
文章图片
对模型进行训练以使误差单元活动的加权和最小 。 训练损失为:
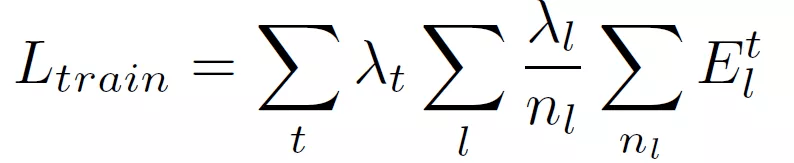
文章图片
对于由减法和 ReLU 激活组成的误差单元 , 每层的损失相当于 L1 误差 。 虽然本文没有针对此问题进行探讨 , 但作者表示也可以使用其他误差单元实现 , 甚至可能是概率的或对抗性的 。 完整的流程如下:

文章图片
状态更新通过两个过程进行:一个自上而下的过程 , 其中计算(R_l)^t 状态 , 然后一个向前的过程 , 以计算预测、误差和更高级别的目标 。 最后一个值得注意的细节是 R_l 和 E_l 被初始化为零 , 这是由于网络的卷积性质 , 意味着初始预测在空间上是一致的 。
3.2 PredNet 的预测编码分析
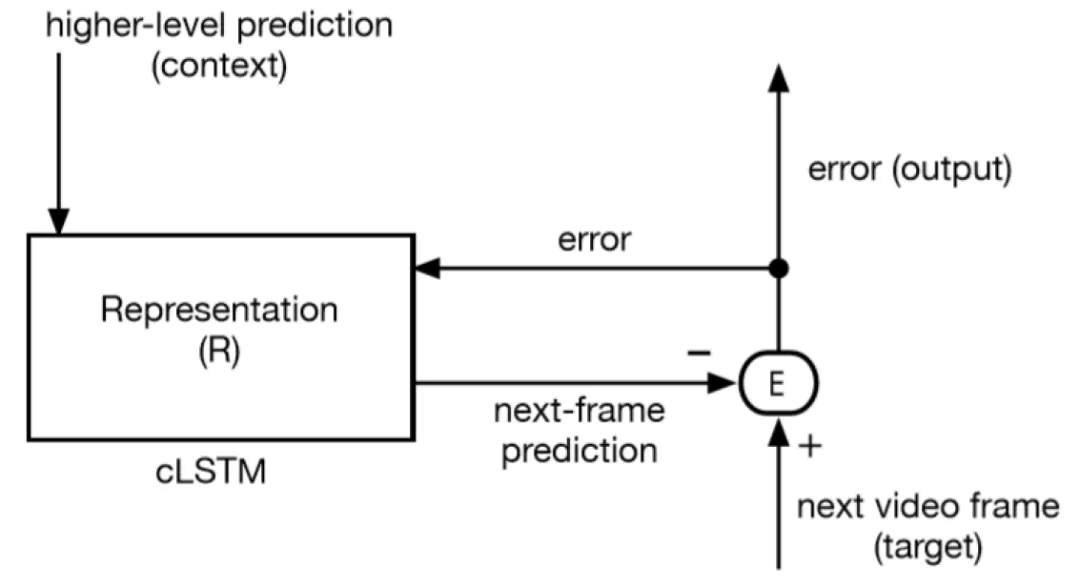
本小节介绍 PredNet 的图形化展示[1] 。 图 5 示出了模型最下层的 PredNet 预测元素(PE) , 其中左侧的表示模块实现为 cLSTM(convolutional LSTMs , 卷积 LSTM) 。 由于 PredNet 处理视频数据 , 因此该模型中的表示模块由卷积 LSTM(cLSTMs)组成 。 cLSTM 是对 LSTM 的一种修改 , 它使用多通道图像作为其内部数据结构来代替特征向量 。 cLSTM 将基于仿射权乘(用于常规 LSTM)的门操作替换为适用于多通道图像的卷积门操作 , 以生成图像序列(如视频)的有用表示 。 表示模块的输出投射到误差计算模块 , 该模块将其输出发送回表示模块 。 该模型通过将预测结果与目标帧进行比较 , 并使用预测误差作为代价函数 , 来学习预测视频(目标)中的下一帧 。 由于图 5 没有显示前馈和反馈连接如何链接到下一个更上层 , 我们无法确定它是否是预测预测误差的模型 。 在这一点上 , 它作为预测编码模型是通用的 。
文章图片
图 5. PredNet 最下层(训练模式)中的信息流 , 其中输入为真实视频帧 , R 和 E 是循环连接的
PredNet 与早期预测编码模型之间的根本区别在于 PredNet 中的模块间连接性与之前研究的模型不同 。 具体而言 , PredNet 不遵循 RB 协议 。 这在图 5 中不容易看出 , 但在图 6(a)中很明显 , 图 6(a)给出了 PredNet 模型的两层版本 , 模块互连模式不同于 RB 协议 。 例如 , PredNet 中第二层表示投影到第一层表示 , 而如果使用 RB 协议 , 它将投影到第一层误差 。 类似地 , 如果使用 RB 协议 , 第一层应投影到第二层表示 。 相反 , PredNet 投影到了第二层误差 。
下图6为PredNet 的两个视图 。
推荐阅读







- MateBook|深度解析:华为MateBook X Pro 2022的七大独家创新技术
- 人物|最有深度的8个公众号,你关注了吗
- 国际|特奖得主任队长,清华夺冠NeurIPS 2021国际深度元学习挑战赛
- 人物|说到做到 俞敏洪首场带货直播卖啥?
- 深度|小米真无线降噪耳机 3 Pro 新年特别版即将发布,带来全新配色等
- 语音|声控智能家居控制系统,就是人与机器的深度交流
- 系列|小米 12 系列确认搭载骁龙 8 Gen 1,已经进行深度调教
- 空间|深度阅读|王赤:从孤独里找到一束光
- 深度|2021百度奖学金十强出炉:已累计投入2000万培养中国顶尖AI人才
- 巨头|国泰君安:折叠屏手机加速渗透 供应链深度受益