来源:麦叔编程
作者:麦叔

文章图片
Python很强大 , 熟练的程序员可以在5分钟内写出一个有价值的爬虫 , 比如:
- 抓取股票信息
- 抓取笑话
- 抓取商品信息

文章图片
这是一场网站和程序员之间的一种博弈!都是程序员 , 何必呢?程序员何必为难程序员!

文章图片
凡是博弈 , 就一定不易!因为道高一尺魔高一丈 。
你抓他就防 , 你改进抓取方法 , 他就提高防抓手段!
随便你抓 , 岂不是侮辱网站程序员吗?

文章图片
如果有人问你:某某网站能不能抓?
答案肯定是:能!
从技术角度讲 , 只要你能在通过网页上看到的内容 , 就一定能抓!无非就是抓取难度的大小 。
本文总结了实现爬虫时常见的的8个难点 , 以及基本解决思路 。
1. 不小心爬进监狱 从技术手段上讲:天下没有不能抓的网站!
从法律角度上讲 , 有一种说法叫:爬虫写的好 , 牢饭吃的早!我现在还有一个好哥们在里面 , 说到这里两眼都是泪 。

文章图片
正所谓行有行规 , 爬虫有虫规!虫规就是robots.txt 。
robots.txt是网站写给爬虫的声明 , 里面写明了那些内容不能抓取 。 robots.txt一般放在网站的根目录下 。
以B站为例:

文章图片
里面明确了以"/include/" , "/mylist/"等开头的网址不能被抓取 。
说了不能抓就别抓 , 要不然警察把你抓起来!

文章图片
但是国内很多网址不守行规 , 不讲武德 , 网站里根本没有robots.txt 。 那怎么办呢?
可以看几个方面:
- 是否是敏感信息?如果是涉及到私人的敏感信息 , 不要抓 。
- 你抓取的量大不大?一般量不大就没事 , 量大了就要谨慎 。 举个例子:偷10块钱不会坐牢 , 但偷10万块钱肯定可以免费住宿了 。 如果只是抓取自己的商品 , 邮件 , 账单等 , 一般是没有问题的 。
- 你要抓取的网站是谁的网站?有些网站惹不起 , 不要去抓 。 他可以抓你的 , 你不能抓他的 。
2. 复杂多变的网页结构 网页的复杂多变体现在两个方面:
(1)同一个网页在显示不同的内容时会有不同的结构 。 比如商品详情页 , 不同的商品 , 使用不同的网页模板 , 这是很正常的情况 。 再比如商品列表页 , 没有商品 , 有一件商品 , 有多件商品 , 可能样式都会有差别 。 如果你的爬虫只会处理一种情况 , 爬取过程中必然会出现问题 。
(2)网页功能或者设计风格的改变 。 一般的爬虫都是根据网页结构 , 使用xpath去解析内容 , 一旦结构变了 , 就解析不出来了 。

文章图片
怎么解决呢?
- 分析网页结构要全面 , 了解同一个网页的不同情况 。
- 网页结构改了 , 也修改相应的爬虫 。
- 如果要抓的信息比较固定 , 比如抓取电话号码 , 可以使用正则表达式去解析 。 不管网页结构怎么变化 , 一套代码都能搞定 , 正则写的好一点 , 准确度也很高 。
- 还有高端的办法就是使用人工智能的技术 , 让爬虫能够适应网页的变化 , 随便网页变化自己也变化 。
当网站发现某个IP地址发送请求过多的时候 , 会临时或者永久的封锁这个IP的请求 。

文章图片
技术好 , 讲规矩的网站一般提前设置好了规则 , 比如一天只能访问500次 , 或者一分钟内不能访问超过10次 。
当你超过了次数自动封锁你 , 过了时间限制会自动解锁 。
技术不好的网站可能没有这样的规则 , 网站挂了 , 或者管理员发现异常后 , 看日志才发现你请求太多 。
因为它们没有现成的规矩和技术手段 , 它们有可能简单粗暴 , 直接在Web Server上设置永久封锁你的IP地址 。
应对IP封锁的一般手段:
- 不要频繁抓取 , 在两次请求之间设置一定的随机间隔 。
- 摸索网站的规则 , 然后根据规则抓取 。
- 使用IP代理服务 , 不断的更换IP 。 不怕花钱就用收费的IP代理 , 不想花钱就找免费的 。 网上搜索一下 , 免费的也很多 , 只是可能不稳定 。
当你登录网站的时候 , 或者检测到你请求过多的时候 , 网站跳出一个图片 , 要求你输入图片上的内容 。
图片上的内容一般是扭曲的文字 , 甚至是数学公式 , 让你输入计算结果 。

文章图片
这都算是好办的 。 一般使用OCR技术 , 比如Python的Tesserocr库 , 就可以自动识别图片上的内容 , 然后自动填入 , 继续爬取 。
但道高一尺魔高一丈 , 图片验证码也不断的进化和升级 , 比如国外的这种 , 经常把我这个大活人都难哭:

文章图片
或者12306这种:
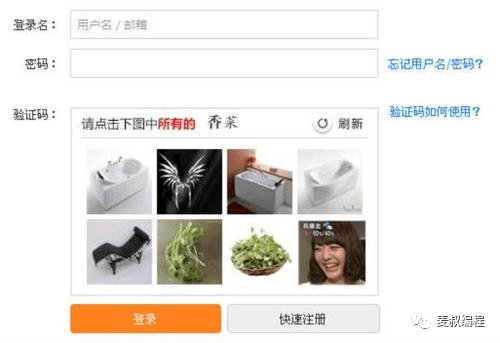
文章图片
简单的OCR技术很难处理这种图片 , 但办法总是有的:
- 人工智能技术之所以叫人工智能 , 就是说它可以跟人一样 , 甚至比人还聪明 。 北大 , 英国的兰卡 , 美国的西北大学的几个研究者就号称用AI研究了一个极快的破解验证码的方法 。
- 使用专业的解码服务 。 有需求就有产品 , 专业的事交给专业的人办 。 有一些公司专门提供相关的服务 , 你调用他们的API或者使用他们的插件解决验证码的问题 。
- 人肉解码:当爬虫运行到验证码的时候 , 暂停 , 等待人工输入验证码 , 然后再继续 。

文章图片
在网站上添加一些链接 , 通过CSS把这些链接设置成人类不可见:
display: none
爬虫解析HTML的时候是能够发现这些链接的 , 于是就点开链接爬进去了 。
一旦爬进去了 , 马上封锁你的IP 。
【网站|搞疯爬虫程序员的8个难点!】解决方法也很简单 , 在解析网页的时候添加一些判断是否可见的逻辑即可 。
6. 网页加载速度慢 有些网站反映速度很慢 。 当请求量大的时候 , 还时不时的会失败 。
这对人来说可能还好 , 耐心等待点 , 刷新一下页面可能就行了 。

文章图片
爬虫也要添加相应的逻辑:
- 设置合理的timeout时间 。 太短网页还没加载完就失败了 , 太长了抓取就会很慢 , 效率太低 。
- 添加自动重试的机制 。 但重试次数一般不要超过5次 。 如果三五次都不行 , 再重试一般也没用的 。 可以下次再来尝试 。
以B站为例 , 视频详情页的HTML页面只有视频的基本信息 , 评论等是后续的Ajax请求获得的 。
文章图片
当我们用爬虫抓取的时候 , 拿到只有第一次的HTML , 后面的内容无法获得 。
尤其最近几年流行前后端分离 , 所有的数据都是通过Ajax获取的 。 拿到的HTML页面只是一个空架子 , 里面什么数据都没有 。
解决的方法一般两个:
- 分析浏览器的网络请求 , 搞清楚后续的请求有哪些 , 然后用爬虫发起同样的后续请求 。
- 使用selenium等浏览器驱动技术 。 因为它们本来就是用程序打开浏览器访问的 , 所以后续的Ajax请求也都有 。
8. 登录请求 有些内容需要登录后才能访问 , 这种情况下请先去看一下本文第1点 , 防止爬进监狱去 。
但如果是自己的账号 , 那一般是没问题的 。
解决方法:
- 如果只是临时抓取某些网站内容 , 可以先手工登录 , 分析浏览器的Cookie , 然后在爬虫请求中加入同样的Cookie 。
- 对于简单的登录网站 , 也可以在脚本中自动填入自己的用户名和密码 , 无须人工干预 。
- 或者当需要输入密码的时候 , 让爬虫暂停 , 人工输入密码后再继续抓取 。

文章图片
这就带来很多的问题 , 随便举几个例子:
- 要抓取的网页数量巨大
- 爬虫顺着链接可能会再爬回自己家
- 很多网页设置了重定向
- 爬取了很多自己不需要的内容
- 爬取回来的数据量巨大
简单的解决方法是使用爬虫框架 , 比如Python里的Scrapy , 它会帮你记录抓了那些 , 那些没抓 , 设置抓取深度和宽度等等 。

文章图片
复杂一点 , 你们需要一个专业的团队 , 使用大数据技术做并发处理和数据处理 。 这是另一个层面的问题了 。
这是我的一点心得和分享 , 不一定全面 。
各位看官大神 , 你还碰到哪些难点?你有哪些解决方法?请留言一下吧 。

文章图片
推荐阅读







- 网站|无法使用?版本号是三位数的Chrome自带“bug”
- 视频网站|会员费涨价后还呼吁电影票要涨价 爱奇艺股价大跌创新低
- 域名|任天堂法务部再出手:五个盗版 Switch ROM 网站被封
- Microsoft|微软Edge浏览器重启Followable标签:可关注网站动态
- 发射|外媒关注:韦布升空开启天文探索新时代_《参考消息》官方网站
- Samsung|三星Galaxy S21 FE现身沃尔玛网站并披露售价
- Xiaomi|Redmi Note 11 Pro+现身FCC认证网站 即将全球发售
- 过程|涛飞网站:建设过程中遇到的问题好多!有同感入
- Media|澳大利亚要求谷歌和Facebook为新闻付费 但新闻网站可能造假
- 平台|抖音海外版超过脸书荣登2021年全球最受欢迎平台,成为排名前十唯一非美国网站