8月14日至18日 , 国际数据挖掘与知识发现大会 KDD 2021在线上正式举行 。 此前本届KDD入选论文已经揭晓 , 百度被收录的多篇论文 , 其突出的特点是学术研究与技术应用紧密结合 , 再次展现百度在AI领域的技术实力 。
ACM SIGKDD(简称KDD)国际数据挖掘与知识发现大会至今已连续举办了26届 , 是世界数据挖掘最高级别的学术会议之一 , 有数据挖掘领域“世界杯”之称 , 每年吸引了大量数据挖掘、机器学习、大数据和人工智能等领域的研究学者、从业人员参与 。
百度在AI技术方向多年创新积累 , 数据挖掘和知识发现也是重点关注和持续投入的相关领域 , 并拥有多项技术成果和应用落地案例 。 在多年为KDD输送优质论文的基础上 , 百度今年的被收录论文再次体现了技术与应用紧密融合的趋势 。
生物计算与医疗:生命健康里的AI新可能
在与人类息息相关的生命健康领域 , 百度也取得了长足进步:在AI+医疗多个方向上探索 , 构建医疗AI中台、面向医疗场景提供各种AI解决方案;更进一步寻觅生物计算的密码 , 推出生物计算平台螺旋桨PaddleHelix 。 此次KDD 2021中 , 百度发表了论文聚焦生命健康领域 , 提出了相关的新型图神经网络模型和医学实体关系循证框架 。
1.三维结构感知的交互式图神经网络 —— 用于蛋白质-配体亲和力预测的新型图神经网络模型
Structure-aware Interactive Graph Neural Networks for the Prediction of Protein-Ligand Binding Affinity
论文链接:https://dl.acm.org/doi/10.1145/3447548.3467311
药物设计的一个关键步骤是准确的预测蛋白质-配体的亲和力(protein-ligandbinding affinity) 。 最近的研究进展已经证明 , 使用图神经网络 (GNNs) 来学习蛋白质-配体复合物(protein-ligand complexes)的表示 , 比传统方法可以更准确地预测亲和力 。 然而 , 现有的模型通常将蛋白质-配体复合物视为拓扑图 , 并没有充分利用分子的三维结构信息 。 同时GNN模型也忽略了原子之间基本的远距离相互作用 。 为此 , 我们提出了一种新型的三维结构感知的交互式图神经网络 (SIGN) , 它由两个部分组成:基于极坐标的图注意力层 (PGAL) 和成对交互式池化层 (PiPool) 。 具体来说 , PGAL层首先迭代执行节点-边聚合过程以更新节点和边的表征 , 在这个过程可以同时保留原子之间的距离和角度信息 。 然后 , SIGN可以通过PiPool层来对交互边进行池化操作 , 随后通过重建交互矩阵的学习任务来反映蛋白质-配体的全局交互信息 。 在两个基准数据集上的实验结果验证了SIGN预测效果的优越性 。
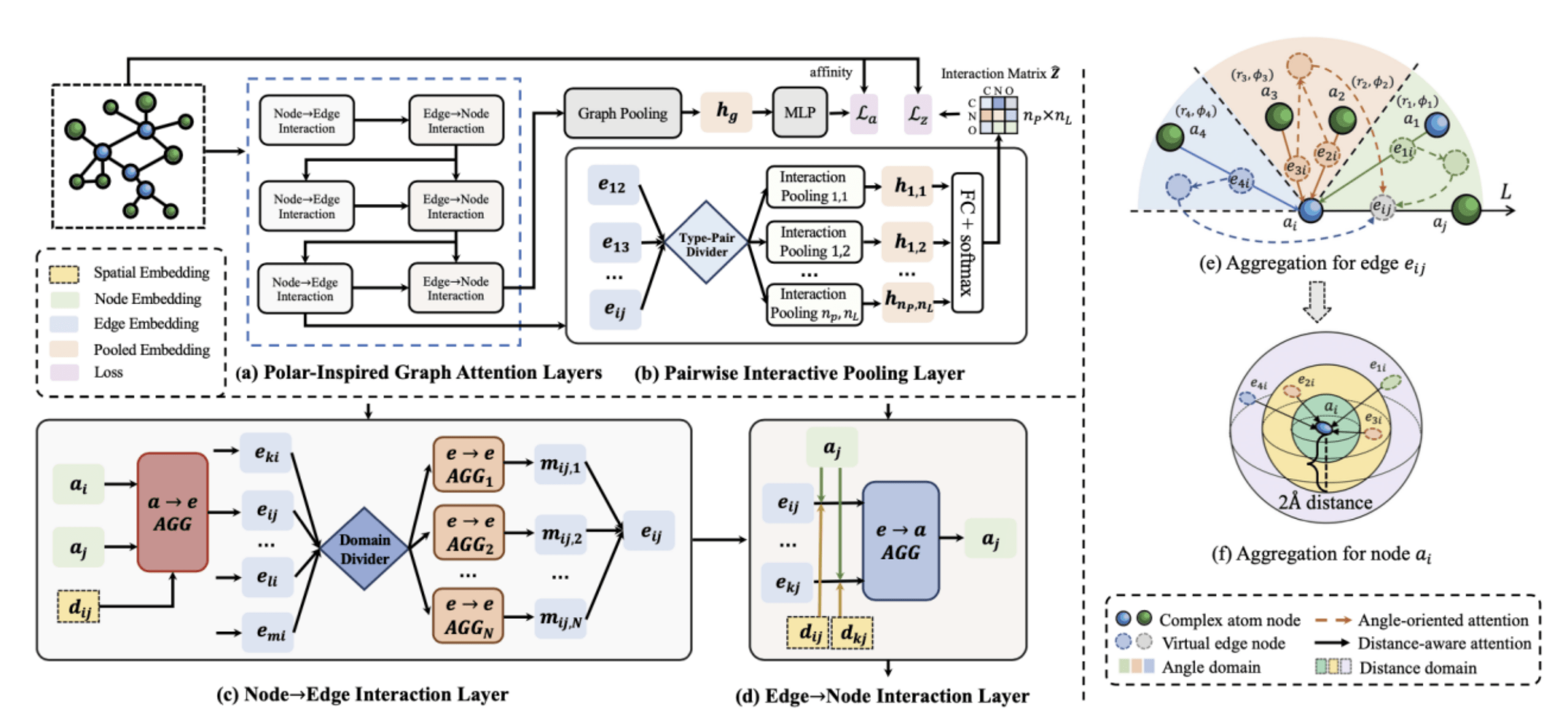
文章图片
2.基于大规模机器阅读理解的医学实体关系循证
Medical Entity Relation Verification with Large-scale Machine Reading Comprehension
论文链接:https://dl.acm.org/doi/10.1145/3447548.3467144
医学实体关系验证是构建企业级医学知识图谱的关键步骤 。 现有的信息抽取的方法专注于实体关系的挖掘 , 但并不能对挖掘的关系提供有效的循证支撑 , 这在真实医学应用场景下是不可接受的 。 因此 , 设计一种以循证为基础的医学实体关系验证框架是十分必要的 。
针对上述场景 , 我们提出了一种基于大规模机器阅读理解技术的医学实体关系循证框架 。 该框架中我们设计了多种创新性的方法和模块来提高医学实体关系循证的效率和准确率 。 比如 , 为了解决医学实体的多样性和变体问题 , 我们提出了一种近义词感知(synonym-aware)的召回模型;为了更好的利用医学的领域知识 , 我们创造性的设计了基于关系感知(relation-aware)的证据探测模块和基于医学本体增强(medical ontology-enhanced)的聚合模块 , 来共同提高整体循证模型的效果 。 此外 , 为了解决证据标签缺乏的问题 , 我们提出了一种新颖的基于交互协调训练的新方法(interactive-collaborative training)来提升标注效率 , 提升证据准确率 。 通过实验验证 , 我们提出的循证框架超越多个现有的基于事实验证的最好基线方法(state-of-the-art baselines) 。 该框架已经应用在了百度临床辅助系统(CDSS)上 , 多方位支撑CDSS产品矩阵的可解释循证 , 帮助了上万名医生 。
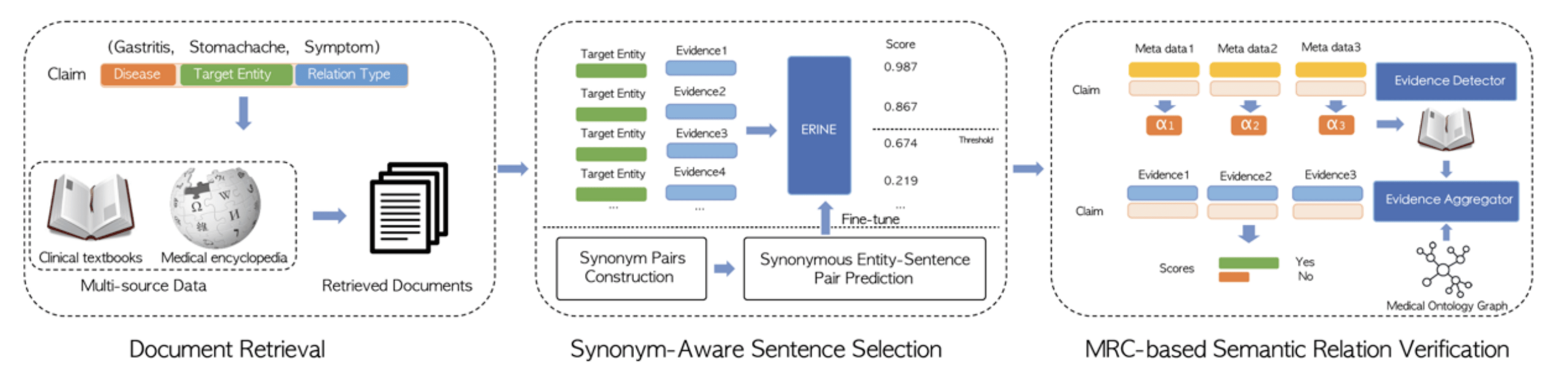
文章图片
POI检索、推荐等为用户提供更好、更便捷的智能化位置服务
作为国内智能化位置服务的代表产品之一 , 百度地图日均位置服务请求已突破了1200亿次 。
怎样让用户在使用百度地图时能够获得更好、更快、更方便的服务?KDD 2021中选论文中 , 百度延续以往在百度地图方面的技术研究、进行了升级和创新 , 覆盖POI即时检索、多语言POI检索、POI推荐和基于自监督元学习的路线耗时预估办法等 。
3.MST-PAC:基于元学习的时空个性化POI即时检索
Meta-Learned Spatial-Temporal POI Auto-Completion for the Search Engine at Baidu Maps
论文链接:https://dl.acm.org/doi/10.1145/3447548.3467058
POI即时检索(POI Auto-Completion)是百度地图POI搜索引擎的特色功能之一 。 POI即时检索旨在帮助用户以最少的输入(理想情况下只需要用户输入一个字符) , 在搜索结果列表页的首位即时给出用户想找的POI , 因此能够大幅降低输入成本并显著提升搜索效率 。 POI即时检索效果不仅与用户输入的字符以及输入习惯有关 , 也与用户发起检索的时间与空间相关 。 统计数据显示17.9%的地图用户在不同的时间或地点使用过相同的前缀寻找过不同的POI 。 考虑到时空数据分布的不均衡性 , 我们提出了一种基于元学习的时空个性化POI即时检索方法 , 并使用高效MapReduce算法对其进行训练(缩写为MST-PAC) 。 MST-PAC能够显著克服时空数据分布不均的问题 , 并能以较少的训练样本快速适应冷启动的时空场景 。 MST-PAC已在百度地图成功部署 , 每天处理数十亿检索请求 , 这表明MST-PAC是一种具有实用价值且能够大规模落地的POI即时检索工业解决方案 。
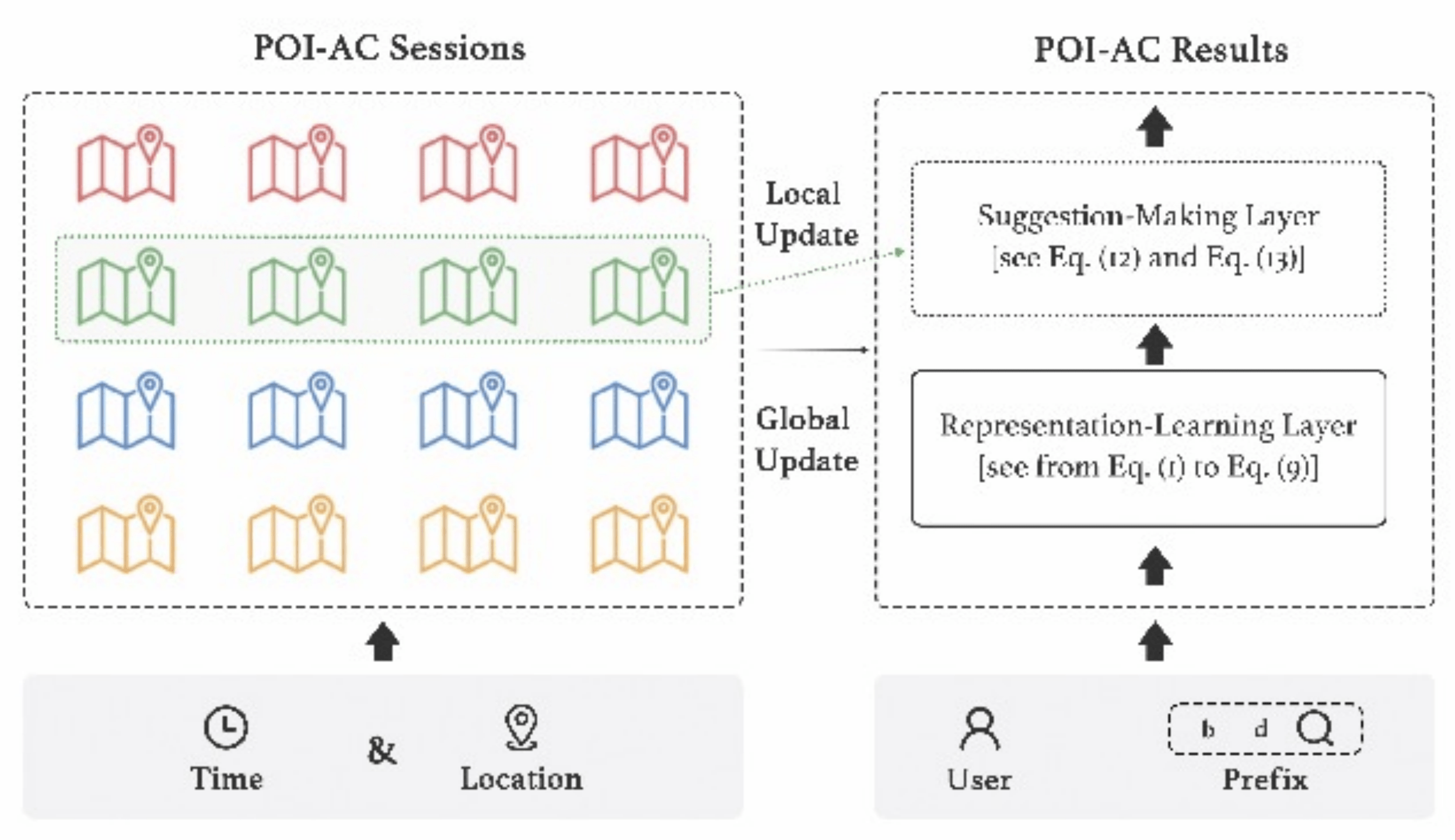
文章图片
4.基于异构图与注意力匹配网络的多语言POI检索
HGAMN: Heterogeneous Graph Attention Matching Network for Multilingual POI Retrieval at Baidu Maps
论文链接:https://dl.acm.org/doi/10.1145/3447548.3467059
多语言POI检索旨在帮助用户使用自己熟悉的语言查找到由其他语言所描述的POI 。 该功能在出境旅游时尤为重要 , 因为本地POI往往缺乏多语言翻译 , 要用完全陌生的语言进行查询对大部分用户来说不太现实 。 数据稀疏是多语言检索任务面临的挑战之一 。 为此 , 我们提出了一种基于异构图的注意力匹配网络(HGAMN) 。 首先 , 在异构图的帮助下 , 我们能够有效建立起低频POI与高频POI之间 , 以及POI与其不同语言的查询表达之间的关联 。 其次 , 我们使用基于注意力的网络对该图的节点表示进行学习后 , 能够显著缓解数据稀疏问题 。 HGAMN已在百度地图成功部署 , 每天响应数亿搜索请求 , 这表明HGAMN是一种实用且鲁棒的多语言POI检索工业解决方案 。
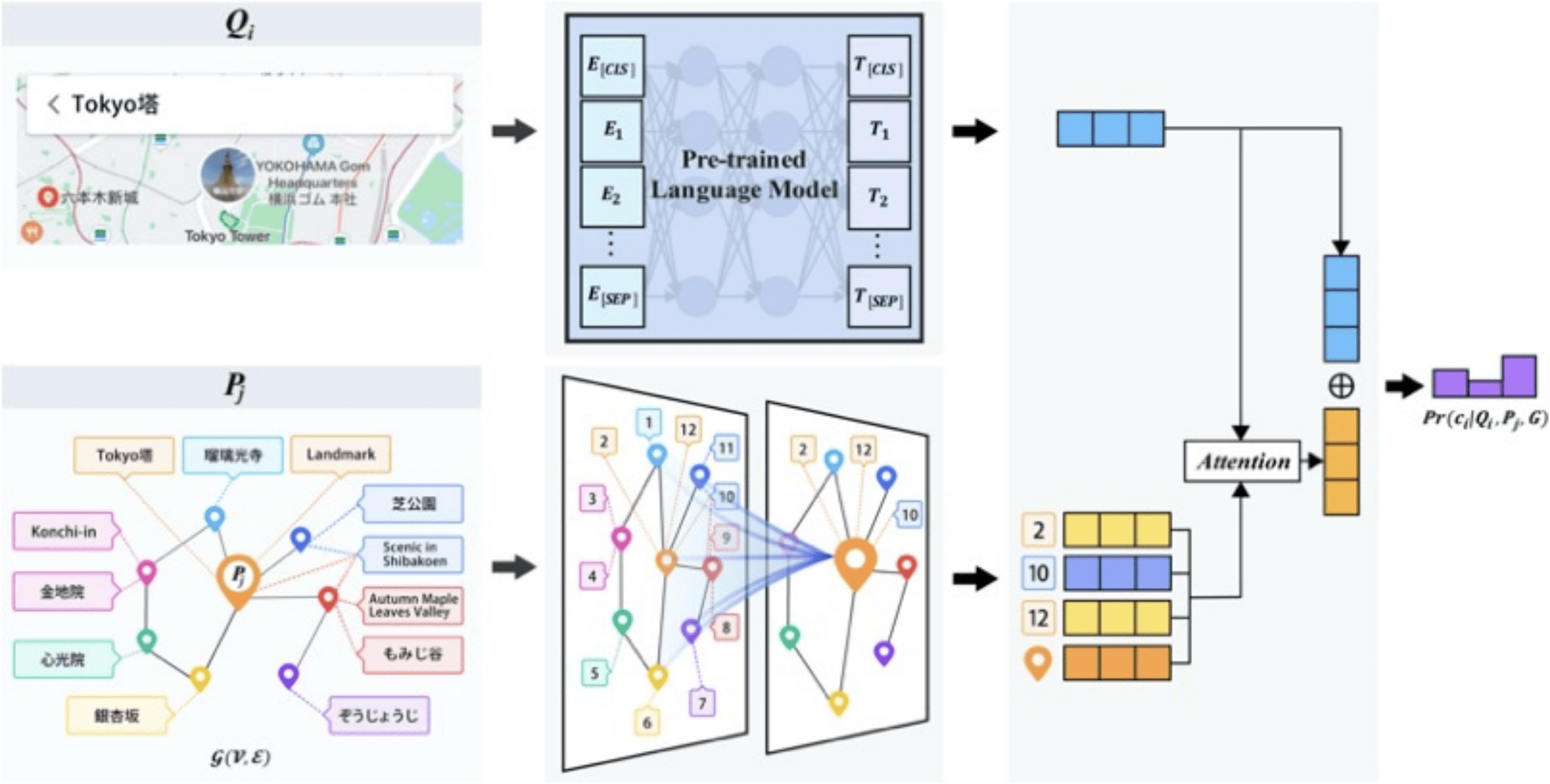
文章图片
5.SSML: 基于自监督元学习的在途路线耗时预估方法
SSML: Self-Supervised Meta-Learner for En Route Travel Time Estimation at Baidu Maps
论文链接:https://dl.acm.org/doi/10.1145/3447548.3467060
路线耗时预估旨在根据路线和出发时间预测用户的到达时间 , 是地图产品必不可少的基础功能之一 。 在途路线耗时预估是路线耗时预估在用户驾驶过程中的细分场景任务 , 旨在估算出从用户当前位置到目的地的剩余时间 。 然而 , 现有方法未考虑从起点到当前位置的用户驾驶行为 , 从而很难快速适应用户的驾驶习惯 , 并据此及时调整剩余的预估耗时 。 为此 , 本文提出利用已行驶路线所观察到的少量用户驾驶行为 , 来提升在途路线耗时预估的准确率 。 我们将该任务建模为一个小样本学习问题 , 把已行驶路线中观察到的用户行为作为训练样本 , 同时把剩余路线中未发生的行为作为测试样本 。 我们提出了一种基于自监督元学习的在途路线耗时预估方法(SSML) , 并使用自监督学习进行数据增强 , 从而得以快速适应用户的驾驶行为、提升模型的预测效果 。 基于百度地图大规模真实数据集的实验表明 , SSML是一种具有实用价值与稳健性的在途路线耗时预估工业解决方案 。
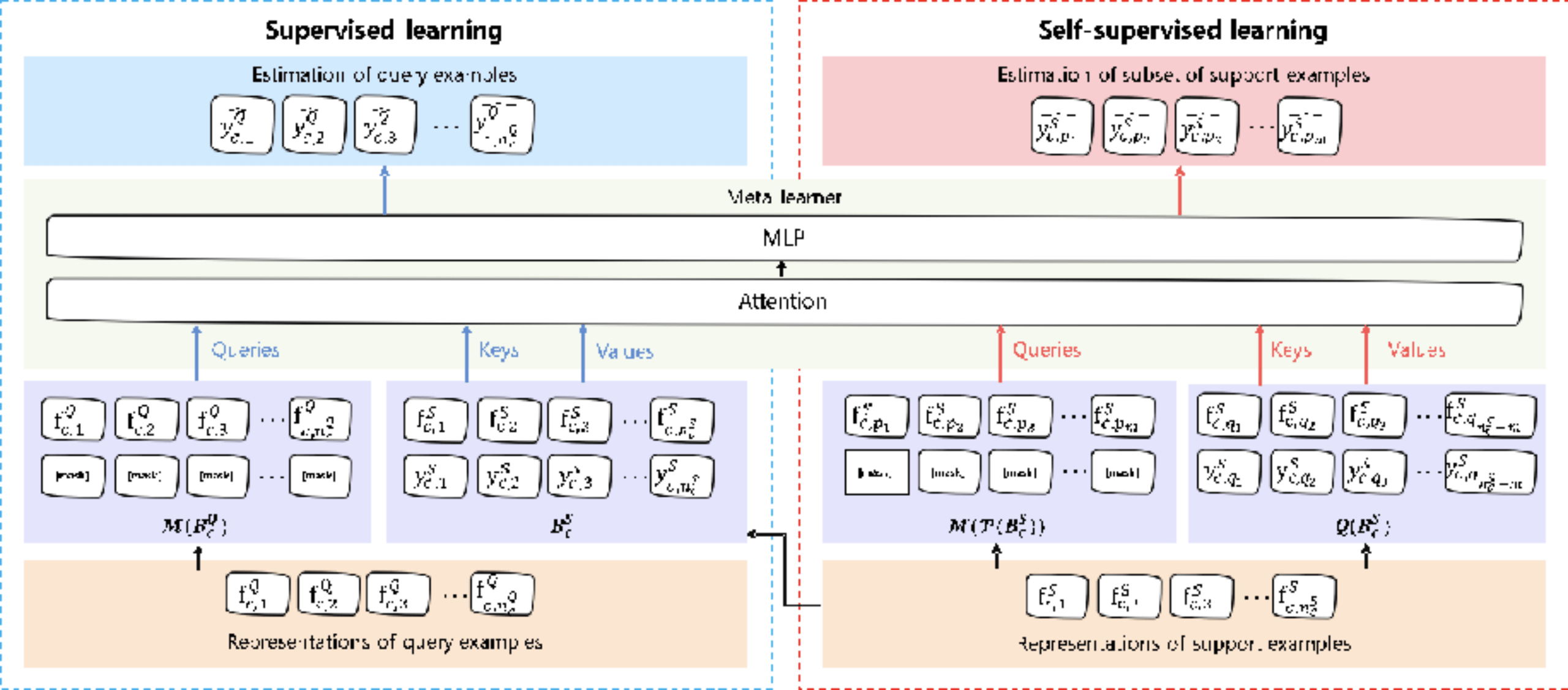
文章图片
6.CHAML:基于课程式元学习框架的POI推荐技术
Curriculum Meta-Learning for Next POI Recommendation
论文链接:https://dl.acm.org/doi/10.1145/3447548.3467132
POI推荐 , 作为广受用户欢迎的POI发现方式 , 是百度地图的特色功能之一 。 该功能旨在结合当前的时空场景和用户使用习惯 , 快速发现其潜在感兴趣的POI 。 但是 , 由于『用户-POI』交互的天然长尾效应 , 现有技术很难为数据稀疏的冷启动城市提供令人满意的POI推荐 。 本文提出了一种将隐藏在丰富数据中的知识从热门城市迁移到冷启动城市的构想 。 为了达成这一构想 , 我们设计了一种新的课程式元学习(CHAML)框架 。 CHAML框架能够分别从城市和用户两个层面 , 考虑样本的训练难度 , 并以此来增强元学习训练过程 。 同时 , 我们设计了一种由易到难的课程式学习方案 , 用于样本抽样 , 以帮助元学习模型收敛到更好的状态 。 目前 , CHAML已经用于百度地图的POI推荐业务 , 并且取得显著的应用效果 。
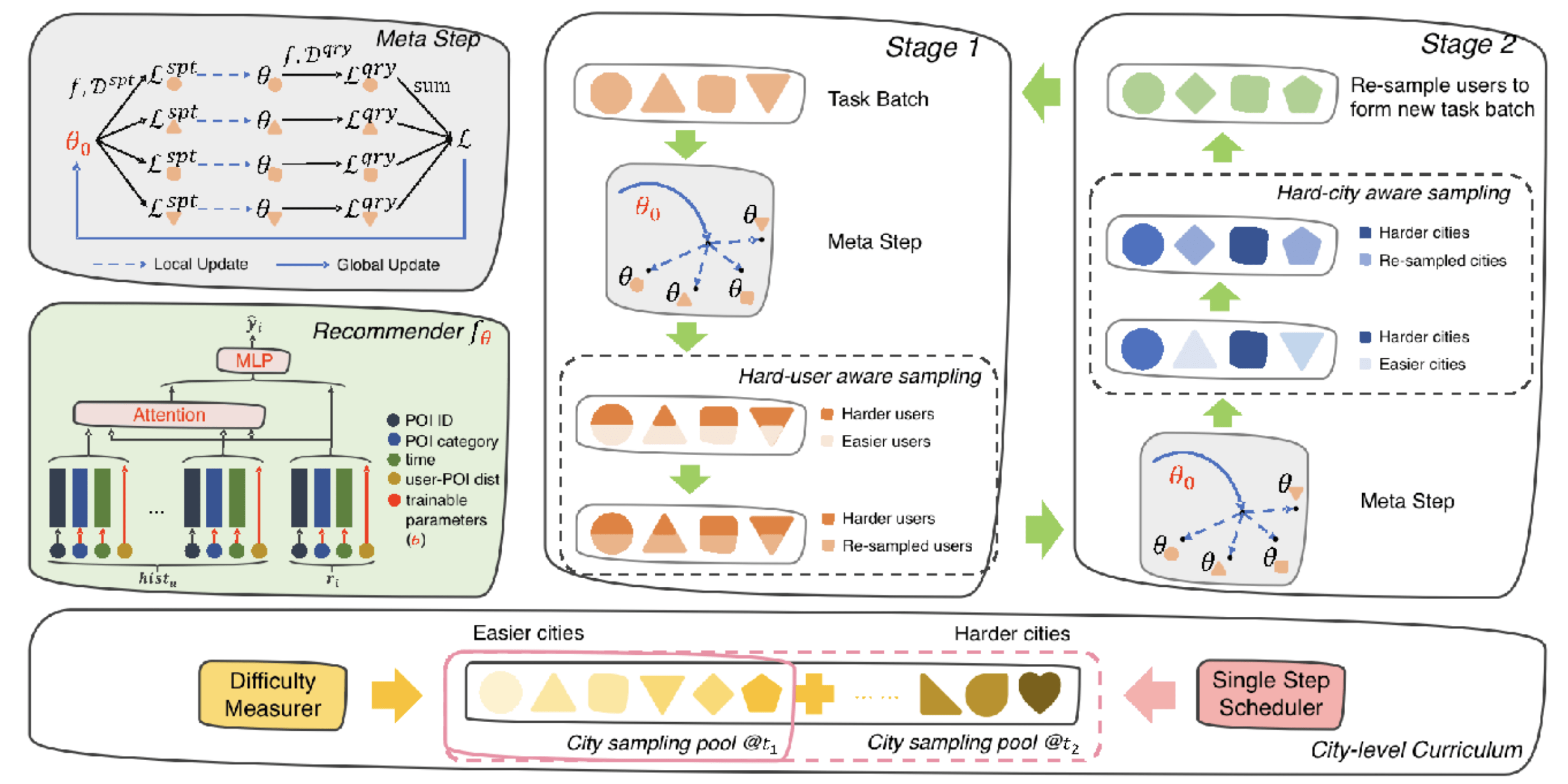
文章图片
新技术助力百度搜索引擎性能与效果提升
如何进一步优化提升百度搜索引擎的体验和效率 , 是百度技术人员一直关注的问题 。 此次KDD 2021百度中选论文中 , 有数篇围绕百度搜索引擎性能效果提升探讨了最新技术研究成果 , 包含使用百度先进的中文预训练语言模型文心(ERNIE) , 快速近邻检索(ANN)和快速最大内积检索(MIPS) , 高效智能在线推理系统JiZhi(极智)等 。
7.基于预训练语言模型的百度搜索排序
Pre-trained Language Model based Ranking in Baidu Search
论文链接:https://dl.acm.org/doi/10.1145/3447548.3467147
排序作为搜索的核心 , 在满足用户的信息需求方面起着至关重要的作用 。 近来 , 基于预训练语言模型 (PLM) 的微调方法取得了当前最好的效果 。 然而 , 在大规模搜索引擎中应用基于PLM的排序模型却并不容易:1. PLM的计算成本过高 , 尤其是对于排序中的长文本 , 限制了他们在低延时系统中的部署;2. 现有的预训练目标与相关性无关 , 直接应用相关性无关的PLM模型 , 是限制基于PLM的排序模型的另一个主要障碍;3. 现有的排序模型需要和其他排序模型共同应用 , 因此模型与其他模型的兼容性对于一个排序系统来说也至关重要 。
在本工作中 , 我们提出了一系列如何成功部署最先进的中文预训练语言模型(ERNIE)的技术 。 首先 , 我们阐明了如何高效地抽取文档的摘要 , 并提出了能强大的Pyramid-ERNIE 架构将查询、标题和摘要三者建模 。 然后 , 我们提出了一个范式来精细地利用大规模的有噪声和偏见的点击后行为数据进行面向相关性的预训练 。 其次 , 我们还提出了一种为在线排名系统量身定制的人工锚定微调策略 , 旨在保证基于PLM的排序模型和其他模块的兼容性 。 最后 , 大量的离线和在线实验结果表明 , 所提出的方法可以显着提高了搜索引擎的性能 。
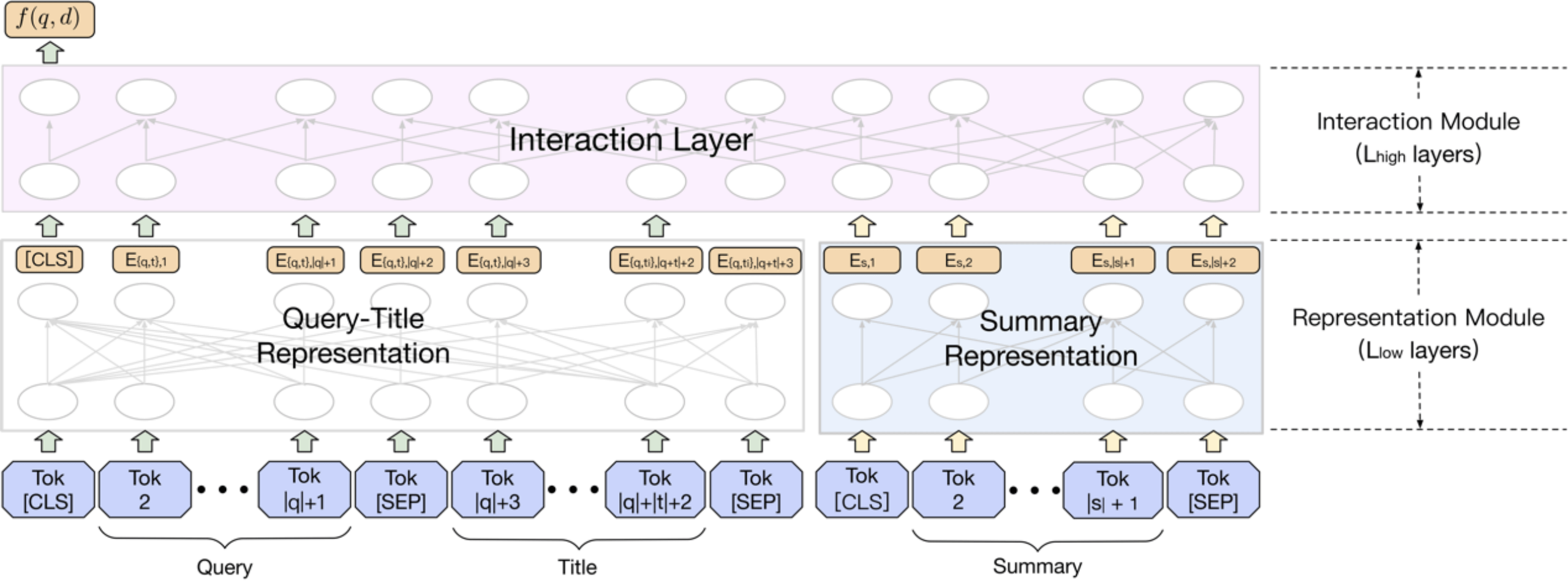
文章图片
8.预训练语言模型在百度大规模网页召回中的应用
Pre-trained Language Model for Web-scale Retrieval in Baidu Search
论文链接:https://dl.acm.org/doi/10.1145/3447548.3467149
召回是网页搜索中的重要阶段 , 其功能在于从海量网页库中找到一个相对较小的相关候选集 。 其中 , 基于语义相关的召回有助于展现更多高质量的搜索结果给用户 。 但是 , 搭建和部署一个高效的语义召回模型 , 在搜索引擎业务中一直面临着诸多挑战 。 本文介绍了目前百度搜索中所使用的基于预训练语言模型的召回系统 。 此系统采用了百度自研的中文预训练语言ERNIE , 通过应用基于多层Transformer的模型结构 , 以及多阶段的训练流程 , 赋予了召回系统强大的语义匹配能力 。 同时 , 本文还介绍了基于预训练的召回模型在整个召回系统中的工作流程 。 通过严谨的离线和线上实验验证 , 基于预训练语言模型的召回系统已全量部署在百度搜索业务中 , 提升了百度搜索的整体效果 。

文章图片
9.基于模调节近邻图的最大内积检索
Norm Adjusted Proximity Graph for Fast Inner Product Retrieval
论文链接:https://dl.acm.org/doi/10.1145/3447548.3467412
快速近邻检索(ANN)和快速最大内积检索(MIPS)是工业界超大规模排序系统的核心 , 在搜索引擎公司的各项主要业务中发挥了巨大作用 。 有关ANN和MIPS的各项前沿研究在百度已经有了很长的历史 。 从2019年开始 , 通过学术论文百度逐步而系统地对外公开了自主开发的各项ANN和MIPS核心技术 。 这篇KDD 2021论文就是其中之一 。
最大内积检索(MIPS)旨在快速查找与检索向量(Query)内积最大的候选向量 , 原本是学术界和工业界的一个重大难题 。 最大内积检索之所以具有挑战是因为内积不符合三角关系 , 即内积不是度量标准(Metric Measure) 。 传统的快速向量检索技术多为Metric Measure所设计 , 如欧式距离和余弦距离 。 这些传统方法并不适用于最大内积检索 。 比如针对Metric Measure效果非常好的图索引方法就不能直接应用到最大内积检索中 。 在本文中我们提出模调节图索引结构 , 将针对Metric Measure的图索引结构扩展到最大内积检索任务中 。 大量实验表明 , 该方法相比于之前有代表性的内积检索方法 , 有很大的性能优势 。 我们提出的方法NAPG相比于之前有代表性的MIPS方法ip-NSW , Greedy-MIPS和Rang-LSH , 在检索性能上有巨大优势 。 在同等召回率水平上 , 该方法可以处理的查询数远多于其他方法 。
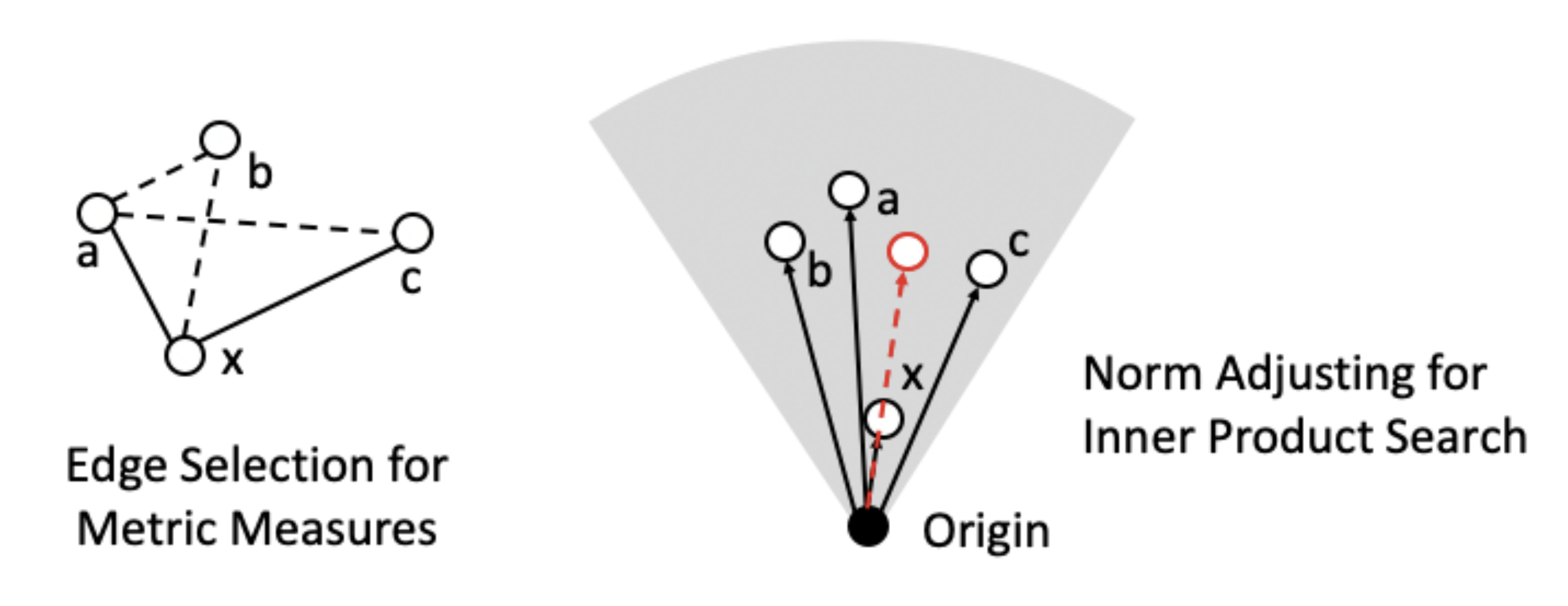
文章图片
10.JIZHI:百度面向网络应用的实时高效模型预估系统
JIZHI: A Fast and Cost-Effective Model-As-A-Service System for Web-Scale Online Inference at Baidu
论文链接:https://dl.acm.org/doi/10.1145/3447548.3467146
对于来自数亿级用户的巨量预估请求 , 如何能够以超低成本支撑起超大规模离散稀疏深度模型进行高效的实时在线推理仍然具有极大挑战性 。 在本文中 , 我们构建了一套高效智能在线推理系统JiZhi(极智) , 将每个请求的推理过程转换为一个阶段式的事件驱动处理流(SEDP) , 创新性的以全局最优视角自适应精细化调整各个阶段最合理的架构算法和参数 , 动态调度模型预估算力的分配 , 更加智能通用的适应各种预估应用场景 。 通过多层次自适应缓存机制 , 大幅减少了由超大规模稀疏模型参数引起的计算成本和数据访问延迟 , 进一步加速在线推理过程 。 此外 , JiZhi还实现了智能资源管理机制 , 从系统运行期历史中学习最佳的资源分配计划 , 调整负载控制策略 , 最大限度的提高JIZHI的系统吞吐 。 JIZHI已在百度20多个业务场景落地 , 从端到端的实现成本、服务延迟、系统吞吐量、资源消耗等角度展现出了JIZHI系统显著的优势 , 在保障模型效果的前提下节省了大量的实现、硬件和基础设施的应用成本 。
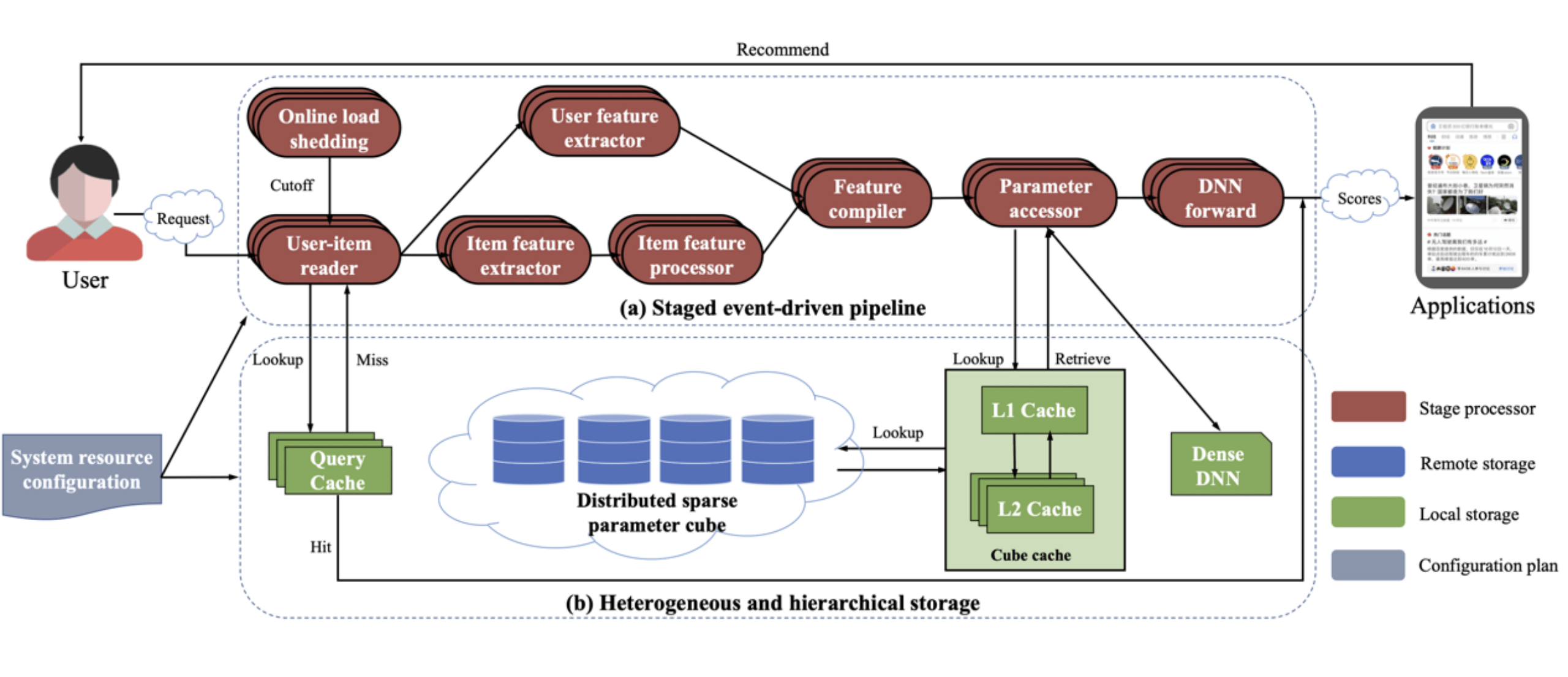
文章图片
AI+房地产评估:从地理分布、人口流动性分布、居民人口学分布等多个角度构建丰富的特征集 , 以对房地产价值进行全面综合的剖析 。
11.MugRep:一种面向房地产评估的多任务层次图表示学习框架
MugRep: A Multi-Task Hierarchical Graph Representation Learning Framework for Real Estate Appraisal
论文链接:https://dl.acm.org/doi/10.1145/3447548.3467187
房地产评估是指对房地产的市场价值进行公正评价的过程 , 其对房地产市场的各种参与者(如房地产经纪人、估价师、贷款人和买家)的决策过程起着至关重要的作用 。 然而 , 要做到准确的对房地产进行评估并不容易 , 将主要面临三个方面的挑战:(1) 房地产价值复杂的影响因素;(2) 房地产交易间的异步时空依赖;(3) 城市居民社区间的多元相关性 。 针对以上几大挑战 , 本文提出了一种多任务层次图表示学习框架(MugRep) , 用来准确的评估房地产 。 具体来说 , 通过获取和整合多源城市数据 , 本文首先从地理分布、人口流动性分布、居民人口学分布等多个角度构建丰富的特征集 , 以对房地产价值进行全面综合的剖析 。 然后 , 我们提出了一种演化的房地产交易事件图卷积模块 , 以融合房地产交易之间的异步时空依赖 。 此外 , 为了进一步从居民社区的视角提取有价值的知识 , 我们设计了一种分层异构的社区图卷积模块 , 以捕获居民社区之间的多元相关性 。 最后 , 我们引入以城区作为划分的多任务学习模块 , 以生成不同分布的房地产评估意见 。 我们在两个真实数据集上进行了大量的实验 , 结果证明了MugRep及其组件和特性的有效性 。
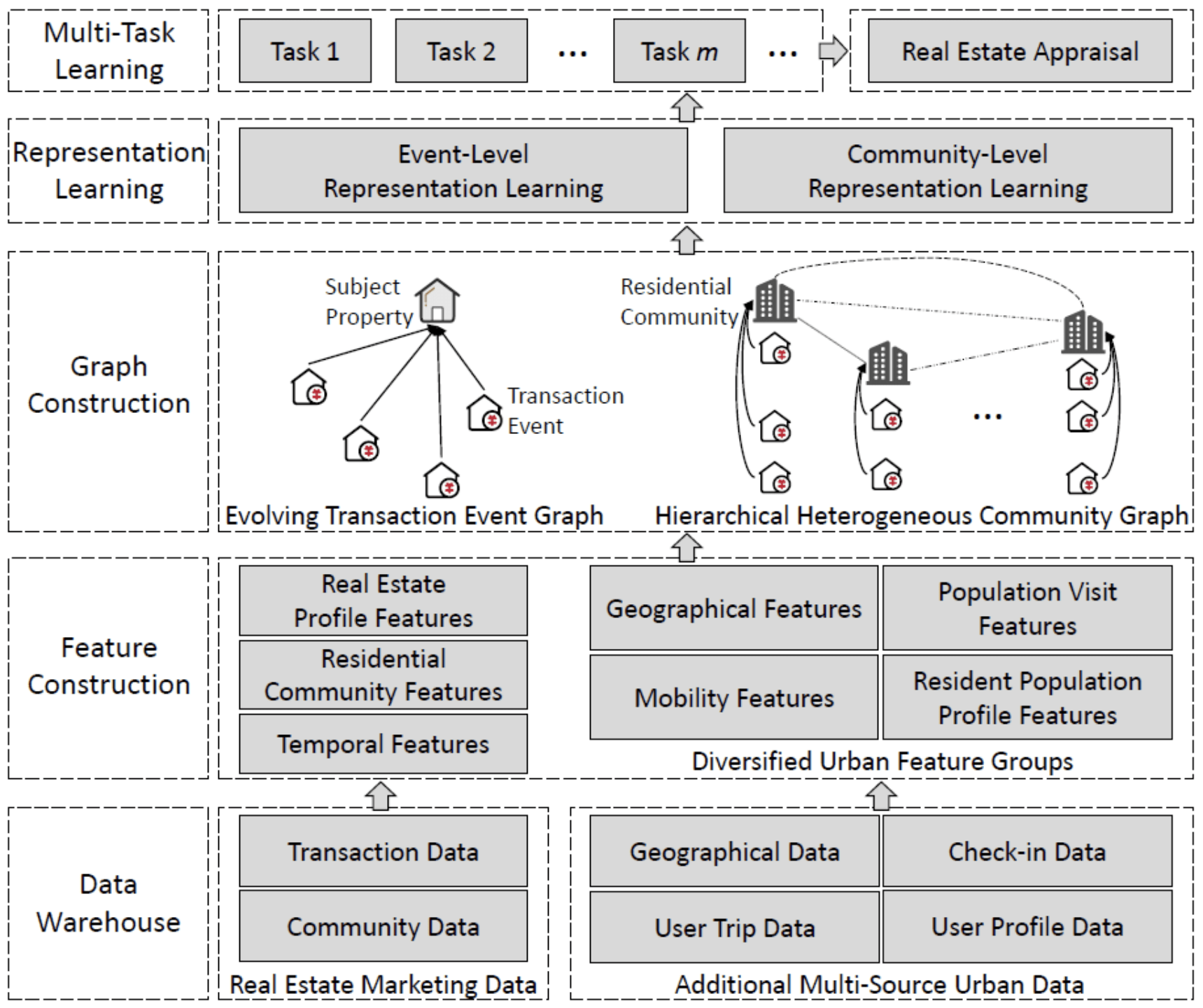
文章图片
AI+人才管理:聚焦新领域的创新突破
一直以来 , 百度在“AI+人才管理”方面也实现了深厚的技术研究积累 , 今年年初就有相关研究成果登上国际顶级刊物Nature子刊Nature Communications 。 在KDD 2021的被录取论文中 , 百度相关研究团队展现了在工作流动行为预测、人才需求预测等方面的最新研究成果 。
12.基于异构图注意力表征的工作流动行为预测
Attentive Heterogeneous Graph Embedding for Job Mobility Prediction
论文链接:https://dl.acm.org/doi/10.1145/3447548.3467388
在当今人才经济时代 , 跳槽频繁现象已经成为新常态 。 因此 , 对工作流动预测的研究应运而生 , 它能使组织和个人在多个方面获益 。 本文聚焦在工作流动预测任务 , 现有研究主要集中在对个体层面的职业轨迹建模 , 而很大程度上忽略在宏观层面上职业流动的影响(例如 , 在公司与公司或岗位与岗位之间的人才流动) 。 实际上 , 这种宏观层面上的职业流动信息能够反映出人才市场的趋势 , 对个人的跳槽决定会产生一定影响 。 为此 , 本文提出一种建模宏观层面职业流动行为影响来辅助预测个体层面的工作流动框架(Ahead) 。 首先 , 从观测到的职业轨迹链中构造异质企业-岗位网络来保留宏观层面的职业流动信息 。 其次 , 本文构建了AHGN模块从异质图中获取岗位和企业丰富的语义表征 。 其中提出了两种聚合器 , 分别用来聚合内部和外部邻居的信息 , 以及一种新颖的类型注意机制被用来融合两种聚合器的信息以更新节点表示 。 最后在公开互联网数据集上的实验结果从多个角度证明了本文方法的有效性 。
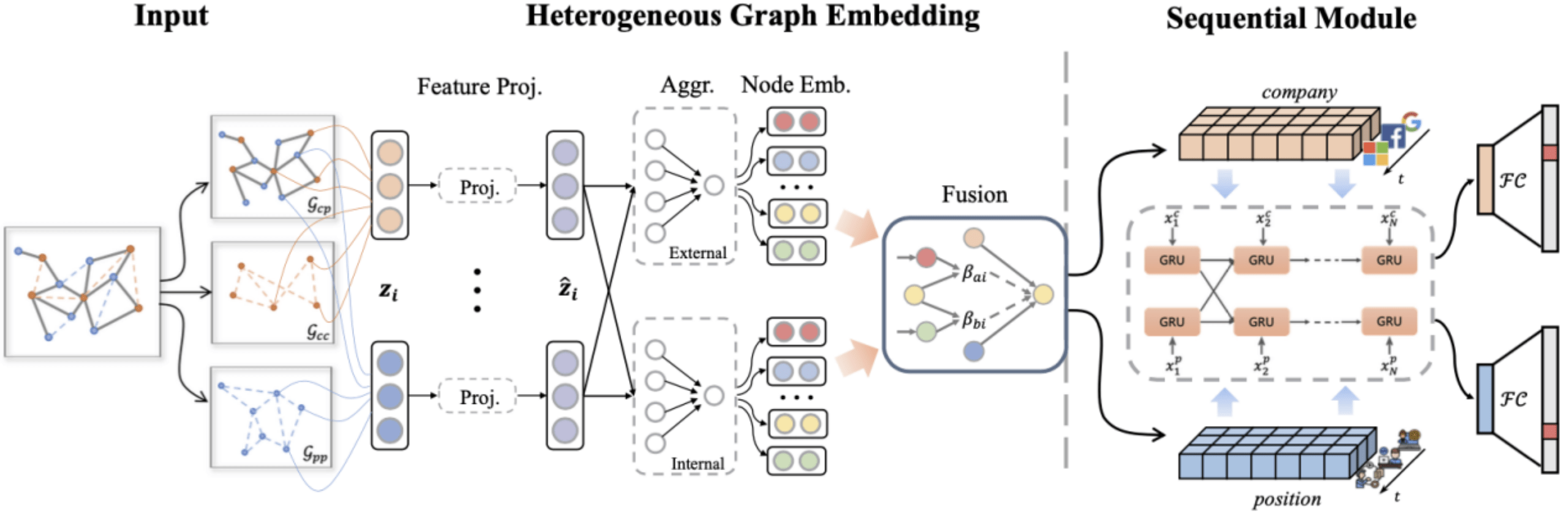
文章图片
13.基于注意力序列模型的人才需求预测
Talent Demand Forecasting with Attentive NeuralSequential Model
论文链接:https://dl.acm.org/doi/10.1145/3447548.3467131
【模型|KDD 2021之百度:学术研究与技术应用相结合】人才需求预测(Talent Demand Forecasting)技术是指根据公开互联网数据对未来公司的人才招聘需求进行预测的技术 。 在当今瞬息万变的商业环境中 , 根据公开数据及时预测各个企业在招聘市场中的人才需求趋势 , 不仅可以帮助企业指定合适的人才斩落 , 保持自身人才竞争力 , 还可以帮助政府从宏观角度对人力市场的供需关系进行分析 。 虽然已有很多在招聘市场分析方面的工作 , 但由于细粒度人才需求时间序列的稀疏性和招聘市场复杂的时序模式 , 仍然没有有效的方法可以预测细粒度的人才需求动态 。 为此 , 在本文中 , 我们提出了一种数据驱动的注意力序列模型 , 即人才需求注意力网络(TDAN) , 用于预测公开市场中的细粒度人才需求 。 我们首提取多个粒度级别上人才需求的时间序列 , 并使用矩阵分解技术提取公司和职位的内在属性 。 然后 , 我们设计了一种混合注意力模块来捕捉公司的趋势和行业的趋势 , 用以增强细粒度人才需求的信息 。 接着设计了一个相关性注意力时序模块 , 用于对随公司和职位变化的复杂的时间相关性进行建模 。 最后 , 在大规模公开互联网数据集上进行了大量实验 , 结果验证了所提方法在细粒度人才需求预测方面的有效性 , 展示了其对招聘趋势建模的可解释性 。
推荐阅读







- Google|谷歌暂缓2021年12月更新推送 调查Pixel 6遇到的掉线断连问题
- 精度|将建模速率提升10倍,消费级3D扫描仪Magic Swift在2021高交会大显“身手”
- 四平|智慧城市“奥斯卡”揭晓!祝贺柯桥客户荣获2021世界智慧城市治理大奖
- 系列|2021中国航天发射圆满收官!年发射55次居世界第一
- 项目|常德市二中2021青少年科技创新大赛再获佳绩
- 选型|数据架构选型必读:2021上半年数据库产品技术解析
- 殊荣|蝉联殊荣!数梦工场荣获DAMA2021数据治理三项大奖
- 公司|外媒:2021,人类太空事业的重大年份
- 语境|B站2021个人年度报告发布:你共计看了多少个视频
- 最新消息|IT系统出错 英国银行给7.5万人多发11亿工资