机器之心编辑部
去年有哪些机器学习重要进展是你必须关注的?听听 DeepMind 研究科学家怎么说 。

文章图片
2020 年因为新冠疫情 , 很多人不得不在家工作和学习 , 大量人工智能学术会议也转为线上 。 不过在去年我们仍然看到了很多 AI 技术领域的进展 。 DeepMind 研究科学家 Sebastian Ruder 近日帮我们对去年的机器学习社区进行了一番总结 。
首先你必须了解的是:这些重点的选择基于作者个人熟悉的领域 , 所选主题偏向于表示学习、迁移学习 , 面向自然语言处理(NLP) 。 如果读者有不同的见解 , 可以留下自己的评论 。
Sebastian Ruder 列出的 2020 年十大机器学习研究进展是:
大模型和高效模型
文章图片
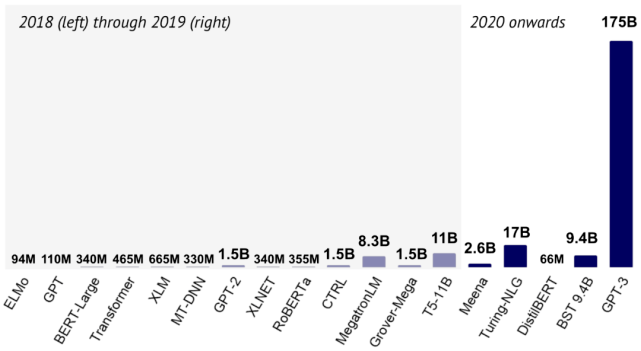
语言模型从 2018 年到 2020 年的发展(图片来自 State of AI Report 2020) 。
2020 年发生了什么?
在过去的一年 , 我们看到了很多前所未有的巨型语言和语音模型 , 如 Meena(Adiwardana et al., 2020)、Turing-NLG、BST(Roller et al., 2020)和GPT-3(Brown et al., 2020) 。 与此同时 , 研究人员们也早已意识到训练这样的模型要耗费过量的能源(Strubell et al., 2019) , 并转而探索体量更小、效果仍然不错的模型:最近的一些进展方向来自于裁剪((Sajjad et al., 2020、Sanh et al., 2020、)、量化(Fan et al., 2020b)、蒸馏(Sanh et al., 2019、Sun et al., 2020)和压缩(Xu et al., 2020) 。
另有一些研究关注如何让 Transformer 架构本身变得更高效 。 其中的模型包括 Performer(Choromanski et al., 2020)和 Big Bird(Zaheer et al., 2020) , 如本文第一张图所示 。 该图显示了在Long Range Arena 基准测试中不同模型的性能(y 轴)、速度(x 轴)和内存占用量(圆圈大小)(Tay et al., 2020) 。
像 experiment-impact-tracker 这样的工具(Henderson et al., 2020)已让我们对于模型的能耗效率更为了解 。 其研究者还推动了评估效率的竞赛和基准测试 , 如 EMNLP 2020 上的 SustaiNLP 研讨会 , NeurIPS 2020 上的 Efficient QA 竞赛和 HULK(Zhou et al., 2020 。
模型体量的扩大可以让我们不断突破深度学习能力的极限 。 而为了在现实世界部署它们 , 模型必须高效 。 这两个方向也是相辅相成的:压缩大号模型可以兼顾效率和性能(Li et al., 2020) , 而效率更高的方法也可以推动更强、更大的模型(Clark et al., 2020) 。
鉴于对效率和可用性的考虑 , 我认为未来研究的重点不仅仅是模型的表现和参数数量 , 也会有能耗效率 。 这会有助于人们对于新方法进行更全面的评估 , 从而缩小机器学习研究与实际应用之间的差距 。
检索增强
文章图片
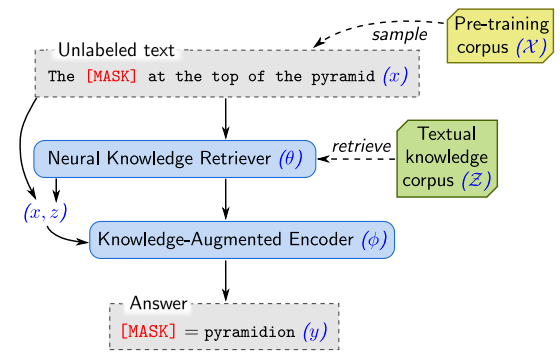
使用 REALM 进行无监督预训练 , 检索器和编码器经过了联合预训练 。
大规模模型可以利用预训练数据学习出令人惊讶的全局知识 , 这使得它们可以重建事实(Jiang et al., 2020)并在不接触外界上下文的情况下回答问题(Roberts et al., 2020) 。 然而 , 把这些知识隐式地存储在模型参数中效率很低 , 需要极大的模型来存储足量的信息 。 与之不同的是 , 最近的一些方法选择同时训练检索模型和大规模语言模型 , 在知识密集型 NLP 任务上获得了强大的结果 , 如开放域问答(Guu et al., 2020、Lewis et al., 2020)和语言建模(Khandelwal et al., 2020) 。
这些方法的主要优点是将检索直接集成到语言模型的预训练中 , 从而让语言模型效率更高 , 专注于学习自然语言理解中更具挑战性的概念 。 因此在 NeurIPS 2020 EfficientQA 竞赛中的最佳系统依赖于检索(Min et al., 2020) 。
检索是很多生成任务的标准方法 , 例如文本摘要和对话此前已大量被摘要生成所替代 (Allahyari et al., 2017) 。 检索增强生成可以将两个方面的优点结合在一起:检索段的事实正确性、真实性以及所生成文本的相关性和构成 。
检索增强生成对于处理过去困扰生成神经模型的失败案例尤其有用 , 尤其是在处理幻觉(hallucination)上(Nie et al., 2019) 。 它也可以通过直接提供预测依据来帮助使系统更易于解释 。
少样本学习

文章图片
Prompt-based 微调使用模板化的提示和演示(Gao et al., 2020) 。
在过去几年中 , 由于预训练的进步 , 给定任务的训练样本数量持续减少(Peters et al., 2018、Howard et al., 2018) 。 我们现在正处在可以使用数十个示例来完成给定任务的阶段(Bansal et al., 2020) 。 自然地 , 人们想到了少样本学习变革语言建模的范式 , 其中最为突出的例子就是 GPT-3 中上下文学习的方法 。 它可以根据一些输入 - 输出对和一个提示进行预测 。 无需进行梯度更新 。
不过这种方式仍然有其限制:它需要一个巨大的模型——模型需要依赖现有的知识——这个模型能够使用的知识量受到其上下文窗口的限制 , 同时提示需要手工完成 。
最近的一些工作试图通过使用小模型 , 集成微调和自动生成自然语言提示(Schick and Schütze, 2020、Gao et al., 2020、Shin et al., 2020)让少样本学习变得更加有效 。 这些研究与可控神经文本生成的更广泛领域紧密相关 , 后者试图广泛地利用预训练模型的生成能力 。
有关这一方面 , 可以参阅 Lilian Weng 的一篇博客:
https://lilianweng.github.io/lil-log/2021/01/02/controllable-neural-text-generation.html
少样本学习可以使一个模型快速承接各种任务 。 但是为每个任务更新整个模型的权重是很浪费的 。 我们最好进行局部更新 , 让更改集中在一小部分参数里 。 有一些方法让这些微调变得更加有效和实用 , 包括使用 adapter(Houlsby et al., 2019、Pfeiffer et al., 2020a、üstün et al., 2020) , 加入稀疏参数向量(Guo et al., 2020) , 以及仅修改偏差值(Ben-Zaken et al., 2020) 。
能够仅基于几个范例就可以让模型学会完成任务的方法 , 大幅度降低了机器学习、NLP 模型应用的门槛 。 这让模型可以适应新领域 , 在数据昂贵的情况下为应用的可能性开辟了道路 。
对于现实世界的情况 , 我们可以收集上千个训练样本 。 模型同样也应该可以在少样本学习和大训练集学习之间无缝切换 , 不应受到例如文本长度这样的限制 。 在整个训练集上微调过的模型已经在 SuperGLUE 等很多流行任务中实现了超越人类的性能 , 但如何增强其少样本学习能力是改进的关键所在 。
对比学习
文章图片
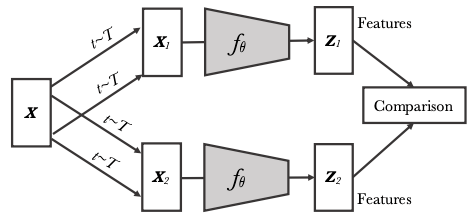
实例判别从同一个图像的不同转换之间比较特征(Caron et al., 2020) 。
对比学习是一种为 ML 模型描述相似和不同事物的任务的方法 。 利用这种方法 , 可以训练机器学习模型来区分相似和不同的图像 。
最近 , 对比学习在计算机视觉和语音的自监督表征学习(van den Oord, 2018; Hénaff et al., 2019)中越来越受欢迎 。 用于视觉表征学习的新一代自监督强大方法依赖于使用实例判别任务的对比学习:将不同图像视为 negative pairs , 相同图像的多个视图视为 positive pairs 。 最近的方法进一步改善了这种通用框架:SimCLR(Chen et al., 2020)定义了增强型实例的对比损失;Momentum Contrast(He et al., 2020)试图确保大量且一致的样本对集合;SwAV(Caron et al., 2020)利用在线聚类;而 BYOL 仅使用 positive pairs(Grill et al., 2020) 。 Chen 和 He (2020) 进一步提出了一种与先前方法有关的更简单的表述 。
最近 , Zhao et al. (2020)发现数据增强对于对比学习至关重要 。 这可能表明为什么在数据增强不那么普遍的 NLP 中使用大型预训练模型进行无监督对比学习并不成功 。 他们还假设 , 实例判别比计算机视觉中的有监督预训练更好的原因是:它不会试图让一个类中所有实例的特征相似 , 而是保留每个实例的信息 。 在 NLP 中 , Gunel et al. (2020)无监督的预训练涉及对成千上万个单词类型进行分类的问题不大 。 在 NLP 中 , Gunel et al. (2020)最近采用对比学习进行有监督的微调 。
语言建模中常用的 one-hot 标签与模型输出的 logit 之间的交叉熵目标存在一些局限性 , 例如在不平衡的类中泛化效果较差(Cao et al., 2019) 。 对比学习是一种可选择的补充范式 , 可以帮助缓解其中的一些问题 。
对比学习与 masked 语言建模相结合能够让我们学习更丰富、更鲁棒的表征 。 它可以帮助解决模型异常值以及罕见的句法和语义现象带来的问题 , 这对当前的 NLP 模型是一个挑战 。
要评估的不只是准确率
文章图片
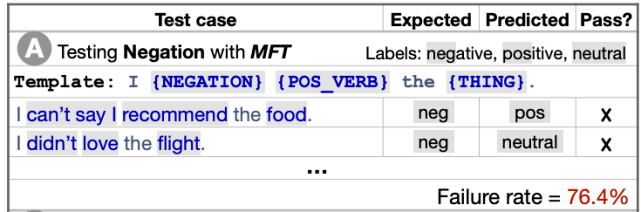
用于探索情感分析中否定性的理解的 CheckList 模板和测试(Ribeiro et al., 2020) 。
NLP 中的 SOTA 模型已在许多任务上实现了超越人类的表现 , 但我们能否相信这样的模型可以实现真正的自然语言理解(Yogatama et al., 2019; Bender and Koller, 2020)?其实 , 当前的模型离这个目标还很远 。 但矛盾的是 , 现有的简单性能指标无法体现这些模型的局限性 。 该领域有两个关键主题:a)精选当前模型难以处理的样例;b)不只是选择准确率等简单指标 , 而是进行更细粒度的评估 。
关于前者 , 常用的方法是在数据集创建过程中使用对抗过滤(Zellers et al., 2018) , 过滤出由当前模型正确预测的样例 。 最近的研究提出了更有效的对抗过滤方法(Sakaguchi et al., 2020; Le Bras et al., 2020)和一种迭代数据集创建处理方法(Nie et al., 2020; Bartolo et al., 2020) , 其中样例经过过滤 , 模型经过了多轮的重新训练 。 Dynabench 提供了此类不断变化的基准的子集 。
针对第二点的方法在本质上也是相似的 。 该领域通常会创建 minimal pairs(也称为反事实样例或对比集)(Kaushik et al., 2020; Gardner et al., 2020; Warstadt et al., 2020) , 这些 minimal pairs 以最小的方式干扰了样例 , 并且经常更改 gold label 。 Ribeiro et al. (2020) 在 CheckList 框架中形式化了一些基本的直觉 , 从而可以半自动地创建此类测试用例 。 此外 , 基于不同的属性来描述样例可以对模型的优缺点进行更细粒度的分析(Fu et al., 2020)
为了构建功能更强大的机器学习模型 , 我们不仅需要了解模型是否优于先前的系统 , 还需要了解它会导致哪种错误以及还有哪些问题没被反映出来 。 通过提供对模型行为的细粒度诊断 , 我们可以更轻松地识别模型的缺陷并提出解决方案 。 同样 , 利用细粒度的评估可以更细致地比较不同方法的优缺点 。
语言模型的现实应用问题
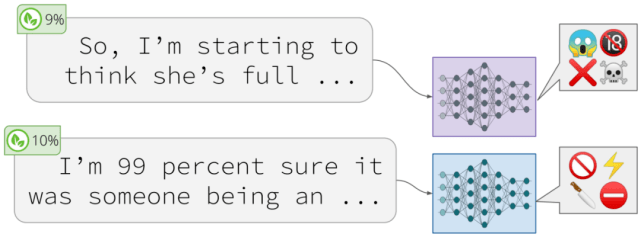
文章图片
模型会根据看似无害的提示 , 生成有害的结果(Gehman et al., 2020) 。
与 2019 年语言模型 (LMs) 分析侧重于此类模型所捕获的语法、语义和世界认知的氛围相比 , 最近一年的分析揭示了许多实际问题 。
比如经过预训练的 LM 容易生成「有毒」的语言 (Gehman et al., 2020)」、泄露信息 (Song & Raghunathan, 2020) 。 还存在微调后易受到攻击的问题 , 以致攻击者可以操纵模型预测结果 (Kurita et al., 2020; Wallace et al., 2020) , 以及容易受到模型的影响(Krishna et al., 2020; Carlini et al., 2020) 。
众所周知 , 预训练模型可以捕获关于受保护属性(例如性别)的偏见(Bolukbasi et al., 2016; Webster et al., 2020) , Sun et al., 2019 的研究给出了一份减轻性别偏见的调查 。
大公司推出的大型预训练模型往往在实际场景中会有积极的部署 , 所以我们更应该意识到这些模型存在什么偏见 , 又会产生什么有害的后果 。
随着更大模型的开发和推出 , 从一开始就将这些偏见和公平问题纳入开发过程是很重要的 。
Multilinguality
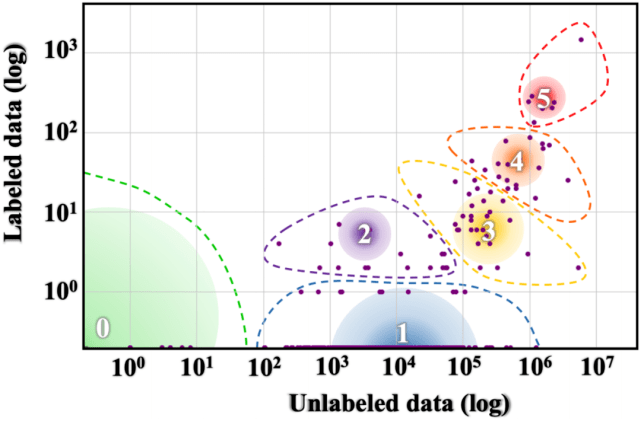
文章图片
全球标记 / 未标记语言数据的不均衡分布情况(Joshi et al., 2020) 。
2020 年 , 多语言 NLP 有诸多亮点 。 旨在加强非洲语种 NLP 研究的 Masakhane 机构在第五届机器翻译会议 (WMT20) 上发表的主题演讲 , 是去年最令人鼓舞的演讲之一 。 此外 , 这一年还出现了其他语言的新通用基准 , 包括 XTREME (Hu et al., 2020)、XGLUE (Liang et al., 2020)、IndoNLU (Wilie et al., 2020)、IndicGLUE (Kakwani et al., 2020) 。 现有的数据集也拓展到了其他语言中 , 比如:
SQuAD: XQuAD (Artetxe et al., 2020), MLQA (Lewis et al., 2020), FQuAD (d'Hoffschmidt et al., 2020);
Natural Questions: TyDiQA (Clark et al., 2020), MKQA (Longpre et al., 2020);
MNLI: OCNLI (Hu et al., 2020), FarsTail (Amirkhani et al., 2020);
the CoNLL-09 dataset: X-SRL (Daza and Frank, 2020);
the CNN/Daily Mail dataset: MLSUM (Scialom et al., 2020) 。
通过 Hugging Face 数据集可以访问其中的大部分数据集 , 以及许多其他语言的数据 。 涵盖 100 种语言的强大模型也就应运而生了 , 包括 XML-R (Conneau et al., 2020)、RemBERT (Chung et al., 2020)、InfoXLM (Chi et al., 2020)等 , 具体可参见 XTREME 排行榜 。 大量特定语言的 BERT 模型已经针对英语以外的语言进行了训练 , 例如 AraBERT (Antoun et al., 2020)和 IndoBERT (Wilie et al., 2020) , 查看 Nozza et al., 2020; Rust et al., 2020 的研究可以了解更多信息 。 借助高效的多语言框架 , 比如 AdapterHub (Pfeiffer et al., 2020)、Stanza (Qi et al., 2020)和 Trankit (Nguyen et al., 2020), 世界上许多语种的建模和应用工作都变得轻松了许多 。
此外 , 还有两篇很有启发的研究 , 《The State and Fate of Linguistic Diversity(Joshi et al., 2020)》和《Decolonising Speech and Language Technology (Bird, 2020)》 。 第一篇文章强调了使用英语之外语言的紧迫性 , 第二篇文章指出了不要将语言社区及数据视为商品 。
拓展到英语之外的 NLP 研究有很多好处 , 对人类社会能产生实实在在的影响 。 考虑到不同语言中数据和模型的可用性 , 英语之外的 NLP 模型将大有作为 。 同时 , 开发能够应对最具挑战性设置的模型并确定哪些情况会造成当前模型的基础假设失败 , 仍然是一项激动人心的工作 。
图像Transformers
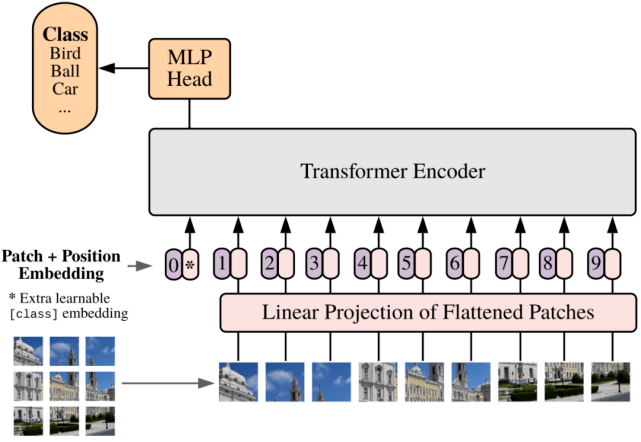
文章图片
Vision Transformer 的论文中 , 研究者将 Transformer 编码器应用于平坦图像块 。
Transformer 在 NLP 领域取得了巨大的成功 , 但它在卷积神经网络 CNN 占据主导地位的计算机视觉领域却没那么成功 。 2020 年初的DETR (Carion et al., 2020)将 CNN 用于计算图像特征 , 但后来的模型完全是无卷积的 。 Image GPT (Chen et al., 2020)采用了 GPT-2 的方法 , 直接从像素进行预训练 , 其性能优于有监督的 Wide ResNet , 后来的模型是将图像重塑为被视为「token」的补丁 。 Vision Transformer (ViT , Dosovitskiy et al., 2020)在数百万个标记好的图像上进行了训练 , 每一个图像都包含此类补丁 , 模型效果优于现有最新的 CNN 。 Image Processing Transformer(IPT , Chen et al., 2020)在被破坏的 ImageNet 示例上进行对比损失预训练 , 在 low-level 图像任务上实现了新的 SOTA 。 Data-efficient image Transformer (DeiT , Touvron et al., 2020) 以蒸馏方法在 ImageNet 上进行了预训练 。
有趣的是 , 研究者们发现了 CNN 是更好的教师 , 这一发现类似于蒸馏归纳偏置(inductive bias)应用于 BERT (Kuncoro et al., 2020) 。 相比之下在语音领域 , Transformer 并未直接应用于音频信号 , 而通常是将 CNN 等编码器的输出作为输入(Moritz et al., 2020; Gulati et al., 2020; Conneau et al., 2020) 。
与 CNN 和 RNN 相比 , Transformer 的归纳偏置更少 。 尽管在理论上 , 它不如 RNN (Weiss et al., 2018; Hahn et al., 2020)强大 , 但如果基于充足的数据和规模 , Transformer 会超越其他竞争对手的表现 。
未来 , 我们可能会看到 Transformer 在 CV 领域越来越流行 , 它们特别适用于有足够计算和数据用于无监督预训练的情况 。 在小规模配置的情况下 , CNN 应该仍是首选方法和基线 。
【影响力|2020年这10大ML、NLP研究最具影响力:为什么?接下来如何发展?】自然科学与机器学习
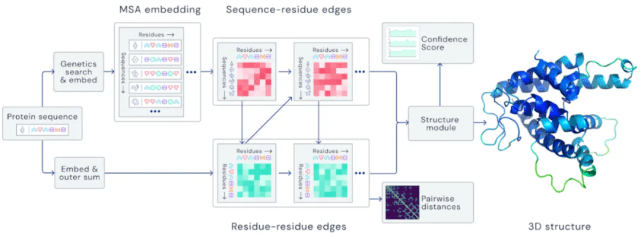
文章图片
基于自注意力的 AlphaFold 架构 。
去年 , DeepMind 的AlphaFold在 CASP 蛋白质折叠挑战赛中实现了突破性的表现 , 除此之外 , 将机器学习应用于自然科学还有一些显著的进展 。 MetNet (S?nderby et al., 2020)证明机器学习在降水预测方面优于数值天气预报;Lample 和 Charton(2020)采用神经网络求解微分方程 , 比商用计算机系统效果更好;Bellemare et al. (2020)使用强化学习为平流层的热气球导航 。
此外 , ML 现已被广泛应用于 COVID-19 , 例如 Kapoor 等人利用 ML 预测 COVID-19 的传播 , 并预测与 COVID-19 相关的结构 , Anastasopoulos 等人将相关数据翻译成 35 种不同的语言 , Lee 等人的研究可以实时回答有关 COVID-19 的问题 。
有关 COVID-19 相关的 NLP 应用程序的概述 , 请参阅第一期 COVID-19 NLP 研讨会的会议记录:《Proceedings of the 1st Workshop on NLP for COVID-19 (Part 2) at EMNLP 2020》 。
自然科学可以说是 ML 最具影响力的应用领域 。 它的改进涉及到生活的许多方面 , 可以对世界产生深远的影响 。 随着蛋白质折叠等核心领域的进展 , ML 在自然科学中的应用速度只会加快 。 期待更多促进世界进步的研究出现 。
强化学习
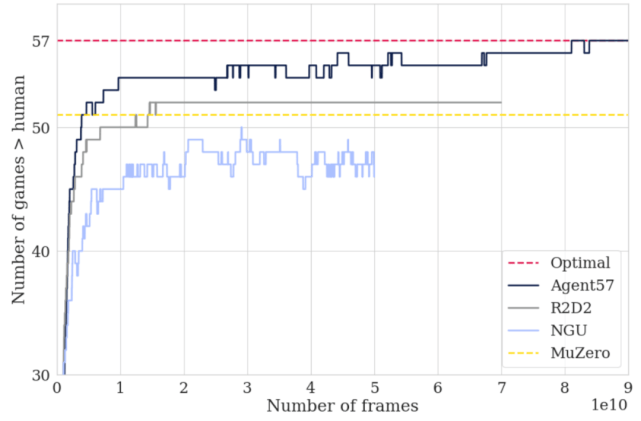
文章图片
与最先进的智能体相比 , Agent57 和 MuZero 整个训练过程中在雅达利游戏中的表现优于人类基准(Badia et al., 2020) 。
单个深度强化学习智能体Agent57(Badia et al., 2020)首次在 57 款 Atari 游戏上超过人类 , 这也是深度强化学习领域中的一个长期基准 。 智能体的多功能性来自于神经网络 , 该网络允许在探索性策略和利用性策略之间切换 。
强化学习在游戏方面的另一个里程碑是 Schrittwieser 等人开发的MuZero , 它能预测环境各个方面 , 而环境对精确的规划非常重要 。 在没有任何游戏动态知识的情况下 , MuZero 在雅达利上达到了 SOTA 性能 , 在围棋、国际象棋和日本象棋上表现也很出色 。
最后是 Munchausen RL 智能体(Vieillard et al., 2020) , 其通过一个简单的、理论上成立的修改 , 提高了 SOTA 水平 。
强化学习算法有许多实际意义 (Bellemare et al., 2020) 。 研究人员对这一领域的基本算法进行改进 , 通过更好的规划、环境建模和行动预测产生很大的实际影响 。
随着经典基准(如 Atari)的基本解决 , 研究人员可能会寻找更具挑战性的设置来测试他们的算法 , 如推广到外分布任务、提高样本效率、多任务学习等 。
参考内容:https://ruder.io/research-highlights-2020/
推荐阅读







- 技术|“2”类医械有重大进展:神经介入产品井喷、基因测序弯道超车
- 区块|面向2030:影响数据存储产业的十大应用(下):新兴应用
- 重大进展|“2”类医械有重大进展:神经介入产品井喷、基因测序弯道超车
- 市场|激斗智能家居,大厂遇到新对手
- 精度|将建模速率提升10倍,消费级3D扫描仪Magic Swift在2021高交会大显“身手”
- 最新消息|世界单体容量最大漂浮式光伏电站在德州并网发电
- 四平|智慧城市“奥斯卡”揭晓!祝贺柯桥客户荣获2021世界智慧城市治理大奖
- 项目|常德市二中2021青少年科技创新大赛再获佳绩
- 殊荣|蝉联殊荣!数梦工场荣获DAMA2021数据治理三项大奖
- 公司|外媒:2021,人类太空事业的重大年份