选自medium
作者:Andy Wang
机器之心编译
编辑:Geek AI
这可能是最实用的多标签分类小贴士 。众所周知 , 二分类任务旨在将给定的输入分为 0 和 1 两类 。 而多标签分类(又称多目标分类)一次性地根据给定输入预测多个二分类目标 。 例如 , 模型可以预测给定的图片是一条狗还是一只猫 , 同时预测其毛皮是长还是短 。
在多分类任务中 , 预测目标是互斥的 , 这意味着一个输入可以对应于多个分类 。 本文将介绍一些可能提升多标签分类模型性能的小技巧 。
模型评估函数
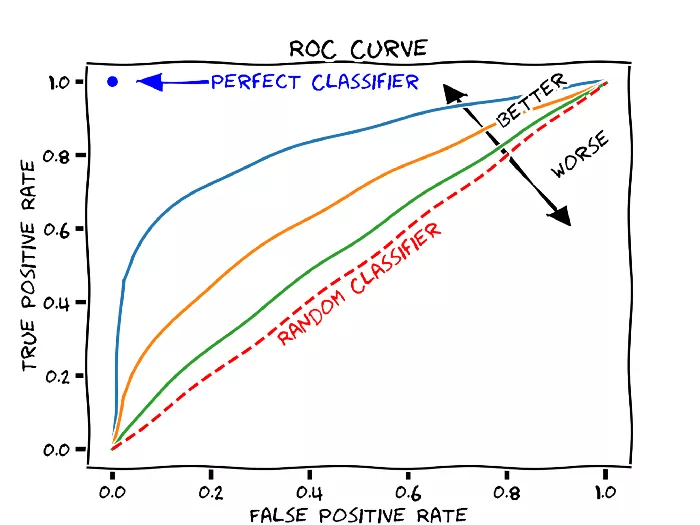
通过在「每一列」(分类标签)上计算模型评估函数并取得分均值 , 我们可以将大多数二分类评估函数用于多标签分类任务 。 对数损失或二分类交叉熵就是其中一种评估函数 。 为了更好地考虑到类别不均衡现象 , 我们可以使用 ROC-AUC 作为评估函数 。
文章图片
图 1:ROC-AUC 曲线
建模技巧
在介绍构建特征的技巧之前 , 本文将介绍一些设计适用于多标签分类场景的模型的小技巧 。
对于大多数非神经网络模型而言 , 我们唯一的选择是为每个目标训练一个分类器 , 然后将预测结果融合起来 。 为此 , 「scikit-learn」程序库提供了一个简单的封装类「OneVsRestClassifier」 。 尽管这个封装类可以使分类器能够执行多标签任务 , 但我们不应采用这种方法 , 其弊端如下:(1)我们会为每个目标训练一个新模型 , 因此训练时间相对较长 。 (2)模型无法学习不同标签之间的关系或标签的相关性 。
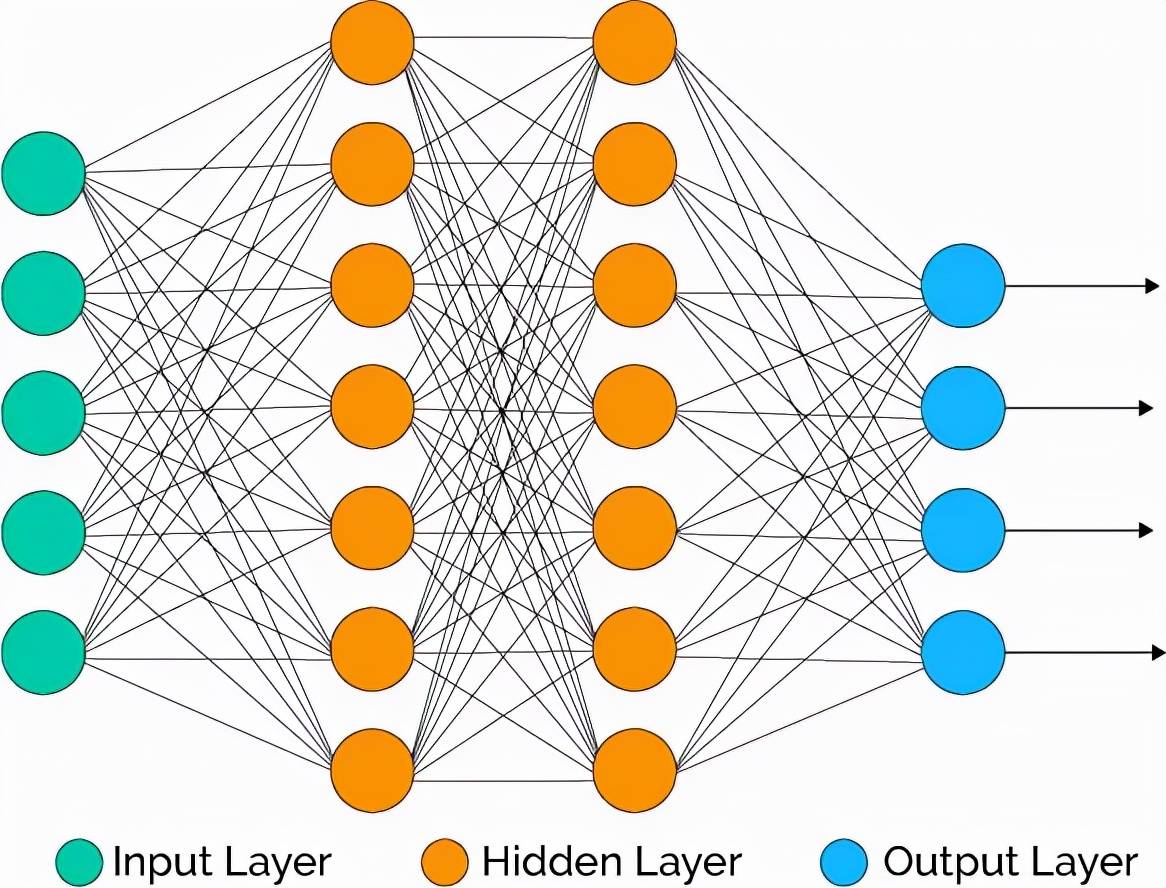
第二个问题可以通过执行一个两阶段训练过程来解决 。 其中 , 我们将目标的预测结果和原始特征相结合 , 作为第二阶段训练的输入 。 这样做的缺点是 , 由于需要训练的模型数量是之前的两倍 , 训练时间将大幅度提升 。 神经网络(NN)则适用于这种场景 , 其中标签的数量即为网络中输出神经元的数量 。 我们可以直接将任意的二分类损失应用于神经网络模型 , 同时该模型会输出所有的目标 。 此时 , 我们只需要训练一个模型 , 且网络可以通过输出神经元学习不同标签的相关性 , 从而解决上文中提出的非神经网络模型的两个问题 。
文章图片
图 2:神经网络
有监督的特征选择方法
在开始特征工程或特征选择之前 , 需要对特征进行归一化和标准化处理 。 使用「scikit-learn」库中的「Quantile Transformer」将减小数据的偏度 , 使特征服从正态分布 。 此外 , 还可以通过对数据采取「减去均值 , 除以标准差」的操作 , 对特征进行标准化处理 。 该过程与「Quantile Transformer」完成了类似的工作 , 其目的都是对数据进行变换 , 使数据变得更加鲁棒 。 然而 , 「Quantile Transformer」的计算开销较高 。
推荐阅读







- 星链|石豪:在太空,马斯克和美国当局是如何作恶的
- Disney|光明日报评迪士尼凌晨数千人排队抢购玩偶:道理何在?
- 核心|中科大陈秀雄团队成功证明凯勒几何两大核心猜想,研究登上《美国数学会杂志》
- Tesla|特斯拉Model Y保费何以一夜暴增80%?
- 何由|2021年,奔向星辰大海的脚步更稳更远!
- 圆角|诺基亚3310圆角设计,造型依旧经典
- 模拟|(图文+视频)C4D野教程:Windows11的壁纸动效是如何制作的?
- 帮信罪|带你了解什么是“帮信罪”如何避免落入陷阱
- Windows|微软解释在Windows 11上为何部分驱动可追溯到1968年
- 孩子|“双减”后 科学实践课如何做好“加法”