本次发布的 ECommerce-T2I 数据集涵盖了服装、饰品、化妆品内的多个商品类目 , 所有数据均来源于真实淘宝电商场景 。 整个数据集由训练集、验证集和测试集组成 。 其中训练集有 9w 张图片 , 验证集和测试集各有 5k 张 。 此外 , 本数据集内的图片均为白底图 , 选手无需额外的精力放在背景生成上 , 主要考查模型对商品文本的理解和生成能力 , 提高物体的生成质量 。
下面是两个样例:
例子一:
- 输入(文本):绵羊毛商务休闲西服套装
- 输出(生成图像):

文章图片
例子二:
- 输入(文本):减震透气跑鞋
- 输出(生成图像):
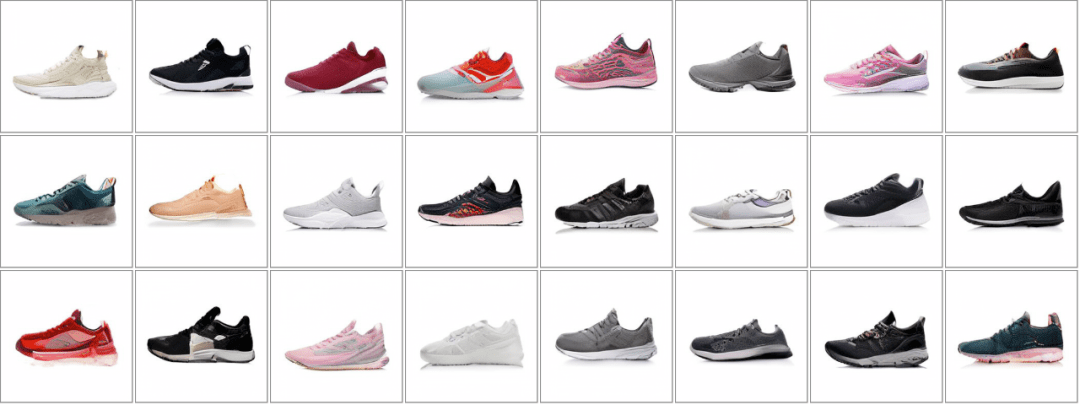
文章图片
Multimodal Retrieval Dataset
多模态检索评价模型进行图文理解和匹配的能力 , 是电商场景中满足用户需求、促成点击交易不可缺少的一环 。 在此次任务中 , 我们准备了来自于淘宝电商平台的真实搜索 query 及商品图 , 要求模型从给定的商品池中检索出与搜索 query 相匹配的商品(样例如下图) 。 为了更好评价模型跨模态理解的效果 , 我们此次不公开商品的标题以及其他信息 , 要求模型仅基于商品图片进行检索召回 , 具有一定的挑战性 。
此次公开的电商图文检索数据集由训练集、验证集和测试集组成 , 其中训练集包含 25w 搜索 query - 商品图构成的图文对 , 涵盖约 12w 商品图片 。 对于验证集和测试集 , 我们各准备了 5k 搜索 query 和 3w 候选商品图片 。 数据集类目涵盖广泛 , 涉及服装、家居、电子、化妆品等多个领域 , 是目前最大的中文全领域电商图文检索数据集 , 对模型的泛化能力提出了考验 。
下面是两个样例:
例子 1:
- 输入(Query):纯棉碎花吊带裙
- 输出:商品图片

文章图片
例子 2:
- 输入(Query):北欧轻奢边几
- 输出:商品图片

文章图片
MUGE 挑战榜
MUGE 的提出旨在解决当前中文多模态领域下游任务数据集匮乏的问题 , 并且为广大研究者提供平台和评测基准去衡量算法模型的有效性 。 此外 , 相较于传统榜单 , MUGE 的覆盖面更全 , 涵盖理解和生成两大类任务 , 并开创性地将基于文本的图像生成纳入其中 。 未来 , MUGE 也会持续地扩增更多的多模态任务及数据规模 , 进一步为研究人员和开发者提升算法模型效果而提供支持 。
推荐阅读







- 区块|面向2030:影响数据存储产业的十大应用(下):新兴应用
- 最新消息|世界单体容量最大漂浮式光伏电站在德州并网发电
- 选型|数据架构选型必读:2021上半年数据库产品技术解析
- 殊荣|蝉联殊荣!数梦工场荣获DAMA2021数据治理三项大奖
- 数据|数智安防时代 东芝硬盘助力智慧安防新赛道
- AirPods|苹果谈论AirPods 3:最大榨取蓝牙技术,希望获得“更多带宽”
- 平台|数梦工场助力北京市中小企业公共服务平台用数据驱动业务创新
- 数据|中标 | 数梦工场以数字新动能助力科技优鄂
- 建设|数据赋能业务,数梦工场助力湖北省智慧应急“十四五”开局
- 市民|大数据、人工智能带来城市新变化 科技赋能深化文明成效