 2022的七大独家创新技术
- 人物|最有深度的8个公众号,你关注了吗
- 国际|特奖得主任队长,清华夺冠NeurIPS 2021国际深度元学习挑战赛
- 人物|说到做到 俞敏洪首场带货直播卖啥?
- 深度|小米真无线降噪耳机 3 Pro 新年特别版即将发布,带来全新配色等
- 语音|声控智能家居控制系统,就是人与机器的深度交流
- 系列|小米 12 系列确认搭载骁龙 8 Gen 1,已经进行深度调教
- 空间|深度阅读|王赤:从孤独里找到一束光
- 深度|2021百度奖学金十强出炉:已累计投入2000万培养中国顶尖AI人才
- 巨头|国泰君安:折叠屏手机加速渗透 供应链深度受益