机器之心报道
编辑:小舟、泽南
英特尔在侠盗猎车手 5(GTA5)上测试了他们的图像增强新模型 , 该模型给出了令人印象深刻的结果 。GTA5 是一款经典的 3D 冒险游戏 , 它的画风是这样的:

文章图片
画面接近真实 , 但少了一些质感......
近日 , 来自英特尔的研究者给 GTA 做了一个画质增强补丁 , 先来看下效果:

文章图片
左为 GTA 中的 3D 渲染图 , 右为英特尔新模型生成结果 。
效果很不错 , 下面这一张画质增强的效果就更明显了 , 该模型处理后的画面宛如相机实拍:

文章图片
在 3D 渲染领域 , 实时和真实感是两个关键要素 。 通常照片级渲染引擎处理单帧可能就要花费几分钟甚至几小时 , 而英特尔的新系统则能够以相对较高的帧速率处理图像 。 并且研究者表示 , 他们还将进一步优化该深度学习模型以更快地工作 。 那么英特尔这个图像增强补丁是如何实现的呢?我们来看一下具体的技术细节 。

文章图片
论文地址:
https://arxiv.org/abs/2105.04619
项目地址:
https://github.com/intel-isl/PhotorealismEnhancement
方法与架构
如下图所示 , 该系统由几个相互连接的神经网络组成 。

文章图片
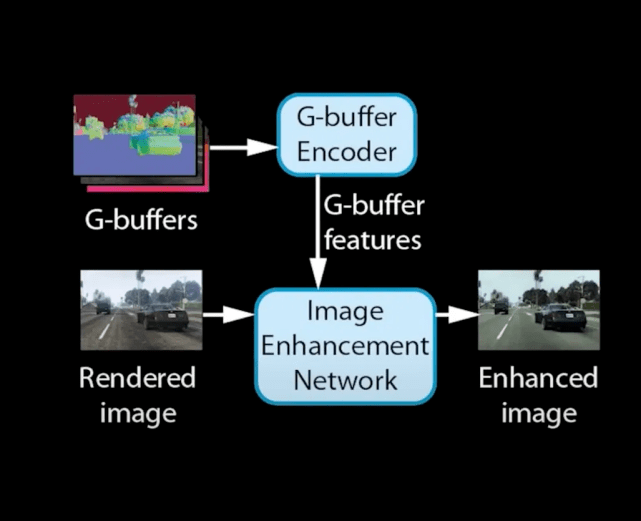
G-buffer 编码器将不同的渲染图转换为一组数字特征 。 多个 G-buffer 分别用作表面法线信息、深度、反照率、光泽度、大气和目标分割的渲染图 。 系统中的神经网络使用卷积层来处理这些信息 , 并输出一个包含 128 个特征的向量 , 以提升图像增强网络的性能 , 并避免像其他类似技术一样产生伪影 。 G-buffer 可以直接从游戏引擎获得 。

文章图片
图像增强网络将游戏的渲染帧和来自 G-buffer 编码器的特征作为输入 , 生成逼真版的图像 。 鉴别器和 LPIPS 损失函数和其他组件则在训练期间使用 。 研究者通过评估生成图像与原始游戏渲染帧的一致性和比较生成图像与真实图像的逼真质量来给该增强网络的输出评级 。
图像增强的推断成本
如果该技术可用 , 游戏玩家是否能够在他们的计算机上运行它?探究这个问题首先需要计算推断成本 , 或者计算运行经过训练的模型所需内存量和算力 。 计算推断成本只需要 G-buffer 编码器和图像增强网络 , 在此可以省去鉴别器网络 。
文章图片
研究者在论文中介绍 , 增强网络是基于 HRNetV2 的神经网络 , HRNetV2 是一种用于处理高分辨率图像的深度学习架构 。 高分辨率神经网络产生的视觉伪影比对图像进行下采样的模型要少一些 。 HRNet 通过以不同分辨率运行的多个分支来处理图像 。 其中较为重要的是 , 有一个特征流会保持相对较高的分辨率(输入分辨率的 1/4) , 以保留精细的图像结构 。
这意味着如果以全高清 (1920×1080) 的分辨率运行游戏 , 那么最顶行的层(top row layer)将以 480×270 像素处理输入 。 接下来每低一行 , 分辨率减半 。 研究者改变了该神经网络中每个块的结构 , 以计算来自 G-buffer 编码器(RAD 层)的输入 。
G-buffer 的输入包括材料信息的 one-hot 编码 , 法线、深度和颜色的密集连续值(dense continuous values for normal)、以及光晕和天空 buffer 的稀疏连续信息 。 此外 , 该模型在 G-buffer 的子集上仍然表现良好 。
那么 , 该模型需要多少内存呢?该研究的论文并没有说明内存大小 , 但根据 HRNetV2 的论文 , 完整网络需要 1.79 GB 的内存才能用于 1024×2048 的输入 。 英特尔使用的图像增强网络具有较小的输入尺寸 , 但还需要考虑 RAD 层和 G-buffer 编码器引入的额外参数 。 因此 , 假设您至少需要 1 GB 的视频内存来为全高清游戏运行基于深度学习的图像增强 , 如果您想要 4K 的分辨率 , 那么内存可能需要超过 2 GB 。
游戏计算机通常具有 4-8 GB VRAM 的显卡 , 因此需要 1 GB 的内存并不算多 。 而像 GeForce RTX 系列的高端显卡则可以拥有高达 24 GB 的 VRAM 。
但同样值得注意的是 , 3D 游戏会消耗大量显卡资源 。 游戏会在视频内存上存储尽可能多的数据 , 以加快渲染速度 , 并避免在 RAM 和 VRAM 之间进行交换 , 而这种操作会导致巨大的速度损失 。 据估计 , 《侠盗猎车手 5》在全高清分辨率下消耗高达 3.5 GB 的 VRAM 。 而赛博朋克 2077 等新兴游戏拥有更大的 3D 世界和更细致的画面对象 , 轻松就可以占用高达 7-8 GB 的 VRAM , 如果想以更高的分辨率播放 , 则需要更多内存 。
因此基本上 , 当前的中高端显卡让用户不得不在低分辨率高真实感和高分辨率合成图形之间进行选择 。 不过 , 内存使用并不是基于深度学习的图像增强面临的唯一问题 。
非线性处理引起的延迟
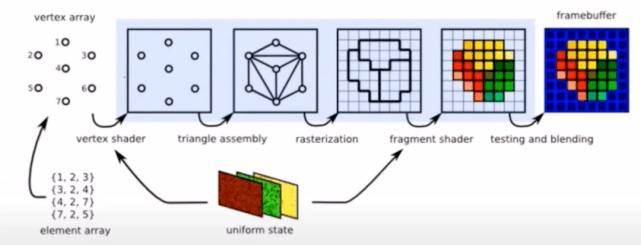
一个更大的问题是深度学习操作的连续和非线性属性 。 要理解这个问题 , 我们首先要使用深度学习推断进行 3D 图形比较 。 三维图形依赖大量的矩阵乘法 。 3D 图形的渲染帧从一组顶点开始 , 每个顶点用一组数字表示 , 这些数字代表 3D 对象上点的属性 , 包括坐标、颜色、材质、法线方向等 。
在渲染每一帧前 , 顶点必须经过一系列矩阵乘法 , 以将顶点的的局部坐标映射到世界坐标、相机空间坐标、图像帧坐标 。 索引缓冲区将顶点捆绑成三个一组以形成三角形 。 这些三角形被光栅化——或转换成像素——然后每个像素通过它自己的一组矩阵操作 , 根据材质颜色、纹理、反射和折射图、透明度级别等来确定它的颜色 。
【HRNetV|玩GTA5吗?高清真人版那种,英特尔新模型将3D渲染图变逼真图片】
文章图片
3D 渲染 pipeline , 图源:LearnEveryone
这听起来似乎要进行很多操作 , 尤其是现在的 3D 游戏是由数百万个多边形组成的 。 在计算机上玩游戏时能够获得非常高的帧率实际上有两个原因 。 首先 , 显卡专为并行矩阵乘法而设计 。 与 CPU 最多只有几十个计算内核不同 , 图形处理器有数千个内核 , 每个内核都可以独立执行矩阵乘法 。
其次 , 图形变换大多是线性的 , 而多个线性变换可以绑定在一起 。 例如将分别用于世界、视图和投影变换的 3 个矩阵相乘以创建一个能够执行这三个操作的矩阵 , 操作量将减少三分之二 。
类似的 , 深度学习也依赖于矩阵乘法 , 每个神经网络都由层层矩阵计算组成 , 这也是显卡在深度学习社区越来越流行的原因 。
但与 3D 图形不同的是 , 深度学习的操作不能组合 。 神经网络中的层依靠非线性激活函数来执行复杂的任务 。 基本上 , 这意味着您无法将多个层的转换操作压缩为单个操作 。
例如 , 假设有一个以 100×100 像素的图像(10000 个特征)作为输入的深度神经网络 , 该网络用七个层处理图像 。 此时具有数千个内核的显卡也许能够并行处理所有像素 , 但是仍然需要依次执行七层神经网络的操作 , 这使得它很难提供实时图像处理 , 尤其是在低端显卡上 。
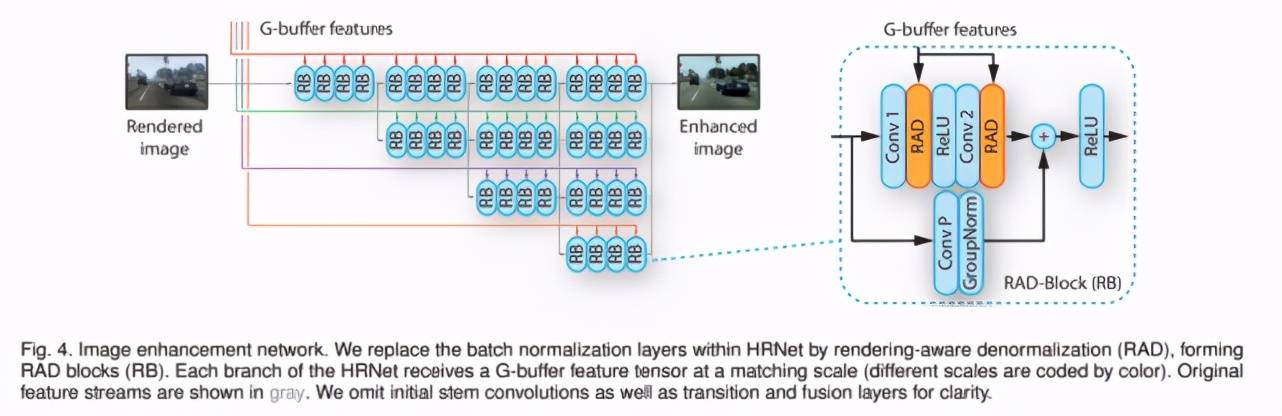
因此 , 一个必须要考虑的瓶颈是必要的顺序操作数量 。 英特尔该模型的图像增强网络的顶层有 16 个按顺序链接的残差块 。 在每个残差块中有两个卷积层、RAD 块和 ReLU 操作依次连接 。 这相当于 96 层顺序操作 。 在 G-buffer 编码器输出其特征编码之前 , 图像增强网络无法开始其操作 。 因此必须至少添加处理第一组高分辨率特征的两个残差块 , 序列中又增加了 8 层 , 这使得用于图像增强的操作至少有 108 层 。
文章图片
英特尔该模型的图像增强网络 。
这意味着除了内存之外 , 你还需要高频率的处理器来运行这些操作 。 在英特尔的论文中我们看到了这样有趣的说法:「使用我们的方法在推理过程中未优化的应用人物需花费一块 GeForce RTX 3090 GPU 半秒时间 。 」
RTX 3090 具有 24 GB 的显存 , 这意味着缓慢的 2 FPS 渲染速率不是由于内存限制 , 而是由于顺序处理图像增强器网络的所有层所需的时间 。 这不是一个可以通过添加更多内存或 CUDA 核来解决的问题 , 只能指望处理器的频率更快才能解决 。
论文中这样写道「用于输入的 G-buffer 是在 GPU 本地生成的 , 我们的方法若与游戏引擎深度整合 , 可以提高效率 , 可能也会带来更高的真实化效果 。 」
将图像增强器网络集成到游戏引擎中可能会大大提高速度 , 但目前看来仍然无法带来可玩的帧率 。
相比之下 , 我们在 HRNet 的论文中可以看到研究人员使用了英伟达 V100 , 这是一种昂贵的专业级 GPU , 专门为深度学习的推理和训练设计 。 由于没有内存限制和其他游戏内容计算的阻碍 , V100 的推理时间为每张输入 150 毫秒 , 约为 7 fps , 这不足以带来流畅的游戏画面(电影是 24 帧 , PS4 标准版是 30 帧) 。
开发和训练神经网络
另一个复杂的问题是开发和训练图像增强神经网络的成本 。 想要引入深度学习技术的游戏公司都会面临三座大山的考验:数据、计算资源和机器学习人才 。
构建数据集是个大问题 , 但幸运的是英特尔已经想办法把问题解决了 。 他们在训练模型时引入了 Cityscapes 数据集 , 其中收集了德国 50 座城市的带注释街景图像 , 精细标注过的图片数量达到了 5000 张 。 根据数据集的论文 , 每张带注释的图像平均需要一个半小时的人工操作来精确指定图像中包含的对象 , 及其边界和类型 。 这些细粒度的注释使图像增强器能够将正确的逼真纹理映射到游戏图形上 。
Cityscapes 是政府拨款、商业公司和学术机构大力支持的成果 , 如果是应用在其他城市环境的游戏中 , 或许也能获得不错的效果 。

文章图片
Cityscapes 数据集中对于人物和街景物体的精细分割 。
实验结果
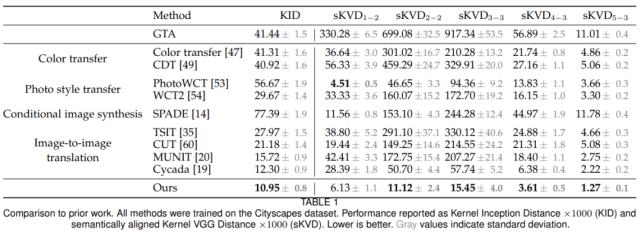
研究者将该方法与其他多个图像转换模型对比了生成效果 , 结果如下表所示:
文章图片
并进行了对照实验来评估该方法中一些特定设计思路的影响 , 包括采样策略、G-buffer 的作用等 , 实验结果如下表所示:

文章图片
此外 , 相比于其他模型 , 英特尔的新模型在视觉效果上具有显著优势 , 例如 CUT 模型生成的画面中存在一些伪影 , 而英特尔的新模型以较小的图块进行采样 , 减少了源数据集和目标数据集之间的不匹配 , 很好地避免了产生伪影的问题:

文章图片
?
扩展?到其他游戏
如果要给《古墓丽影》做真实化怎么办?这可能就需要游戏开发者来自己收集图像 , 然后打标签了 。
计算资源也构成了一个挑战 。 用几千美元训练一个用于图像增强的神经网络是可以接受的——对于大游戏公司来说不是问题 。 但如果你想要做一些生成性人物 , 例如照片级图像增强时 , 训练就变得富有挑战性了 。 它需要人们对超参数进行大量的测试和调整 , 训练很多步 , 这会导致成本的激增 。 英特尔为 GTA 5 训练了模型 , 其他游戏公司或许可以在不同游戏中借鉴这一经验以减少成本 。 但类型差别较大的游戏就只能从头开始训练了 。 英特尔的深度学习模型适用于城市环境 , 其中景物和人物分隔明显 。 但如果在自然环境如森林和洞穴里 , 情况可能会有所不同 。
大多数游戏公司还没有招募机器学习工程师 , 因此他们需要招募人才 , 或者外包任务——而即使这样做了 , 我们也不能百分之百保证「真实风格的画面」可以带来更好的游戏体验 。
英特尔写实风格的图像增强技术向我们展示了机器学习算法的一个全新应用方向 , 但在算力、游戏公司准备好 , 玩家真正接受之前 , 我们距离看到真正的落地可能还有一段时间 。
推荐阅读







- 年轻人|呼叫全城玩家,魔都首发「表情包地铁」启程,2022蓝不倒!
- Disney|光明日报评迪士尼凌晨数千人排队抢购玩偶:道理何在?
- 玩家|电竞手机行业标准升级 升级版引领行业健康有序发展
- 大学|教老年人“玩转”智能手机!太原一老年大学特色课程越来越火
- Disney|5000人夜排抢玩偶 迪士尼营销的锅?
- 智慧|高交会汇聚酷狗等音乐科技企业 展示智慧生活数字音乐新玩法
- Fast-LCD|玩出梦想推出旗下首款 VR 一体机 YVR DK1,搭载骁龙 XR2 芯片
- Apple|韩国要求苹果和Google删除"玩游戏赚钱"的游戏类别
- 才艺|跨年迎新 玩点库的 狂欢宠粉抽好礼 开启好运2022
- 材料|别在玩吃鸡,小学生都开始学习3d打印技术了