【局部|CVPR 2021 | 超越卷积,自注意力模型HaloNet准确率实现SOTA】选自arXiv
作者:Ashish Vaswani等
机器之心编译
编辑:小舟
来自谷歌研究院和 UC 伯克利的研究者开发了一种新的自注意力模型 , 该模型可以超越标准的基线模型 , 甚至是高性能的卷积模型 。与卷积的参数依赖(parameter-dependent)缩放和内容无关(content-independent)交互相比 , 注意力场具有与参数无关的缩放和与内容有关的交互 , 因此自注意力机制有望改善计算机视觉系统 。
近来的研究表明 , 与 ResNet-50 等基线卷积模型相比 , 自注意力模型在准确性 - 参数权衡方面有重要改进 。
在一篇 CVPR 2021 Oral 论文中 , 来自谷歌研究院和 UC 伯克利的研究者开发了一种新的自注意力模型 , 该模型不仅可以超越标准的基线模型 , 而且可以超越高性能的卷积模型 。

文章图片
论文地址:
https://arxiv.org/abs/2103.12731
具体而言 , 该研究提出了自注意力的两个扩展 , 并与自注意力的更高效实现相结合 , 提高了这些模型的运行速度、内存使用率和准确率 。 研究者利用这些改进开发了一种新的自注意力模型——HaloNet , 并且在 ImageNet 分类基准的有限参数设置上准确率实现了新 SOTA 。 HaloNet 局部自注意架构如下图 1 所示:
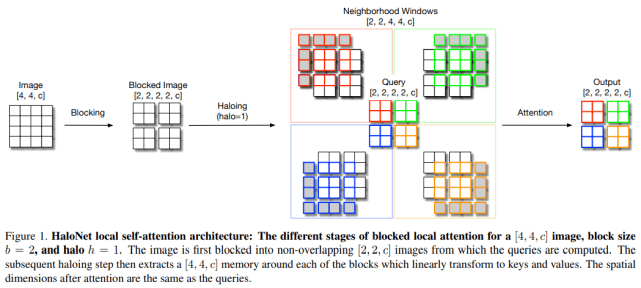
文章图片
在迁移学习实验中 , 该研究发现 HaloNet 模型的性能优于更大的模型 , 并且具有更好的推理性能 。 在目标检测和实例分割等较难的任务上 , 该研究简单的局部自注意力和卷积混合算法在非常强大的基线上显示出性能提升 。
这些实验结果标志着在卷积模型主导的传统环境下 , 自注意力模型又迈出了新的一步 。
方法概述
尽管该研究的模型使用自注意力代替卷积来捕获像素之间的空间交互 , 但它们采用了现代卷积神经网络(CNN)的一些重要架构特征 。 并且 , 和卷积神经网络一样 , 该研究计算多尺度特征层次结构 , 这些层次结构可以在局部化和实例分割等任务上以多种尺寸进行目标检测 。
因此 , 该研究开发了一个 strided 自注意力层 , 它是 strided 卷积的自然扩展 。 为了在无法引起全局注意力的较大分辨率下处理计算成本 , 研究者遵循局部处理(也是卷积和自然感知系统的核心)的通用原则 , 并使用自注意力的空间受限形式 。 下图 2 为注意力下采样层的工作流程:
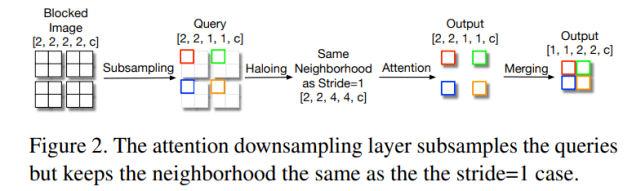
文章图片
该方法没有使用平移等价性(translational equivariance)来代替更好的硬件利用率 , 从而改善了速度和准确率之间的权衡 。 尽管使用的是局部注意力 , 但每个像素的感受野却非常大(达到了 18×18) , 并且更大的感受野有助于处理更大的图像 。
此外 , 研究者还介绍了用于视觉任务的自注意力 , 并描述了如何放松平移等价性 , 以有效地将局部自注意力映射到硬件 。
实验结果
每个 HaloNet 模型(H0–H7)都是通过连续提升表 2 中定义的超参数的值来设计的 。 研究者后续还会进行比肩 EfficientNet 的更大 HaloNet 模型的训练和评估工作 。

文章图片
HaloNet 架构
该研究在 ImageNet 基准上训练了 HaloNet 模型 , 批大小是 4096 , 学习率是 1.6 , 线性预热了 10 个 epoch , 然后进行了余弦衰减 。 模型用 Nesterov 的加速梯度(Accelerated Gradient)训练 350 个 epoch , 并使用 dropout、权重衰减、RandAugment 和随机深度进行了正则化 。
研究者验证了自注意力与视觉卷积各自的优势 , 并进一步理解了自注意力视觉架构的最佳设计方式 。
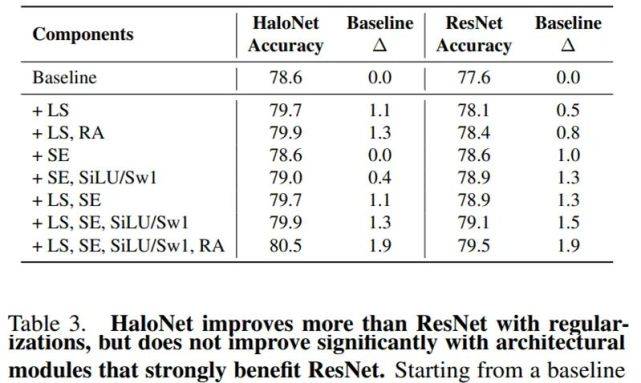
文章图片
实验结果如上表所示 , 带有正则化的 HaloNet 比 ResNet 的性能增益更多 , 但是对 ResNet 中重要的架构化模块却没有显著改进 。
HaloNet 架构
研究者探究了放松平移等价性的影响以及邻域窗口与光晕大小的关系 。
如下图 5 所示 , 放松平移等价性能够提升准确率 。
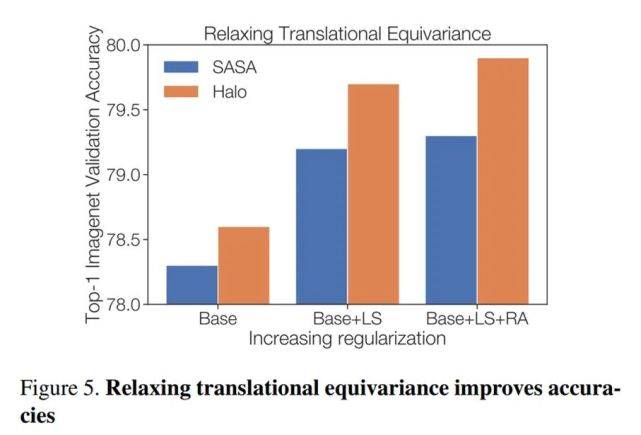
文章图片
从下图 6 可以发现随着窗口大小的增加 , 准确率会不断提高 。 特别是 , 将窗口大小从 6×6 增大到 12×12 , 准确率会提升 1.3% 。 这些结果表明 , 增加窗口大小可以用于扩展模型 , 而无需增加参数数量 , 这可能对生产环境有利 。
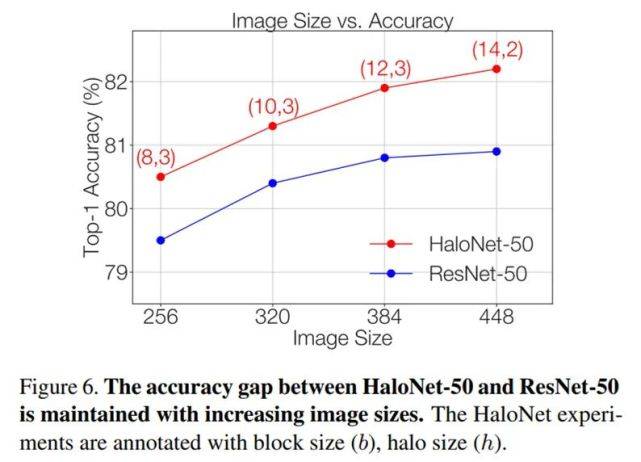
文章图片
卷积 - 注意力混合改善了速度 - 准确率权衡
在一组控制变量实验中 , 该研究用卷积替代了自注意力 , 以了解当前注意力层最有利的地方 。
在性能最优的模型(HaloNet H7)的每个阶段中 , 表 4 展示了借助 SE 模块用卷积替代注意力层的结果 。 除最后一个阶段外 , 其他所有阶段都进行卷积会产生最快的模型 , 尽管 top-1 准确率会显著降低(1%) 。 在卷积和注意力上分别进行分配可最小程度地降低预测准确率 , 同时显著改善训练和推断过程 。 未来研究者还将对改进的混合模型进行进一步的研究 。
感兴趣的读者可以阅读论文原文 , 了解更多研究细节 。
https://jiqizhixin.mikecrm.com/SQARemF
推荐阅读







- Google|谷歌暂缓2021年12月更新推送 调查Pixel 6遇到的掉线断连问题
- 精度|将建模速率提升10倍,消费级3D扫描仪Magic Swift在2021高交会大显“身手”
- 四平|智慧城市“奥斯卡”揭晓!祝贺柯桥客户荣获2021世界智慧城市治理大奖
- 系列|2021中国航天发射圆满收官!年发射55次居世界第一
- 项目|常德市二中2021青少年科技创新大赛再获佳绩
- 选型|数据架构选型必读:2021上半年数据库产品技术解析
- 殊荣|蝉联殊荣!数梦工场荣获DAMA2021数据治理三项大奖
- 公司|外媒:2021,人类太空事业的重大年份
- 语境|B站2021个人年度报告发布:你共计看了多少个视频
- 最新消息|IT系统出错 英国银行给7.5万人多发11亿工资