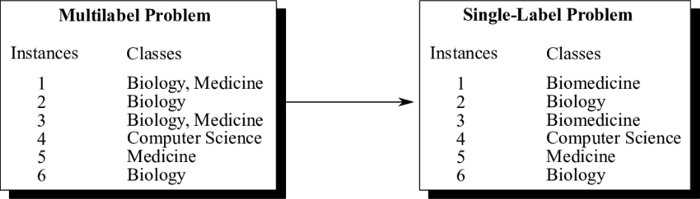
大多数算法都是为单一目标设计的 , 因此使用有监督特征选择方法稍微有些困难 。 为了解决这个问题 , 我们可以将多标签分类任务转化为多类分类问题 。 「Label Powerset」就是其中一种流行的解决方案 , 它将训练数据中的每一个独特的标签组合转化为一个类 。 「scikit-multilearn」程序库中包含实现该方案的工具 。
文章图片
图 3:Label Powerset 方法
在完成转换后 , 我们可以使用「信息增益」和「卡方」等方法来挑选特征 。 尽管这种方法是可行的 , 但是却很难处理上百甚至上千对不同的独特标签组合 。 此时 , 使用无监督特征选择方法可能更合适 。
无监督特征选择方法
在无监督方法中 , 我们不需要考虑多标签任务的特性 , 这是因为无标签方法并不依赖于标签 。 典型的无监督特征选择方法包括:
- 主成分分析(PCA)或其它的因子分析方法 。 此类方法会去除掉特征中的冗余信息 , 并为模型抽取出有用的特征 。 请确保在使用 PCA 之前对数据进行标准化处理 , 从而使每个特征对分析的贡献相等 。 另一个使用 PCA 的技巧是 , 我们可以将该算法简化后的数据作为模型可选择使用的额外信息与原始数据连接起来 , 而不是直接使用简化后的数据 。
- 方差阈值 。 这是一种简单有效的降低特征维度的方法 。 我们丢弃具有低方差或离散型的特征 。 可以通过找到一个更好的选择阈值对此进行优化 , 0.5 是一个不错的初始阈值 。
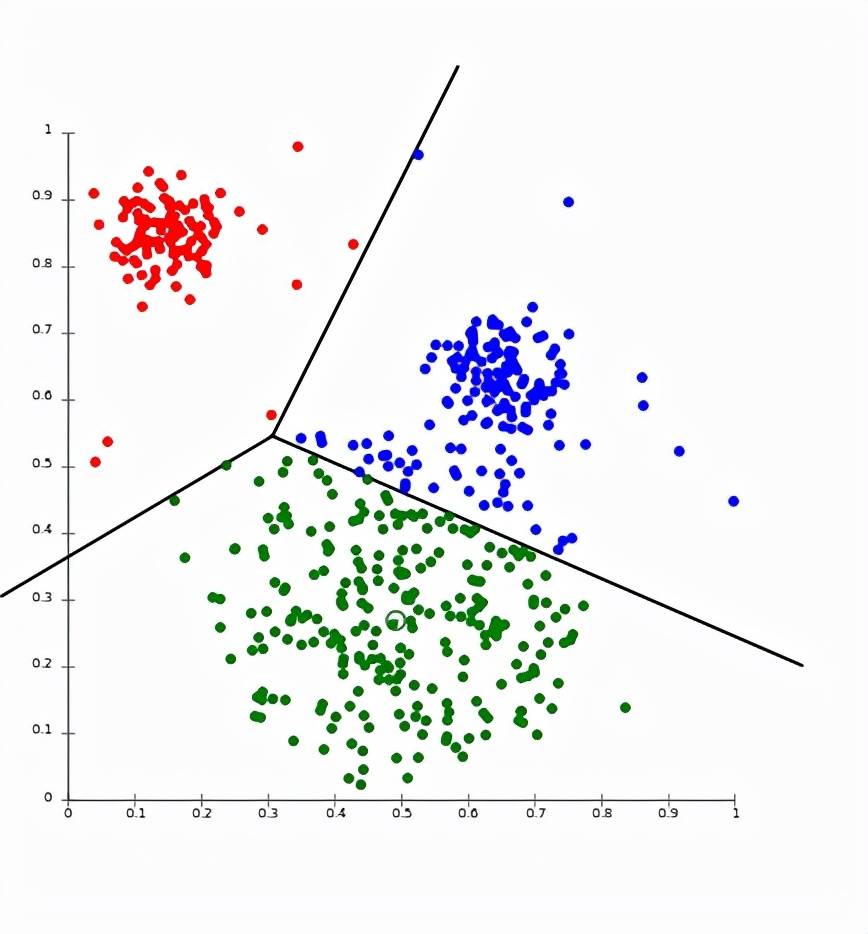
- 聚类 。 通过根据输入数据创建聚类簇来构建新特征 , 然后将相应的聚类分配给每一行输入数据 , 作为一列新的特征 。
文章图片
图 4:K - 均值聚类
上采样方法
当分类数据高度不均衡时 , 可以使用上采样方法为稀有类生成人造样本 , 从而让模型关注稀有类 。 为了在多标签场景下创建新样本 , 我们可以使用多标签合成少数类过采样技术(MLSMOTE) 。
代码链接:https://github.com/niteshsukhwani/MLSMOTE
该方法由原始的 SMOTE 方法修改而来 。 在生成少数类的数据并分配少数标签后 , 我们还通过统计每个标签在相邻数据点中出现的次数来生成其它相关的标签 , 并保留出现频次高于一半统计的数据点的标签 。
【经典|何为多标签分类?这里有几种实用的经典方法】原文链接:https://andy-wang.medium.com/bags-of-tricks-for-multi-label-classification-dc54b87f79ec
推荐阅读







- 星链|石豪:在太空,马斯克和美国当局是如何作恶的
- Disney|光明日报评迪士尼凌晨数千人排队抢购玩偶:道理何在?
- 核心|中科大陈秀雄团队成功证明凯勒几何两大核心猜想,研究登上《美国数学会杂志》
- Tesla|特斯拉Model Y保费何以一夜暴增80%?
- 何由|2021年,奔向星辰大海的脚步更稳更远!
- 圆角|诺基亚3310圆角设计,造型依旧经典
- 模拟|(图文+视频)C4D野教程:Windows11的壁纸动效是如何制作的?
- 帮信罪|带你了解什么是“帮信罪”如何避免落入陷阱
- Windows|微软解释在Windows 11上为何部分驱动可追溯到1968年
- 孩子|“双减”后 科学实践课如何做好“加法”