文章图片
(a)
文章图片
(b)
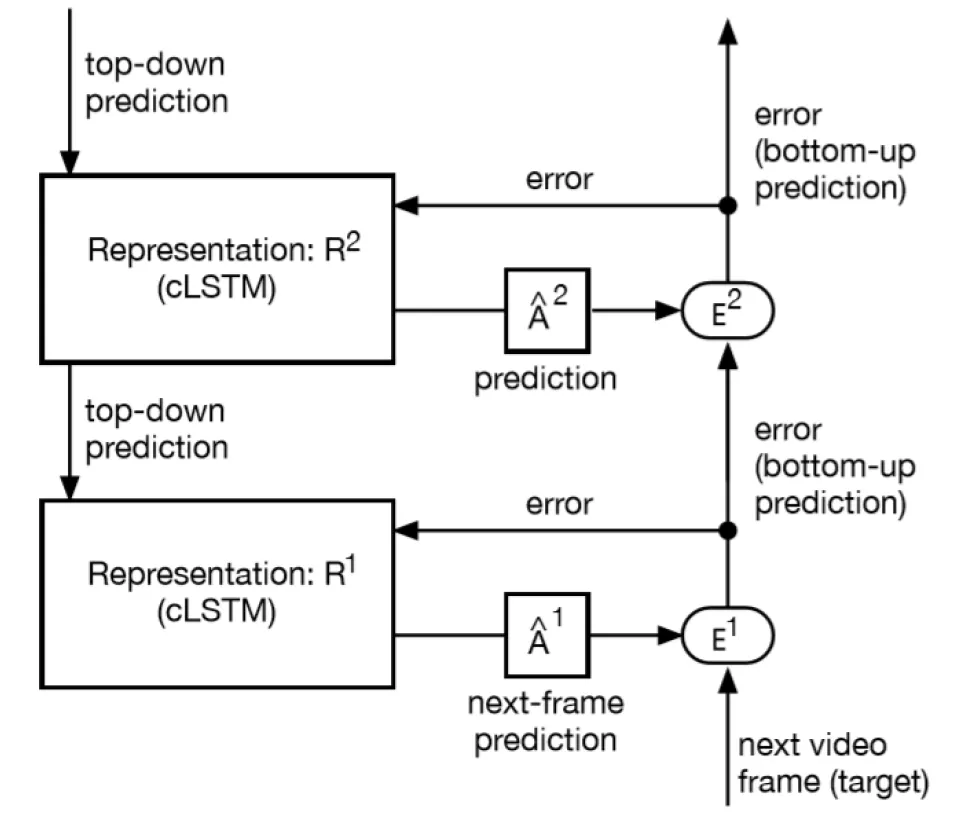
图6.PredNet的两个视图 。 (a) 简单的文字表述 。 (b) 重构图
我们可以通过图 6 具体分析 PredNet 的工作方法 。 当使用 L0 训练损失时 , 误差值 e2 不是训练损失函数的一部分 , 因此在第 2 层的表示中学习仅减少损失 e1 。 此外 , 两层的架构表示减少了高阶误差 , 但 L0 损失函数与此相反 。 因为 e2 并不影响训练 。 来自 e2 的反向传播权重更新信息沿箭头指向的相反方向流动 。
假设:如果我们切断标记为 “1” 的连接 , 它对性能的影响应该可以忽略不计 。 如果这一假设被证明是正确的 , 那么更高级别的预测误差计算不会起到显著作用 。 Hosseini M 和 Maida A 认为 , 这意味着 PredNet 模型并非真正的预测编码网络 , 其功能原理类似于传统的深度网络 。 具体而言 , 它是一个分层 cLSTM 网络 , 在最下层使用平方误差损失之和[1] 。 虽然图 6 中没有明确显示 , 但在连续层之间的上行链路上使用了池化 , 在下行链路上使用了上采样 。 这实现了某种形式的分层空间上下文 , 但由于它将预测误差作为更上层次的表征 , 所以很难进行启发式解释 。
4、利用 RB 协议对 PredNet 改进的思考[1]
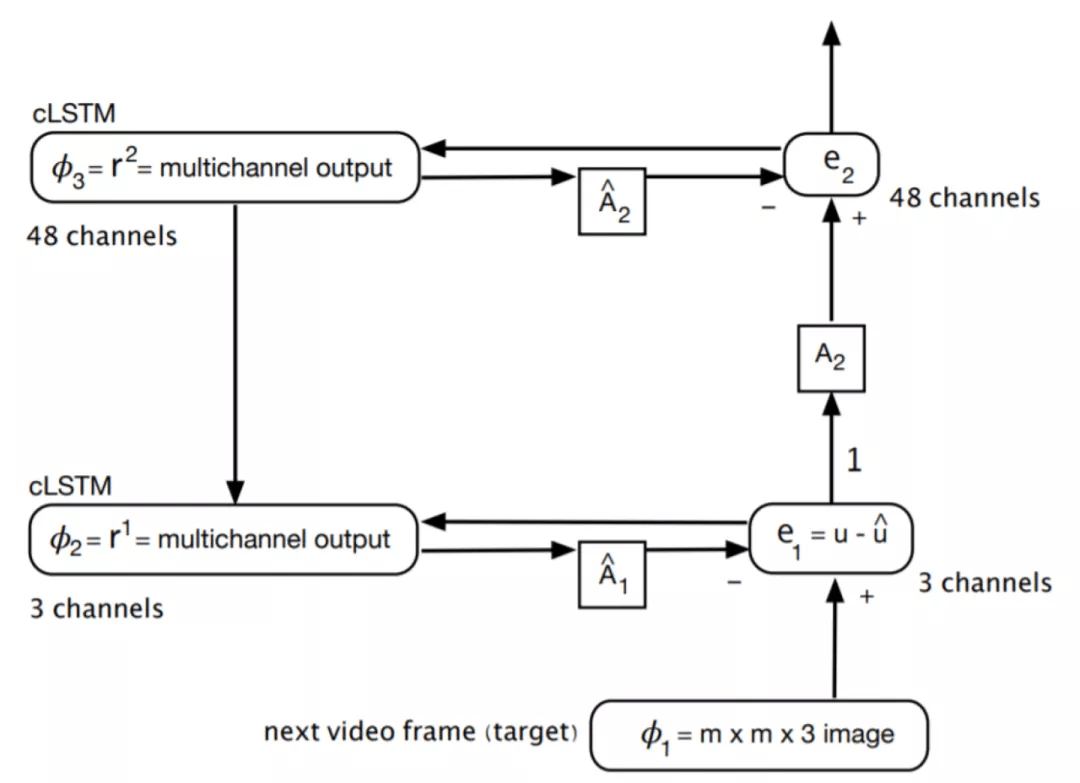
通过上文的介绍我们可以看出 , PredNet 是第一个深度学习架构中的预测编码 , 但是它并不遵循 RB 协议 。 Hosseini M 和 Maida A 在 文献 [1] 中提出了一种利用 RB 协议改进 PredNet 的方法 , 命名为 RBP 模型(RB-PredNet) , 如图 7 所示 。 所有可训练参数都在 A^l、(A^l)^ 和 R^l 模块中 。 所有三种模块类型都执行多通道 2D 卷积运算 。 A^l 和(A^l)^ 模块使用一种操作 , 而 R^l 模块实现的是 cLSTM , 因此一共使用了四组相同的操作 。 如果输出通道数为 oc , 则需要 oc 多通道卷积来计算此输出 , 这是卷积集的大小 。 cLSTM 有三个门操作和一个输入更新操作 , 每个操作计算一个多通道卷积集 。 除了内核中的权重值外 , 这些集合是相同的 。 R^l 模块的输入通道数(表示为 ic)是前馈、横向和反馈输入的总和 。 所有卷积运算都使用平方滤波器 , 其内核大小在一维上由 k=3 表示 。 考虑到这些因素 , 下面的公式给出了一组多通道卷积的参数计数 , 称为卷积集:
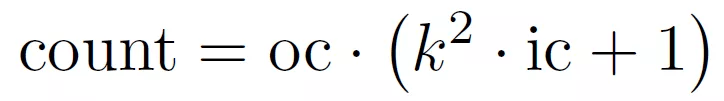
文章图片
其中 , 括号中给出了多通道卷积滤波器的权重数 。 每个过滤器都有一个偏差 。 对于每个输出通道 , 需要一个多通道卷积 。 表 1 给出了图 7 中模型的参数计算量 , 该模型共有 65799 个可训练权重 。
推荐阅读







- MateBook|深度解析:华为MateBook X Pro 2022的七大独家创新技术
- 人物|最有深度的8个公众号,你关注了吗
- 国际|特奖得主任队长,清华夺冠NeurIPS 2021国际深度元学习挑战赛
- 人物|说到做到 俞敏洪首场带货直播卖啥?
- 深度|小米真无线降噪耳机 3 Pro 新年特别版即将发布,带来全新配色等
- 语音|声控智能家居控制系统,就是人与机器的深度交流
- 系列|小米 12 系列确认搭载骁龙 8 Gen 1,已经进行深度调教
- 空间|深度阅读|王赤:从孤独里找到一束光
- 深度|2021百度奖学金十强出炉:已累计投入2000万培养中国顶尖AI人才
- 巨头|国泰君安:折叠屏手机加速渗透 供应链深度受益