文章图片
基于课程学习的表格预训练
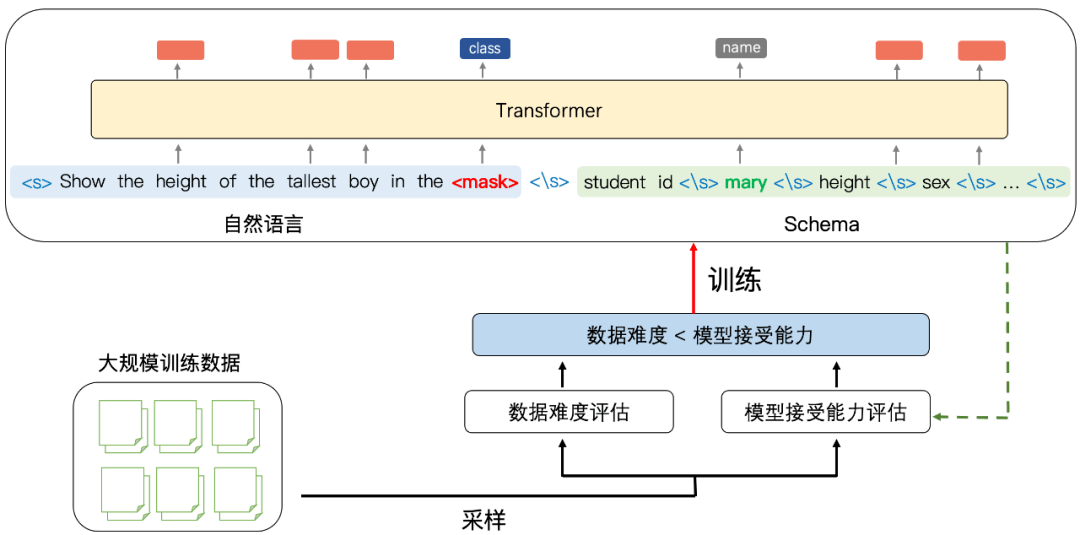
预训练模型依赖大规模的数据进行训练 , 而数据存在难度不同、噪声程度不同等特性 。 如何更好地利用数据成为训练预训练模型的关键 。 因此团队提出使用课程学习来克服多样数据带来的影响 。
课程学习是一种模仿人类的学习方式 , 即从简单到复杂 , 从干净到冗余的学习过程 。 类比到深度学习模型中 , 模型也需要一种合适的学习策略 , 先学习哪些数据、再学习哪些数据 , 对模型能力的提升极为重要 。 如果当前模型学习的数据过于复杂 , 则容易造成欠拟合 , 如果过于简单 , 容易造成过拟合 , 所以需要一种自动的手段筛选当前数据是否符合模型当前期待的复杂程度 。 基于这个思想 , 他们的方案包含两个评估模块:
其一 , 数据难度评估模块:评估当前数据的难易程度 , 设置 d = |I| , 其中 d 代表困难程度 , I 代表预训练模型的输入(包含自然语言 + 表格模式) , 即假设输入的问题长度和模式长度越长 , 最终可能生成的 SQL 语句更加复杂 , 对应当前数据难度越高;
其二 , 模型接受能力评估模块:除了对数据本身进行打分之外 , 我们还需要对模型当前的接受能力 , 或者学习能力进行评估 , 一般来说 , 模型训练越久 , 其接受能力越强 。 所以将模型的接受能力定义为:
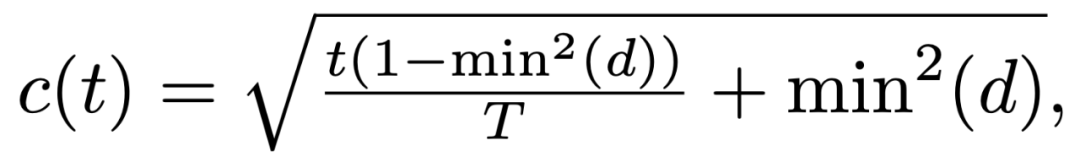
文章图片
其中 d 为数据难度 , t 为训练的步数 , T 为最大训练步数 。
最终 , 从大规模数据中采样得出具体数据时 , 如果当前数据的难度小于模型的接受能力 , 则改数据用来进行训练 , 反之则放回训练集 。 随着不断的迭代 , 所有的数据将渐进式地完成输入 。
文章图片
实验与分析
实验数据集
最终的表格预训练数据包含 2.8 亿条 < Text, SQL, Table> 三元组 , 共 350 GB 。 为评测表格预训练模型的质量 , 团队在学术界已有的英文数据集进行验证 , 其中 WikiSQL 数据集是 Salesforce 在 2017 年提出的大规模标注 Text-to-SQL 数据集 , 也是目前规模最大的 Text-to-SQL 数据集 , 它包含 24,241 张表格、80,645 条自然语言问句及相应的 SQL 语句 。 微软 SQuALL 数据集则增大了该任务的预测难度 , 每个 cell 可能包含多个实体或含义 , 测试集使用的表格都是训练阶段没有见过的 。 目前这两个数据集已经成为学术界评测预训练表格模型最通用的 Benchmark 数据 。
同时 , 团队进一步构建了表格问答中文 Benchmark 数据集 TaBLUE , 在基于模板构建的数据基础之上 , 由人工改写对应的文本 , 使其更加符合真实的表格问答场景 , 最终单轮的评测数据包含金融、政务、医疗和教育四个行业 , 共有 4W 高质量标注 < Text,SQL > 数据 。
推荐阅读







- 研究院|传统行业搭上数字化快车,施工现场变“智造工厂”
- 机器|戴森达人学院 | 戴森HP09空气净化暖风扇测评报告
- 美容|升级扩业 中家医·家庭医生医疗美容医院引爆广州
- 问答|紧追B站加码知识类内容,抖音上线“学习频道”
- 文化|【“用数赋智”系列宣讲】苏州工艺美术职业技术学院探索传统工艺的跨界创新
- IT|南非研究显示两剂强生新冠疫苗可大幅降低Omicron导致的住院
- 团队|深信院41项科研项目亮相高交会 11个项目获优秀产品奖
- 索尼|索尼推出两款无线低音炮、环绕音箱,适配家庭影院
- 生命科学学院|科技馆内感受科技魅力
- 互联网|首儿所互联网医院办公区启用 为患者提供就医便利